

更懂中文还兼顾SD生态,360开源文生图模型结构,寡姐秒变中国新娘 | AAAI
更懂中文还兼顾SD生态,360开源文生图模型结构,寡姐秒变中国新娘 | AAAI具备原生中文理解能力,还兼容Stable Diffusion生态。 最新模型结构Bridge Diffusion Model来了。 与Dreambooth模型结合,它生成的穿中式婚礼礼服的歪国明星长这样。
来自主题: AI资讯
8230 点击 2024-12-19 10:08
具备原生中文理解能力,还兼容Stable Diffusion生态。 最新模型结构Bridge Diffusion Model来了。 与Dreambooth模型结合,它生成的穿中式婚礼礼服的歪国明星长这样。

近期,巨人网络发布了“千影QianYing”有声游戏生成大模型,包含游戏视频生成大模型YingGame、视频配音大模型YingSound,实现了有声可交互游戏视频生成的新突破。

AI真是助力科研的神器,不光能用大模型提升写作效率,跟AI技术沾边的论文中顶刊的概率也会增加,升职速度也会提升;但对于科学界来说,大家都一股脑去研究AI,那些不能用AI的领域受到了冷落,最终导致整体科研多样性下降。

OpenAI最近奉上了满血版的o1 Pro,这一全新系列的模型究竟有多强?它能否指明AI发展的未来方向?沃顿商学院教授在3个月的前一篇博客就中给出了「神预言」一般的答案。
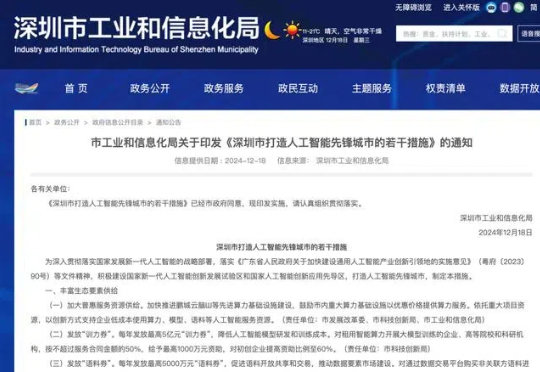
12月18日,记者从深圳市工业和信息化局了解到,深圳拟出台若干措施,积极建设国家新一代人工智能创新发展试验区和国家人工智能创新应用先导区,打造人工智能先锋城市。其中,在丰富生态要素供给方面,每年发放最高5亿元“训力券”,降低人工智能模型研发和训练成本。同时每年发放最高5000万元“语料券”,促进语料开放共享和交易,推动数据要素市场建设。
大洋彼岸的OpenAI系列春晚还在继续,连续发布会的第9天,OpenAI正式发布了o1模型的API。

