阶跃星辰开源图像编辑模型Step1X-Edit:一键改图大师,性能达到开源SOTA
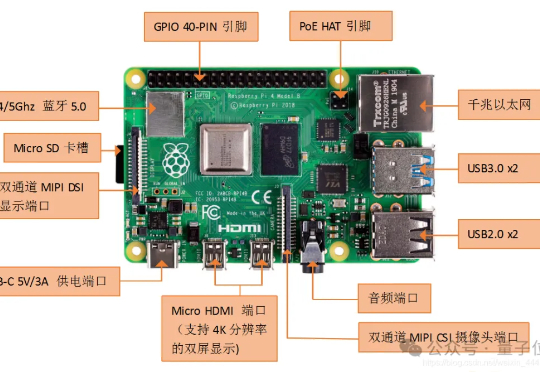
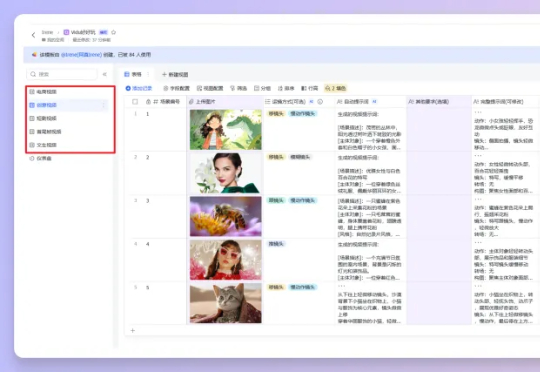
阶跃星辰开源图像编辑模型Step1X-Edit:一键改图大师,性能达到开源SOTA阶跃星辰正式发布并开源图像编辑大模型 Step1X-Edit,性能达到开源 SOTA。该模型总参数量为 19B (7B MLLM + 12B DiT),具备语义精准解析、身份一致性保持、高精度区域级控制三项关键能力;支持 11 类高频图像编辑任务类型,如文字替换、风格迁移、材质变换、人物修图等。
来自主题: AI资讯
10370 点击 2025-04-27 15:29