
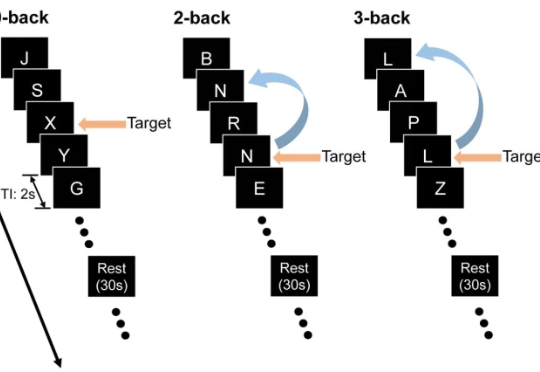
AI记忆伪装被戳穿!GPT、DeepSeek等17款主流大模型根本记不住数字
AI记忆伪装被戳穿!GPT、DeepSeek等17款主流大模型根本记不住数字最近,来自约翰・霍普金斯大学与中国人民大学的团队设计了三套实验,专门把关键线索藏在上下文之外,逼模型「凭记忆」作答,从而检验它们是否真的在脑海里保留了信息。
来自主题: AI技术研报
9290 点击 2025-06-15 15:16
最近,来自约翰・霍普金斯大学与中国人民大学的团队设计了三套实验,专门把关键线索藏在上下文之外,逼模型「凭记忆」作答,从而检验它们是否真的在脑海里保留了信息。

需要新创新点。跨境游热度不减、出海成为当前中企的“必答题”、AI大模型技术持续升级等多重因素共同推动,AI耳机市场持续火热。继2024年为“AI耳机元年”,AI耳机为耳机品类中增长最快的子赛道之一。
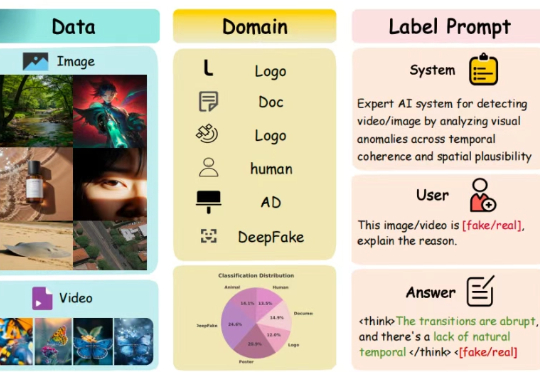
想象一下:你正在浏览社交媒体,看到一张震撼的图片或一段令人震撼的视频。它栩栩如生,细节丰富,让你不禁信以为真。但它究竟是真实记录,还是由顶尖 AI 精心炮制的「杰作」?如果一个 AI 工具告诉你这是「假的」,它能进一步解释理由吗?它能清晰指出图像中不合常理的光影,或是视频里一闪而过的时序破绽吗?

大家好,我是AI产品黄叔!今天要给大家讲一个让我热血沸腾的创业故事,主角是我的好兄弟猛哥,他在AI网文这个赛道上演了一出从0到1的精彩戏码。前期仅靠2个人全职,不到一年时间就做到了2万月活,月入百万的成绩。而这一切,都发生在我们的小群里——4个人,其中3个都在AI创业,彼此见证了对方从无到有的全过程。

研究多智能体必读指南。Anthropic 发布了他们如何使用多个 Claude AI 智能体构建多智能体研究系统的精彩解释。

6月13日,灵童念NIA-F01人形机器人首发上线京东。记得在4月份时,AING硬迹平台发布过“科大讯飞投资的机器人公司即将发布全球唯一桌面级具身人形机器人”的文章,现在灵童机器人这款产品在众多期待中上线了。

Mercor 所处的赛道是 AI 中一个关键且尚未被充分满足的供需交叉点:下一代 AI 模型对高质量、垂直领域专家级 Human Data 的需求,以及相关人才稀缺所带来的供需不平衡。合成数据无法完全替代 Human Data,尤其是在特定领域知识和复杂判断方面。AI 模型的突破性进展高度依赖于垂直领域专家的“人类智能输入”。

研究人员发现,大语言模型的遗忘并非简单的信息删除,而是可能隐藏在模型内部。通过构建表示空间分析工具,区分了可逆遗忘和不可逆遗忘,揭示了真正遗忘的本质是结构性的抹除,而非行为的抑制。
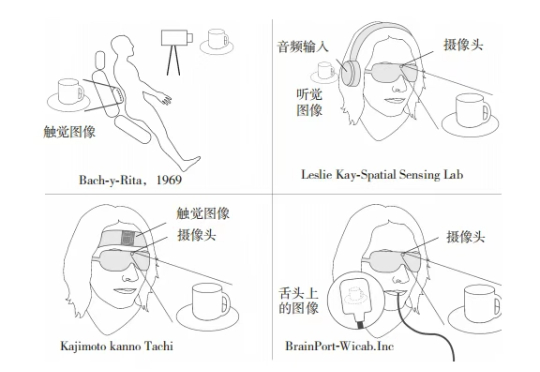
我们每个人的生活,都是由这三磅重、果冻状大脑书写的完整人生。我们所有的意识、情感、决策、创造力,都源自宇宙中最复杂的事物——大脑。当860亿个神经元在潮湿的电化学网络中涌动时,一个全新的自我正在浮现。

就在刚刚的CVPR上,鹅厂3D生成模型混元3D 2.1正式宣布开源!