
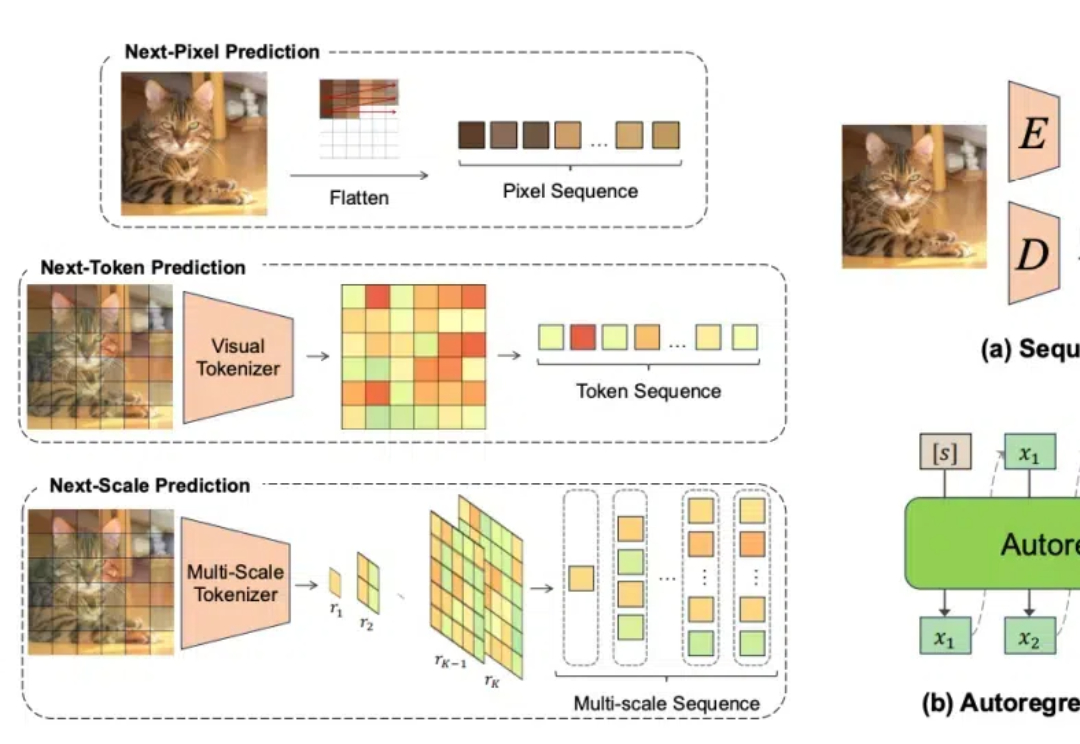
关于计算机视觉中的自回归模型,这篇综述一网打尽了
关于计算机视觉中的自回归模型,这篇综述一网打尽了随着计算机视觉领域的不断发展,自回归模型作为一种强大的生成模型,在图像生成、视频生成、3D 生成和多模态生成等任务中展现出了巨大的潜力。然而,由于该领域的快速发展,及时、全面地了解自回归模型的研究现状和进展变得至关重要。本文旨在对视觉领域中的自回归模型进行全面综述,为研究人员提供一个清晰的参考框架。
来自主题: AI技术研报
8703 点击 2024-12-01 14:21
随着计算机视觉领域的不断发展,自回归模型作为一种强大的生成模型,在图像生成、视频生成、3D 生成和多模态生成等任务中展现出了巨大的潜力。然而,由于该领域的快速发展,及时、全面地了解自回归模型的研究现状和进展变得至关重要。本文旨在对视觉领域中的自回归模型进行全面综述,为研究人员提供一个清晰的参考框架。

本周五,知名 AI 领域学者,OpenAI 创始成员、特斯拉前 AI 高级总监 Andrej Karpathy 发表观点:「人们对『向人工智能询问某件事』的解释过于夸张」,引发网友热议。
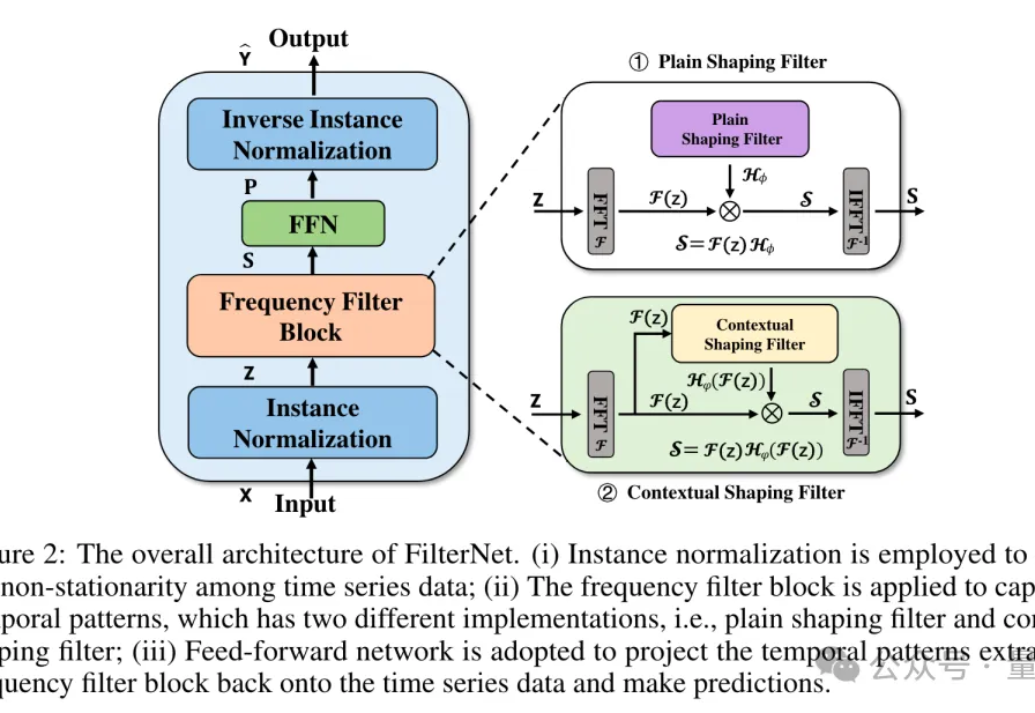
无需Transformer,简单滤波器即可提高时间序列预测精度。 由国家信息中心、牛津大学、北京理工大学、同济大学、中国科学技术大学等机构的团队提出了一个FilterNet。 目前已被NeurlPS 2024接收。

