

跟硅谷的核心AI公司聊完后,得到了这 60 条关键洞察
跟硅谷的核心AI公司聊完后,得到了这 60 条关键洞察对 LLM 来说,Pre-training 的时代已经基本结束了。视频模型的 Scaling Law,瓶颈还很早。具身智能:完全具备人类泛化能力的机器人,在我们这代可能无法实现
来自主题: AI资讯
8525 点击 2025-01-24 12:57
对 LLM 来说,Pre-training 的时代已经基本结束了。视频模型的 Scaling Law,瓶颈还很早。具身智能:完全具备人类泛化能力的机器人,在我们这代可能无法实现

AI硬件能孕育出新的巨头吗2025年初,在AI大模型和AI应用热潮之后,消费级AI硬件也开始逐步受到市场和资本的关注,除了手机和PC外,AI也确实正在改变消费电子产品的外延和形态。截至目前,我们统计至少已有117家公司入局了AI硬件。这些硬件产品主要集中在眼镜、耳机、教育、陪伴、助理和健康六大领域,其中有超7成为中国公司,除中国之外,美、日、韩、印、以色列企业均有参与。

字节最近推出了一款名为 Trae 的 AI 编程工具,面向海外的AI中文开发环境IDE。号称实现了从Copilot向Autopilot的演进。该工具可选择简体中文或英文,并内置了GPT-4o、Claude-3.5-Sonnet模型供免费使用。
昨天豆包大模型 1.5 全家桶正式发布了嘛,官方刚发布 15 分钟,就被咱们 Family 群里的家人给发现了,并且发出灵魂拷问——谁能测测?

赶在放假前,支棱起来的国产 AI 大模型厂商井喷式发布了一大堆春节礼物。前脚 DeepSeek-R1 正式发布,号称性能对标 OpenAI o1 正式版,后脚 k1.5 新模型也正式登场,表示性能做到满血版多模态 o1 水平。

「工程师正在疯狂地分析 DeepSeek,试图从中复制任何可能的东西。」DeepSeek 开源大模型的阳谋,切切实实震撼着美国 AI 公司。最先陷入恐慌的,似乎是同样推崇开源的 Meta。

跟AI交互这事儿,商汤最新发布的大模型,是有点“够快、够准、够好”在身上的。

刚刚发布的豆包大模型1.5,不仅多模态能力全面提升,霸榜多个基准;更难得的是,它在训练过程中从未使用过任何其他模型生成的数据,坚决不走蒸馏「捷径」。
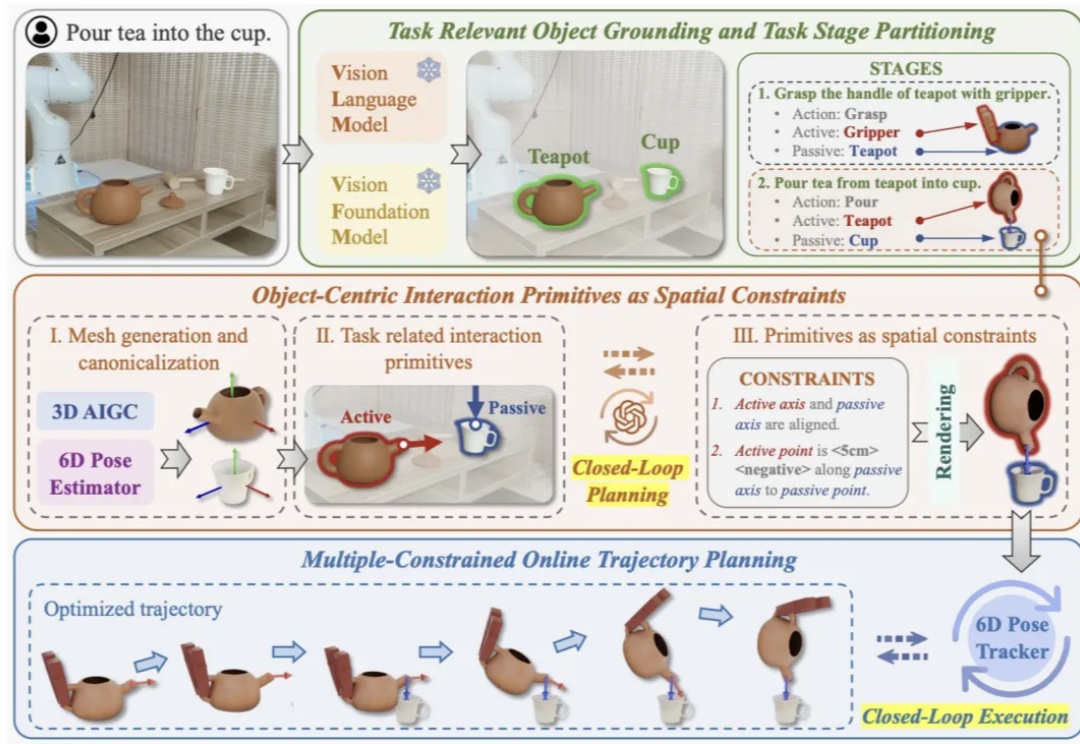
近年来视觉语⾔基础模型(Vision Language Models, VLMs)在多模态理解和⾼层次常识推理上⼤放异彩,如何将其应⽤于机器⼈以实现通⽤操作是具身智能领域的⼀个核⼼问题。这⼀⽬标的实现受两⼤关键挑战制约:
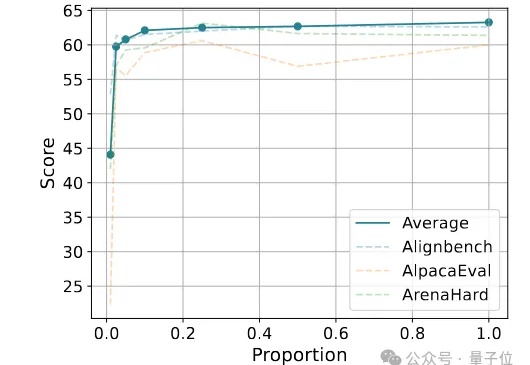
仅使用20K合成数据,就能让Qwen模型能力飙升——