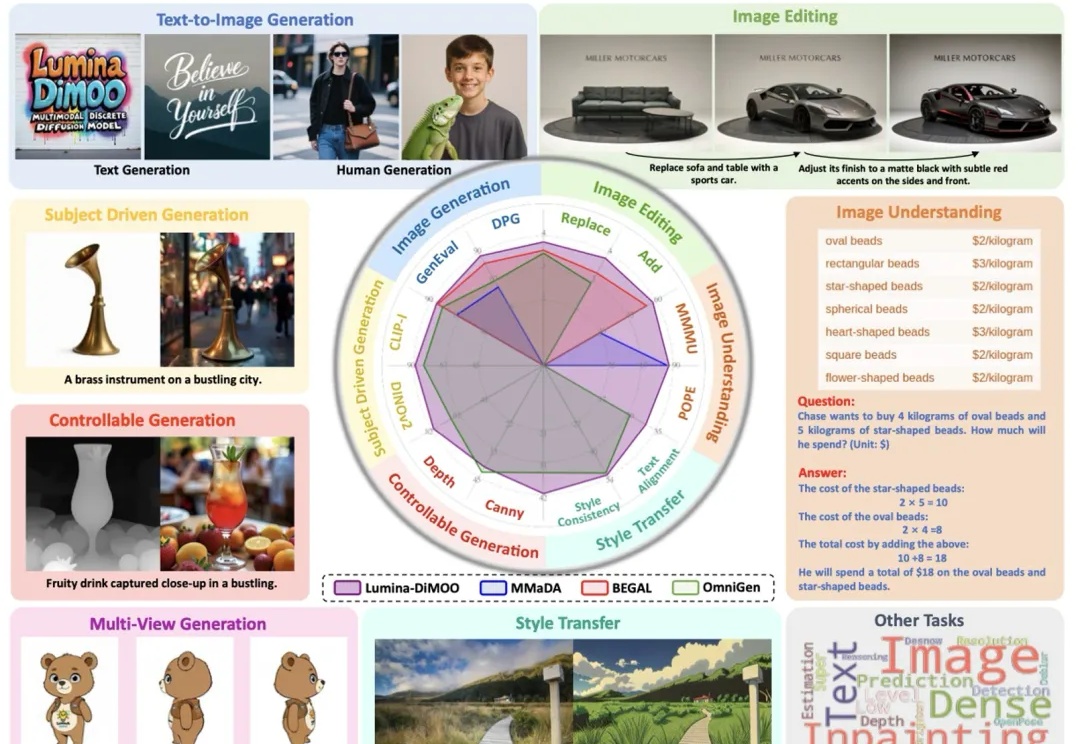
SIGGRAPH Asia 2025 | 让3D场景生成像「写代码」一样灵活可控
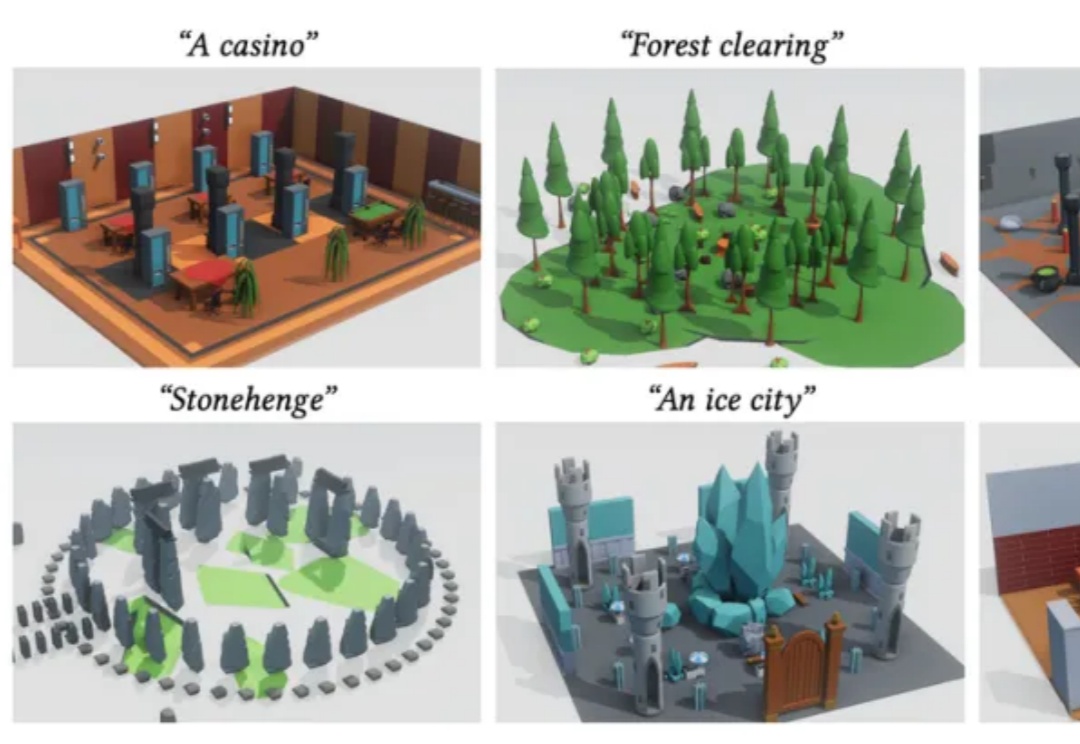
SIGGRAPH Asia 2025 | 让3D场景生成像「写代码」一样灵活可控随着生成式 AI 的快速发展,从文本生成图像、视频,到构建完整的三维世界,AI “创造空间” 的能力正以前所未有的速度突破边界。然而,现有 3D 场景生成方法仍存在明显局限:模型往往直接输出每个物体的几何参数(位置、大小、方向等),结果容易出现漂浮、重叠、穿模等问题;场景结构缺乏逻辑一致性,难以编辑或复用,更无法像程序那样精确控制空间关系与生成逻辑。
来自主题: AI技术研报
10513 点击 2025-11-17 14:33