2024年,企业对AI的投资激增至138亿美元,显示了行业从实验到实际应用的转变,AI技术正逐渐渗透到各行业核心,推动效率和创新。同时,企业在AI应用上趋向于采用多模型策略,且越来越重视自主智能体技术。

Llamacoder是Claude Artifacts的开源实现。 最大的亮点就是,左侧AI写代码,右侧实时渲染。 之前给大家推荐过一个基于Claude做的,Llamacoder是用了Meta 的 Llama 3.1 405B 作为底层语言模型。

人工智能语音初创公司PlayAI宣布在种子轮融资中筹集了2100万美元。该公司表示,将利用这笔资金投资于其生成式人工智能(GenAI)语音模型和语音代理平台。
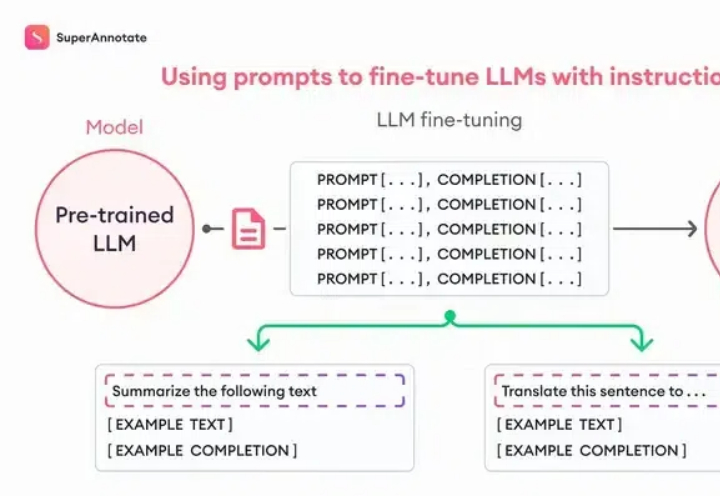
Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。

曾经参与过公司内部的RAG应用,写过一篇关于RAG的技术详情以及有哪些好用的技巧,这次专注于总结一下RAG的提升方法。

LLM 规模扩展的一个根本性挑战是缺乏对涌现能力的理解。特别是,语言模型预训练损失是高度可预测的。然而,下游能力的可预测性要差得多,有时甚至会出现涌现跳跃(emergent jump),这使得预测未来模型的能力变得具有挑战性。
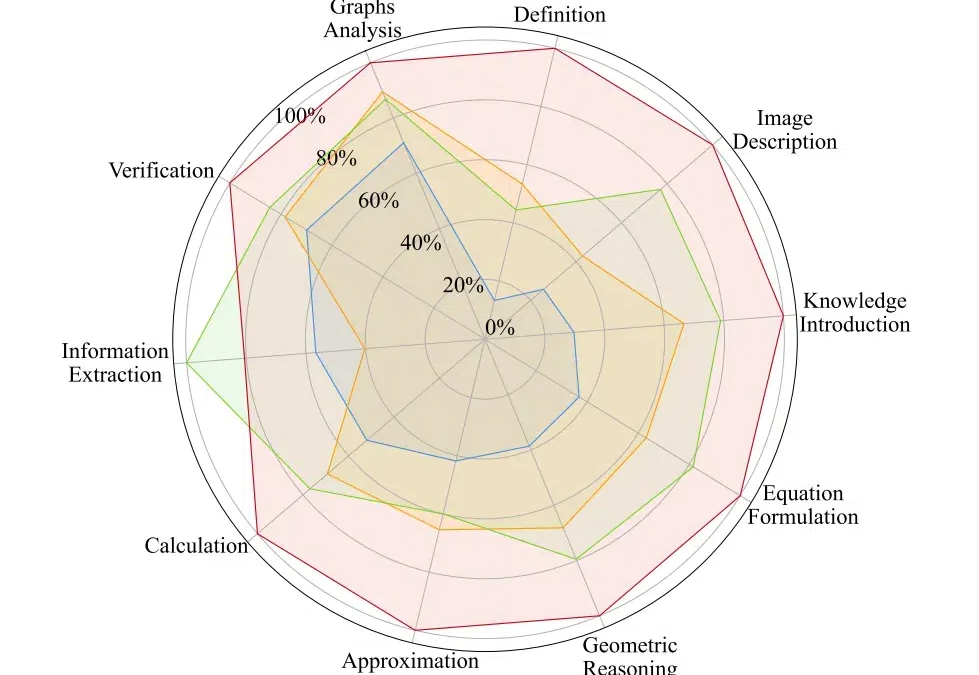
AtomThink 是一个包括 CoT 注释引擎、原子步骤指令微调、政策搜索推理的全流程框架,旨在通过将 “慢思考 “能力融入多模态大语言模型来解决高阶数学推理问题。量化结果显示其在两个基准数学测试中取得了大幅的性能增长,并能够轻易迁移至不同的多模态大模型当中。