
挑战Transformer,华为诺亚新架构盘古π来了,已有1B、7B模型
挑战Transformer,华为诺亚新架构盘古π来了,已有1B、7B模型近日,来自华为诺亚方舟实验室、北京大学等机构的研究者提出了盘古 π 的网络架构,尝试来构建更高效的大模型架构。
来自主题: AI资讯
10554 点击 2023-12-30 15:20
 搜索
搜索
近日,来自华为诺亚方舟实验室、北京大学等机构的研究者提出了盘古 π 的网络架构,尝试来构建更高效的大模型架构。
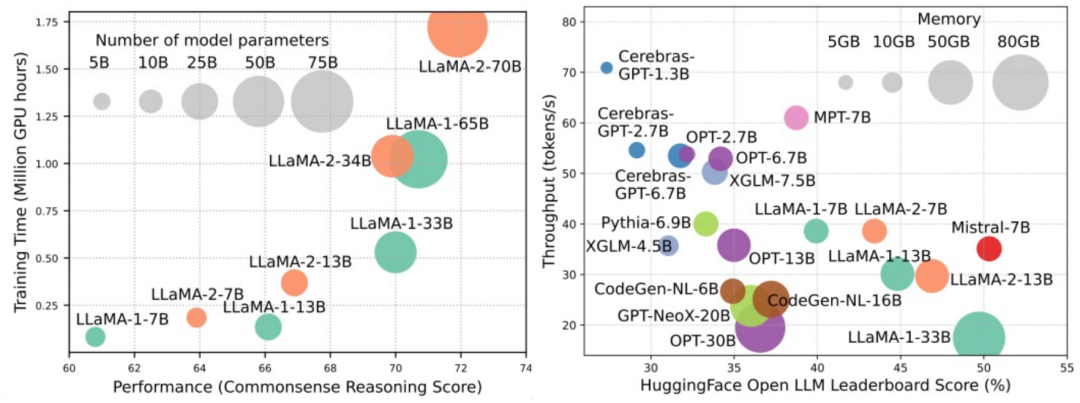
大规模语言模型(LLMs)在很多关键任务中展现出显著的能力,比如自然语言理解、语言生成和复杂推理,并对社会产生深远的影响。然而,这些卓越的能力伴随着对庞大训练资源的需求(如下图左)和较长推理时延(如下图右)。因此,研究者们需要开发出有效的技术手段去解决其效率问题。

首个视觉、语言、音频和动作多模态模型Unified-IO 2来了!它能够完成多种多模态的任务,在超过30个基准测试中展现出了卓越性能。
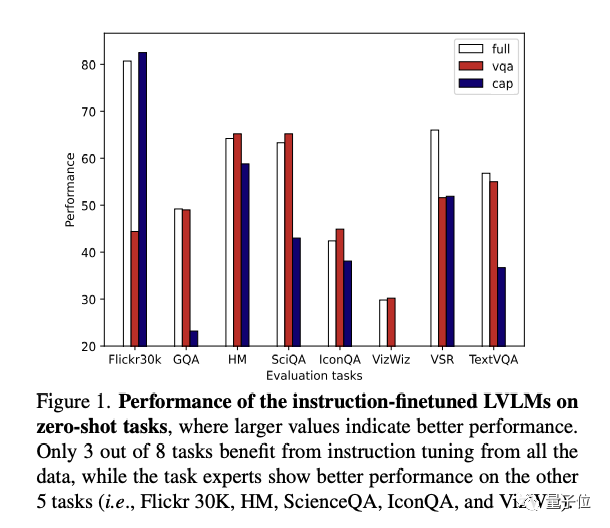
多模态大模型做“多任务指令微调”,大模型可能会“学得多错得多”,因为不同任务之间的冲突,导致泛化能力下降。

向量存储检索是个真需求,然而专用向量数据库已经凉了。
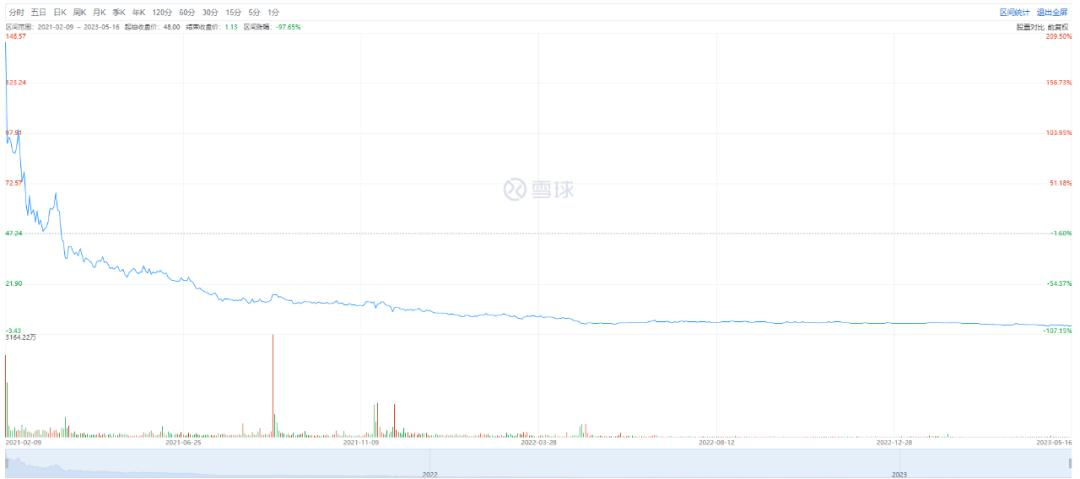
价格战、估值缩水、市值腰 斩、持续亏损、股价暴跌、资本退潮,入局一家亏损一家成为常态。 国内 SaaS产业从2015年至今历经8年探索,且在大量资本热钱涌入下,仍未找到清晰的盈利模型。

混合专家模型(MoE)成为最近关注的热点。

2024年,优化训练和部署大模型仍然非常重要,大模型的生态加速形成,应用开始在一些领域大规模展开,主要表现在如下十个领域:

在即将过去的2023年里,“大模型”无疑是最能挑动神经的话题,AI还在进化但已经成为显学。“百模大战”让很多创业项目的估值水涨船高,行业直接进入大厂竞争时代。

2023年12月13日,全球科技顶刊《Nature》发布年度十大人物,与以往不同的是,今年的Nature’s 10额外增加了一个非人类,ChatGPT。