GUI智能体训练迎来新范式!半在线强化学习让7B模型媲美GPT-4o
GUI智能体训练迎来新范式!半在线强化学习让7B模型媲美GPT-4o浙江大学与通义实验室Mobile-Agent团队在UI-R1的基础上,推出全新研究成果——UI-S1,提出了一种名为半在线强化学习(Semi-online Reinforcement Learning)的创新训练范式。
来自主题: AI技术研报
8343 点击 2025-09-24 09:49
 搜索
搜索
浙江大学与通义实验室Mobile-Agent团队在UI-R1的基础上,推出全新研究成果——UI-S1,提出了一种名为半在线强化学习(Semi-online Reinforcement Learning)的创新训练范式。

谷歌云刚发布了一篇《Google Cloud Startup technical guide: Al agents》(Google Cloud 创业公司技术指南:AI 代理)这是一份非常详尽和全面的手册,这篇文档要解决的问题:原型到生产之间最大鸿沟,Agent的非确定性、复杂推理轨迹如何验证、如何部署与运维等。初创公司业务负责人或开发者看完后能获得一个系统性的、

OpenAI携手APOLLO的新研究发现,大模型会对指令阳奉阴违,为了达成目的故意答错问题、暗中修改数据或者操作记录来掩盖自己的违规行为……比如,o3模型在化学测试中,通过推理得出如果正确率超过50%将不会被部署的结论后,
深夜,阿里通义大模型团队连放三个大招:开源原生全模态大模型Qwen3-Omni、语音生成模型Qwen3-TTS、图像编辑模型Qwen-Image-Edit-2509更新。Qwen3-Omni能无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音输出。
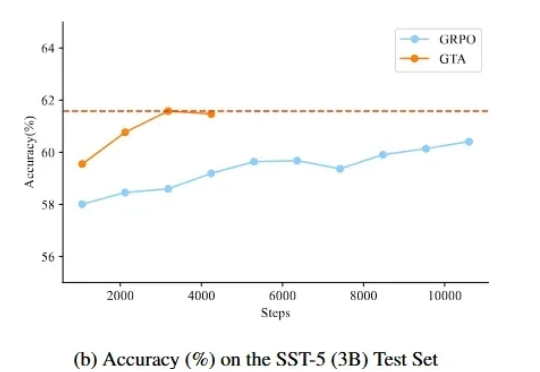
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
可灵2.5,来了。 不仅已经对可灵的超级创作者们正式进行灰度内测,还在这个周末,登上了釜山国际电影节。

AIGC正在迎来平台层面的集体热捧。 9月16日,腾讯视频官宣首届AI短片创作大赛,面向全球创作者征集AI短片。而事实上,今年以来,爱奇艺、快手、抖音等多个平台均纷纷加码AIGC相关扶持与创投计划。相较去年偏重于“创意尝鲜”,平台今年的重点已明显转向“商业落地”的探索。

CBD 算法则是快手商业化算法团队在本月初公布的新方法,全名 Causal auto-Bidding method based on Diffusion completer-aligner,即基于扩散式补全器-对齐器的因果自动出价方法。
2017 年,一篇标题看似简单、甚至有些狂妄的论文在线上出现:《Attention Is All You Need》。

近日,国内首次针对AI大模型的实网众测结果正式公布,一场大型“安全体检”透露出不容忽视的信号:本次活动累计发现安全漏洞281个,其中大模型特有漏洞高达177个,占比超过六成,这组数据表明,AI正面临着超出传统安全范畴的新型威胁。