

Copilot上大分,仅数天,陶哲轩的估计验证工具卷到2.0!刚刚又发数学形式化证明视频
Copilot上大分,仅数天,陶哲轩的估计验证工具卷到2.0!刚刚又发数学形式化证明视频本周二,我们报道了菲尔兹奖得主陶哲轩的一个开源项目 —— 在大模型的协助下编写了一个概念验证软件工具,来验证涉及任意正参数的给定估计是否成立(在常数因子范围内)。这才几天的时间,这个估计验证工具的 2.0 版本就来了!
来自主题: AI资讯
9162 点击 2025-05-11 15:22
本周二,我们报道了菲尔兹奖得主陶哲轩的一个开源项目 —— 在大模型的协助下编写了一个概念验证软件工具,来验证涉及任意正参数的给定估计是否成立(在常数因子范围内)。这才几天的时间,这个估计验证工具的 2.0 版本就来了!

字节Seed首次开源代码模型!Seed-Coder,8B规模,超越Qwen3,拿下多个SOTA。它证明“只需极少人工参与,LLM就能自行管理代码训练数据”。通过自身生成和筛选高质量训练数据,可大幅提升模型代码生成能力。

最近阿里通义实验室应用视觉团队负责人薄列峰被曝离职,引起了一轮热议。而这已是继2月语音团队负责人鄢志杰、2024年8月大模型技术负责人周畅之后,阿里AI核心部门第三次失去关键人物了。

怎么老是你???(How old are you)尤其是最近Meta FAIR研究员朱泽园分享了他们《Physics of Language Models》项目的系列新进展后,有网友发现,其中提到的3-token因果卷积相关内容,沙哥等又早在三年前就有相关研究。这是最近网友不断对着Transformer八子之一的Noam Shazeer(为方便阅读,我们称他为沙哥)发出的灵魂疑问。
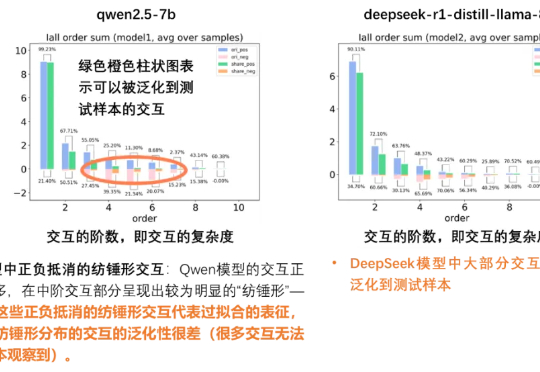
当以端到端黑盒训练为代表的深度学习深陷低效 Scaling Law 而无法自拔时,我们是否可以回到起点重看模型表征本身——究竟什么才是一个人工智能模型的「表征质量」或者「泛化性」?我们真的只有通过海量的测试数据才能抓住泛化性的本质吗?或者说,能否在数学上找到一个定理,直接从表征逻辑复杂度本身就给出一个对模型泛化性的先验的判断呢?

一个月前,在旧金山全球游戏开发者大会上,AI原生独立游戏《1001夜》的制作人担任GDC Al Summit的演讲者,分享游戏中大语言模型驱动的核心玩法设计,与世界各地的游戏开发者进行了深入的交流。

海内外大厂大模型研发正在进入新升级周期,为了加速补齐技术短板,腾讯混元近日进行了大幅架构调整,重构研发体系。但面对海内外对手的凌厉攻势,手握大把国民级应用的腾讯,还需要找到更好的攻防节奏。

最近,奥特曼再次出席美国国会山听证会。他对美国政府呼吁:一定要放开监管,过早设定标准,对美国AI将是一场灾难!另外他还透露,OpenAI第一个开源模型,会在今年夏天发布。值得一提的是,奥特曼神秘的家庭生活,也在一位记者的亲身探寻下,让我们窥到了一斑。

5月9日,京西智谷潭柘智空基座大模型体系及应用平台建设项目开标,北京智谱清言科技有限公司中标,金额6400万元。根据此前公开的采购公告,本项目招标范围是:文生图片平台、图生视频与视频生视频平台、汉藏平台、多语种平台、AI数字人与垂类大模型对接平台、集成总平台等。

小天才和小镇做题家,在AI赛道都有光明的未来。