
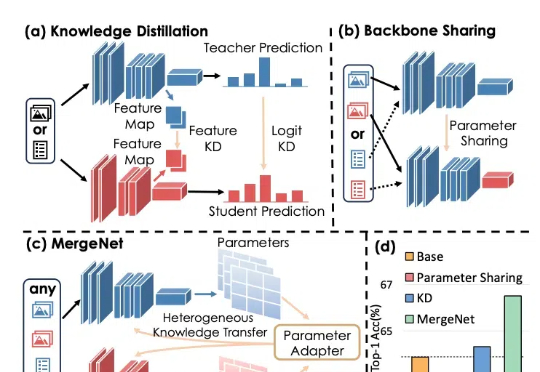
模型参数作知识通用载体,MergeNet离真正的异构知识迁移更进一步
模型参数作知识通用载体,MergeNet离真正的异构知识迁移更进一步知识蒸馏通过训练一个紧凑的学生模型来模仿教师模型的 Logits 或 Feature Map,提高学生模型的准确性。迁移学习则通常通过预训练和微调,将预训练阶段在大规模数据集上学到的知识通过骨干网络共享应用于下游任务。
来自主题: AI技术研报
5595 点击 2025-01-28 11:57
知识蒸馏通过训练一个紧凑的学生模型来模仿教师模型的 Logits 或 Feature Map,提高学生模型的准确性。迁移学习则通常通过预训练和微调,将预训练阶段在大规模数据集上学到的知识通过骨干网络共享应用于下游任务。

在过去的两年里,城市场景生成技术迎来了飞速发展,一个全新的概念 ——世界模型(World Model)也随之崛起。当前的世界模型大多依赖 Video Diffusion Models(视频扩散模型)强大的生成能力,在城市场景合成方面取得了令人瞩目的突破。然而,这些方法始终面临一个关键挑战:如何在视频生成过程中保持多视角一致性?

DeepSeek大爆出圈,现在连夜发布新模型——多模态Janus-Pro-7B,发布即开源。在GenEval和DPG-Bench基准测试中击败了DALL-E 3和Stable Diffusion。

在美国发布AI禁令后,特朗普随即宣布了一项预算高达5000亿美元的AGI计划——星际之门,以保证其在AI领域的领先地位。而在大洋彼岸的中国,一家名为Deepseek的中国创业公司,只用了2048块显卡,就训练出了一个能与顶级模型相媲美的Deepseek-V3模型。

谈到大模型的“国货之光”,除了DeepSeek之外,阿里云Qwen这边也有新动作——首次将开源Qwen模型的上下文扩展到1M长度。

明天就是辞旧迎新的春节假期,咱来点不一样的——送上一份「年初展望」,站在2025年伊始,把AI科技领域不同领域的热点趋势,浅浅盘了一圈。从人型机器人、AI眼镜,从推理模型到AI Coding……分别从产品侧和技术侧,把今年最有料的8个大热门趋势一网打尽,干货过年。

2028年,预计高质量数据将要耗尽,数据Scaling走向尽头。2025年,测试时计算将开始成为主导AI通向通用人工智能(AGI)的新一代Scaling Law。近日,CMU机器学习系博客发表新的技术文章,从元强化学习(meta RL)角度,详细解释了如何优化LLM测试时计算。

最近,AI界被推理模型刷屏了。国内各家的推理模型,在新年到来之际不断刷新我们的认知。不过,当我们在实际应用中考量大模型,衡量好不好用的标准,就绝不仅仅局限于其性能和规模了。
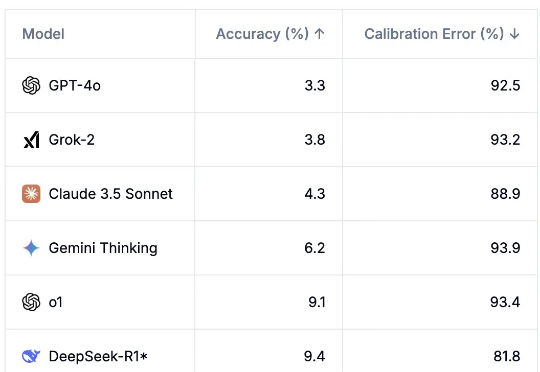
AI模型可能并没有想象中强大。在最新的AI基准测试「人类最后一次考试」中,所有顶尖LLM通过率不超过10%,而且模型都表现得过度自信。

研究人员首次探讨了大型语言模型(LLMs)在问题生成任务中的表现,与人类生成的问题进行了多维度对比,结果发现LLMs倾向于生成需要较长描述性答案的问题,且在问题生成中对上下文的关注更均衡。