
首家央企AI独角兽浮出水面!背靠自研大模型,4家国家队资本背书
首家央企AI独角兽浮出水面!背靠自研大模型,4家国家队资本背书央企第一家AI独角兽,诞生了。
来自主题: AI资讯
10245 点击 2026-01-07 18:32
 搜索
搜索
央企第一家AI独角兽,诞生了。
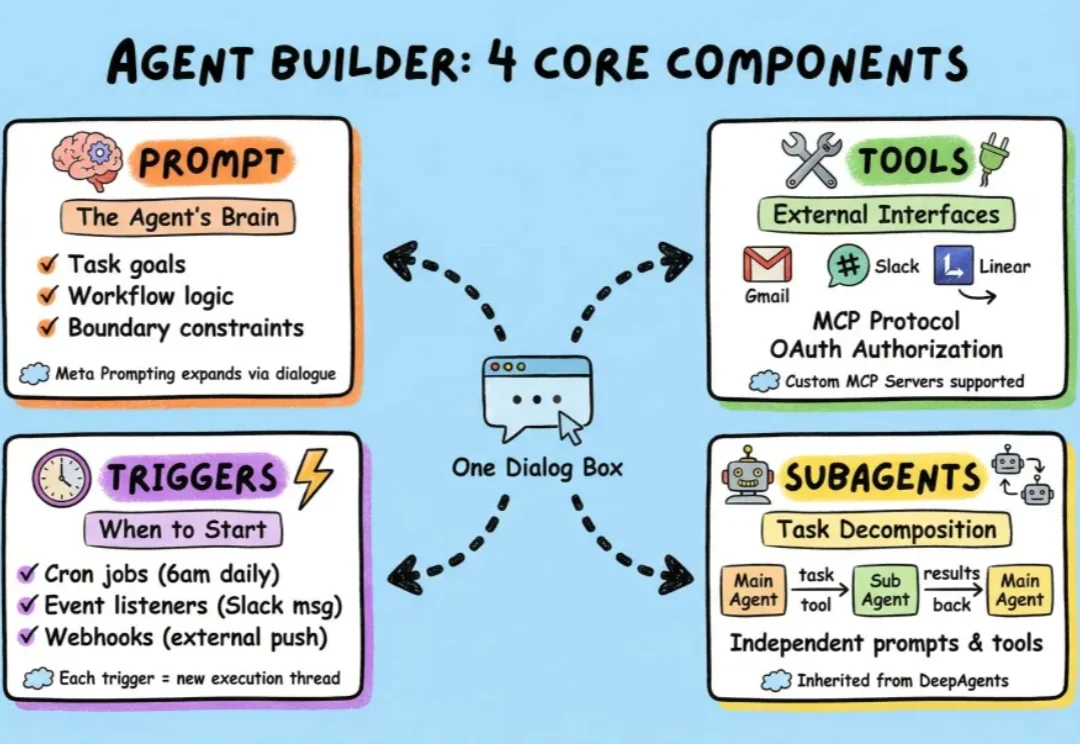
过去一段时间,我们介绍了很多小白入门级的agent框架,也介绍了包括langchain在内的很多专业级agent搭建框架。

Transformer 已经改变了世界,但也并非完美,依然还是有竞争者,比如线性递归(Linear Recurrences)或状态空间模型(SSM)。这些新方法希望能够在保持模型质量的同时显著提升计算性能和效率。