12 月 2-6 日,亚马逊云科技在美国拉斯维加斯举办了今年度的 re:Invent 大会。会上,亚马逊云科技发布了相当多东西,其中之一便是新的大模型系列 Nova。说实话,这确实出乎了相当多人的意料 —— 毕竟亚马逊已经重金押注 Anthropic,似乎没有必要再自起炉灶了。
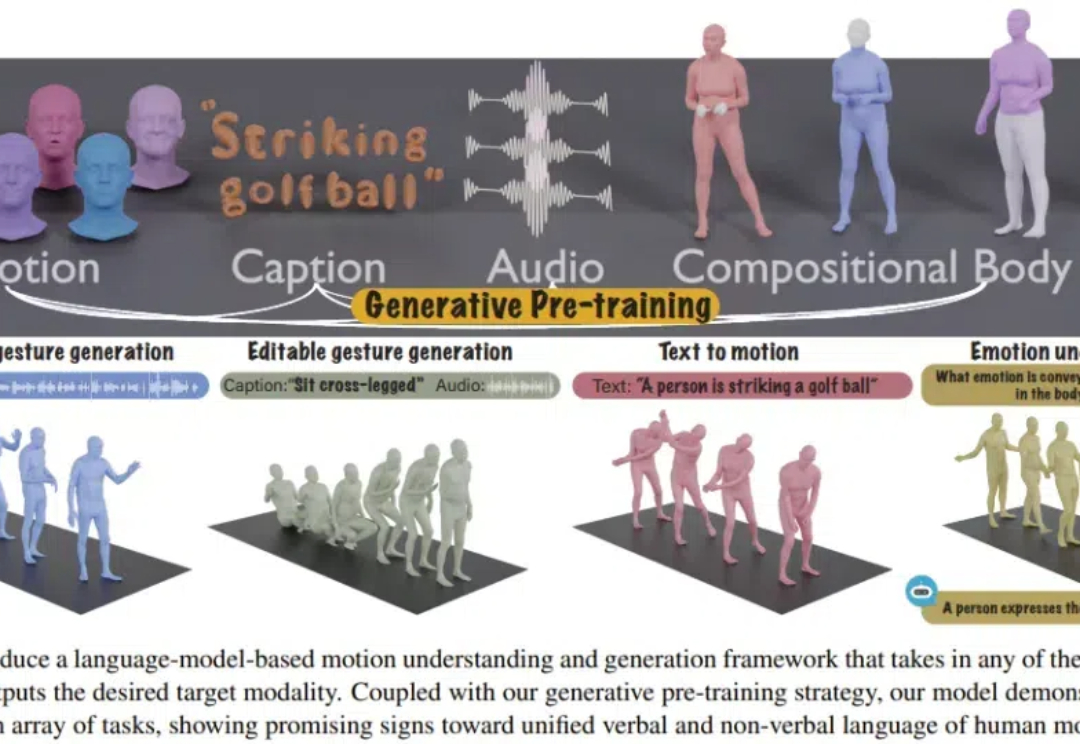
人类的沟通交流充满了多模态的信息。为了与他人进行有效沟通,我们既使用言语语言,也使用身体语言,比如手势、面部表情、身体姿势和情绪表达。
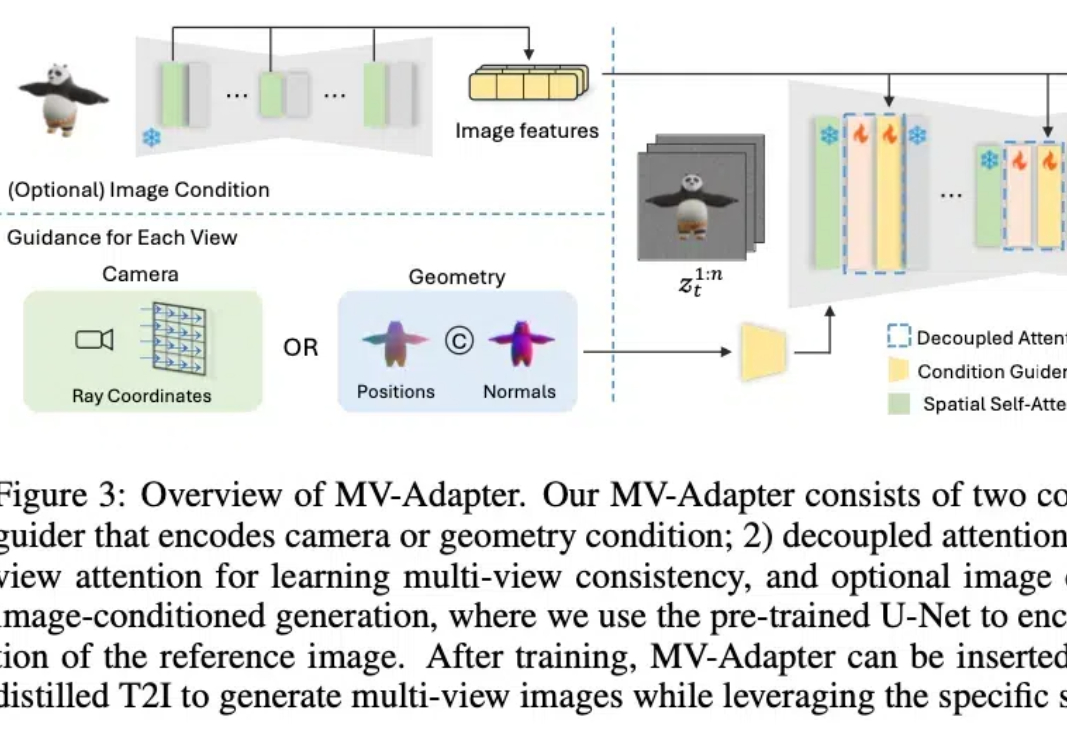
最近,2D/3D 内容创作、世界模型(World Models)似乎成为 AI 领域的热门关键词。作为计算机视觉的基础任务之一,多视角图像生成是上述热点方向的技术基础,在 3D 场景生成、虚拟现实、具身感知与仿真、自动驾驶等领域展现了广泛的应用潜力。
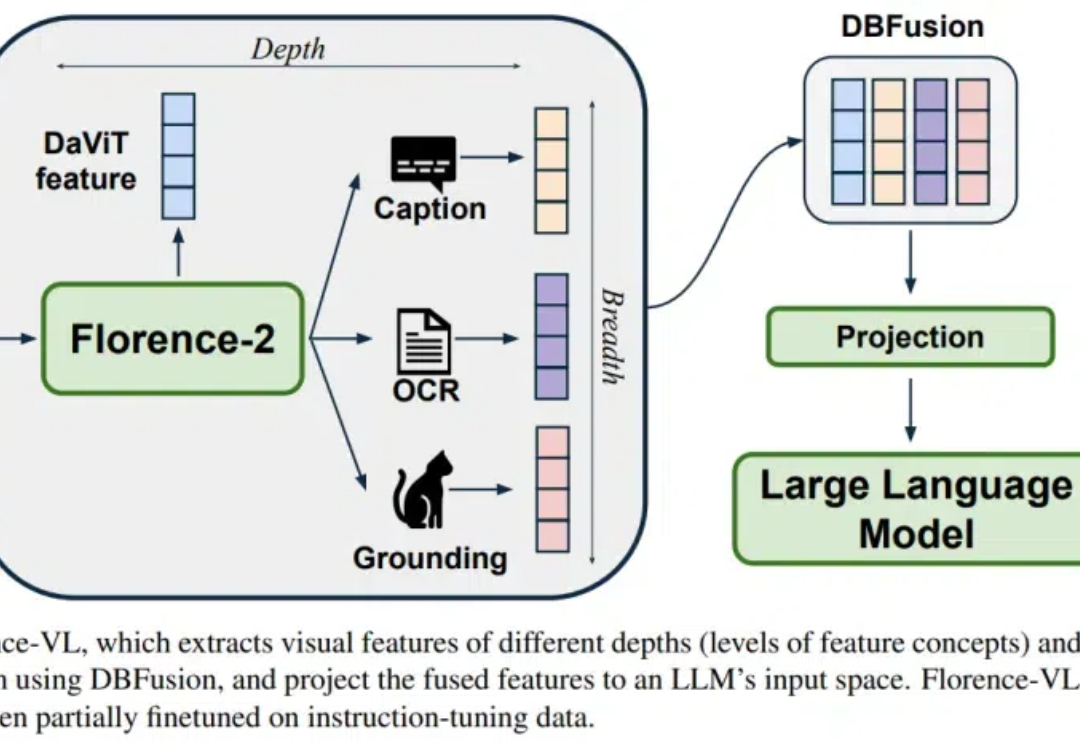
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。