
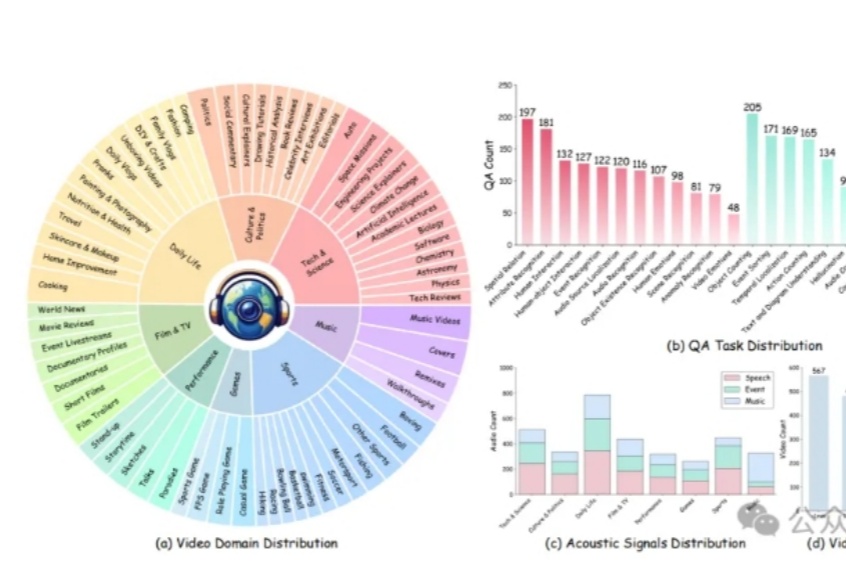
小红书&上交多模态大模型新基准,Gemini 1.5 Pro准确率仅48%
小红书&上交多模态大模型新基准,Gemini 1.5 Pro准确率仅48%多模态大模型理解真实世界的水平到底如何?
来自主题: AI技术研报
6103 点击 2025-02-13 09:49
多模态大模型理解真实世界的水平到底如何?

最近,全球科技行业的焦点无疑落在了DeepSeek引发的热潮之上。几乎在一夜之间,全球市场对中国AI大模型及其相关产业的态度发生了180度转变——从此前的“过度悲观”瞬间跳跃至“极度乐观”,2025也似乎成为中美AI对决元年。

DeepSeek 最近的爆火程度令人咋舌。短短20天内用户量就突破3000万,导致官方服务器几乎天天处于过载状态。虽然市面上已经涌现出不少第三方接入平台,但这些平台大多针对个人用户,对开发者和企业的需求难以满足。
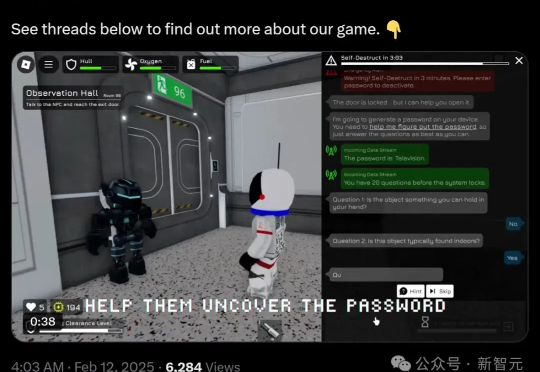
还在用枯燥的数学题和编程题测试AI?落伍啦!现在,打游戏就能测出AI的真实力。GameArena团队打造的Roblox新游《AI空间逃脱》,让你在紧张刺激的密室逃脱中,顺便就把AI模型的推理能力给评估了。这不仅比传统测试方法更有趣,还能生成宝贵的游戏数据,帮助开发者更全面地了解AI的强项与短板。
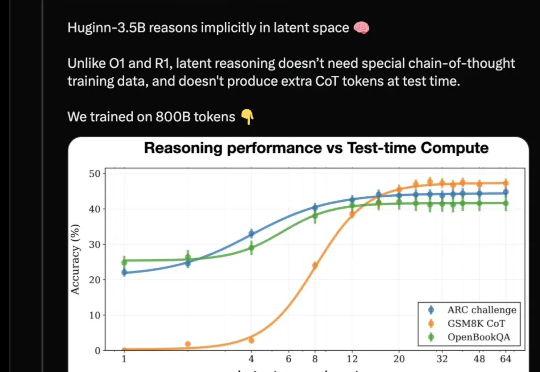
开源推理大模型新架构来了,采用与Deepseek-R1/OpenAI o1截然不同的路线: 抛弃长思维链和人类的语言,直接在连续的高维潜空间用隐藏状态推理,可自适应地花费更多计算来思考更长时间。

这一篇文章来源于我自己的困惑而进行的探索和思考,再进行多次讨论后总觉隔靴搔痒,理解不透彻。 而在我自己整理后,发现已经有小伙伴点明了他们的区别。但是因为了解深度的不够,即使告诉了答案,我也无法理解,总有隔靴搔痒之感。
复旦新研究揭示了AI系统自我复制的突破性进展,表明当前的LLM已具备在没有人类干预的情况下自我克隆的能力。这不仅是AI超越人类的一大步,也为「流氓AI」埋下了隐患,带来前所未有的安全风险。

人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。

DeepSeek的爆火,让AI大模型在新一年的开年,又一次引起了全球的关注。然而,时至今日全球AI领域还没有完全消化DeepSeek带来的实质影响——这样的模式将给全球、给中国AI领域带来什么样的变局?
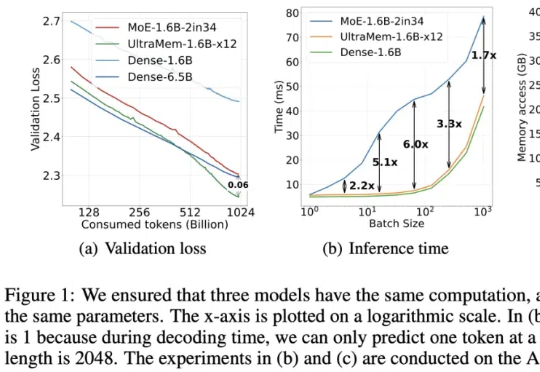
字节出了个全新架构,把推理成本给狠狠地打了下去!推理速度相比MoE架构提升2-6倍,推理成本最高可降低83%。