如果说2025 年是 AI 接受现实检验之年 ,那么 2026 年这项技术将走向实用化。业界焦点已从构建日益庞大的语言模型,转向更艰巨的使命——让 AI 真正可用。
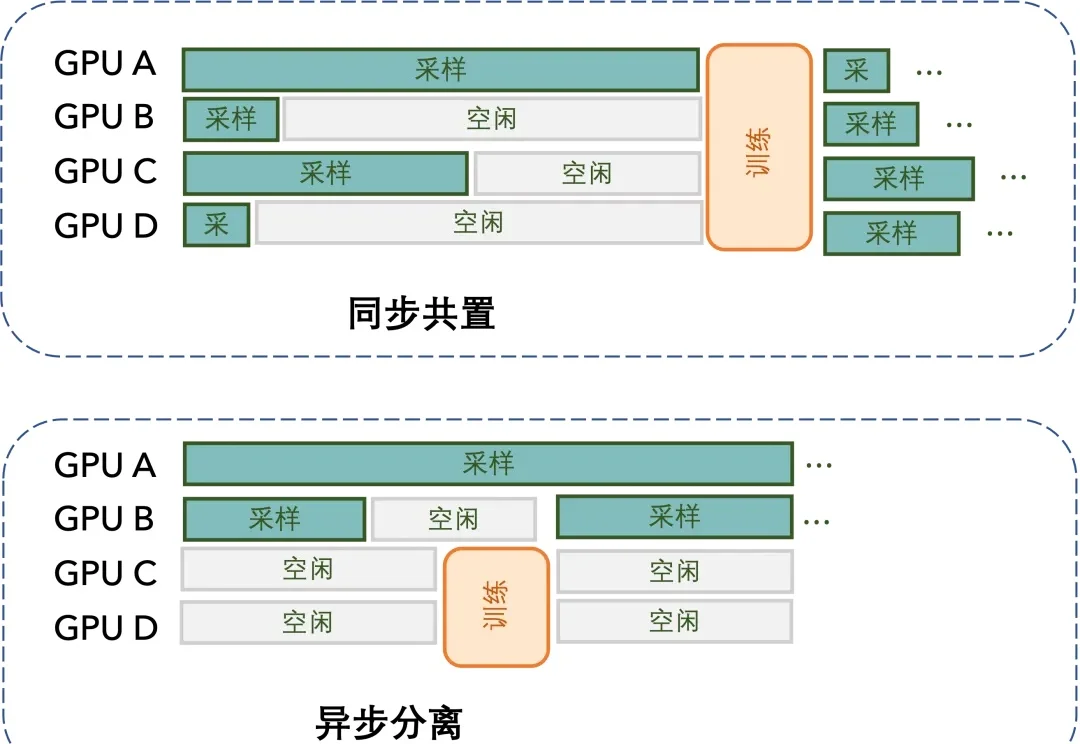
Andrej Karpathy 大神力荐的 Vibe Coding,正在成为开发者的新宠。这种「只需聊一聊,AI 可以把功能写出来」的体验,极大提升了简单任务的开放效率。
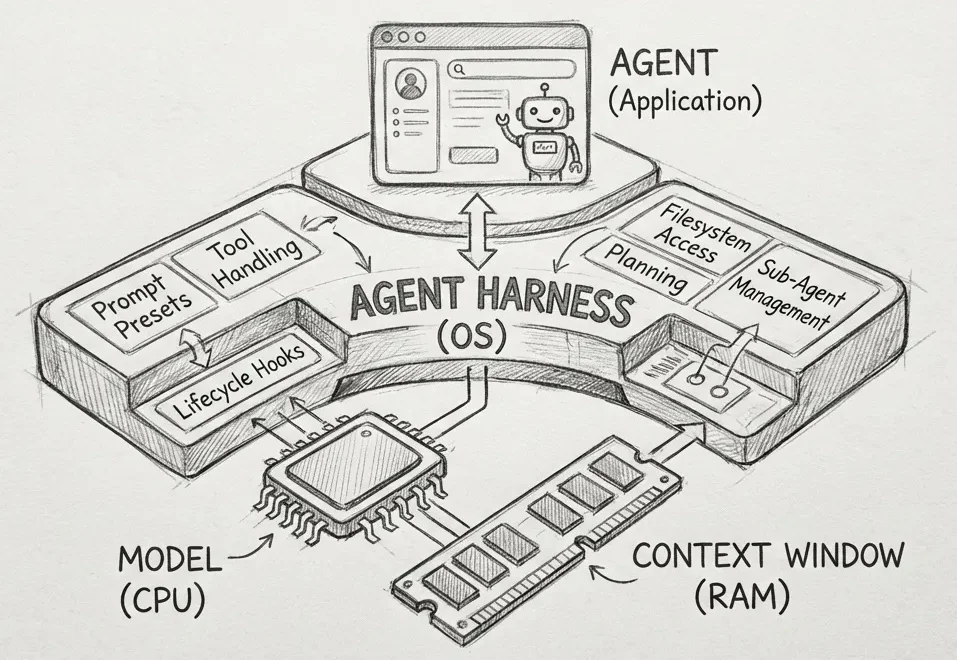
这篇文章的思路来自 Philipp Schmid,由 minghao 推荐 https://www.philschmid.de/agent-harness-2026
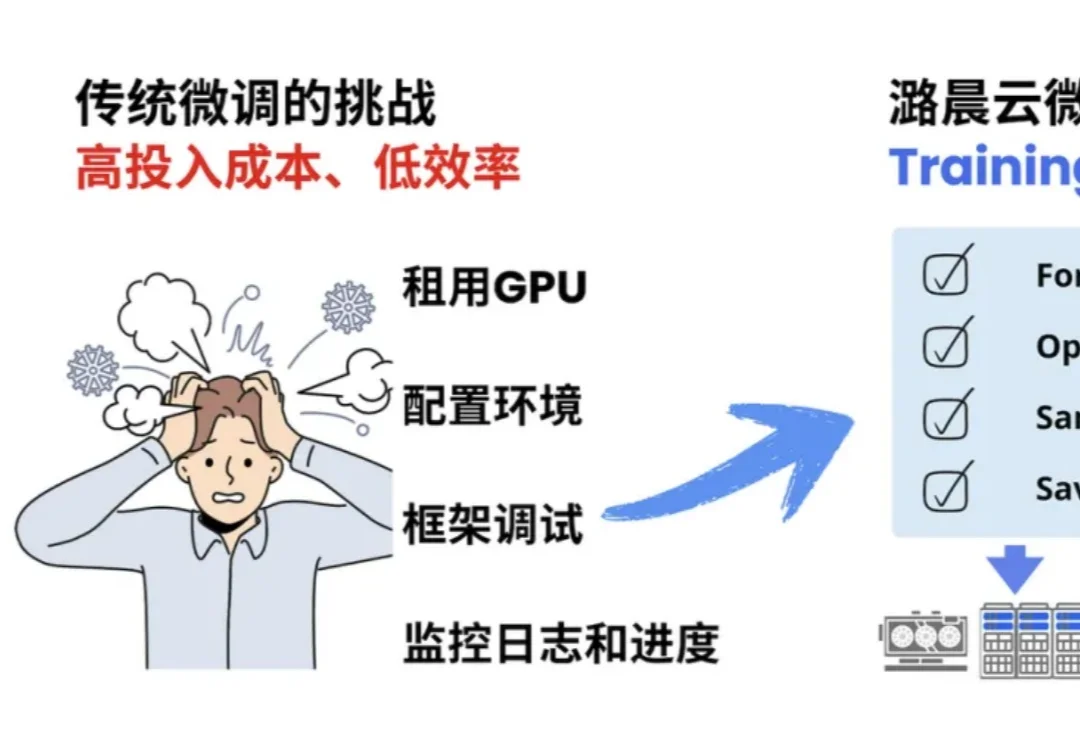
当 OpenAI 前 CTO Mira Murati 创立的 Thinking Machines Lab (TML) 用 Tinker 创新性的将大模型训练抽象成 forward backward,optimizer step 等⼀系列基本原语,分离了算法设计等部分与分布式训练基础设施关联,
对于电子产品,我们已然习惯了「出厂即巅峰」的设定:开箱的那一刻往往就是性能的顶点,随后的每一天都在折旧。
这两年一直在关注 AI,Claude Code 给我带来的震撼,和当初 Nano Banana 在画图领域的革命,几乎是一个级别。

2025 年,人工智能的发展重心正在发生一次根本性转移:从追求模型的规模,转向构建其理解与解决复杂现实问题的能力。在这一转型中,高质量数据正成为定义 AI 能力的新基石。作为人工智能数据服务的前沿探索者,数据堂深度参与并支撑着这场变革的每一个关键环节。本文将深入解读 2025 年 AI 五大技术趋势及其背后的数据需求变革。