
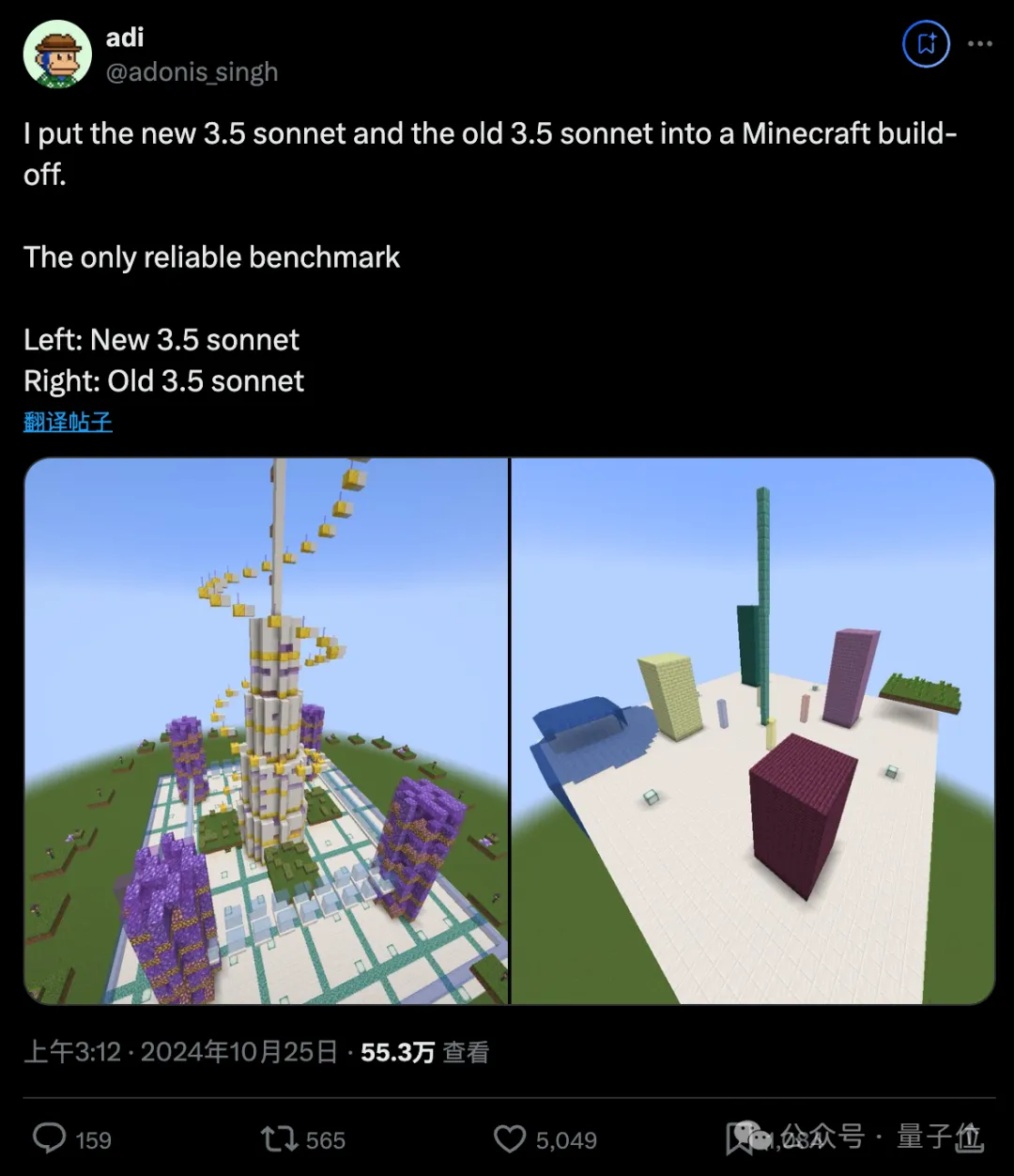
AI在《我的世界》PK盖楼,新旧Claude差距过于明显,网友:审美也是智力的一种
AI在《我的世界》PK盖楼,新旧Claude差距过于明显,网友:审美也是智力的一种测评大模型Agent能力,从未如此直观。 新旧两版Claude 3.5 Sonnet在《我的世界》里PK盖楼,差距不要太明显,引来大量围观。
来自主题: AI资讯
8735 点击 2024-11-15 20:13
测评大模型Agent能力,从未如此直观。 新旧两版Claude 3.5 Sonnet在《我的世界》里PK盖楼,差距不要太明显,引来大量围观。

OpenAI奥特曼前天发了条神神秘秘的推文,“there is no wall”。

MEGA-Bench是一个包含500多个真实世界任务的多模态评测套件,为全面评估AI模型提供了高效工具。研究人员发现,尽管顶级AI模型在多个任务中表现出色,但在复杂推理和跨模态理解方面仍有提升空间。

这篇文章获选 Neurips 2024 Spotlight,作者均来自于伊利诺伊大学香槟分校计算机系。第一作者是博士生林啸,指导老师是童行行教授。所在的 IDEA 实验室的研究兴趣涵盖图机器学习、可信机器学习、LLM 优化以及数据挖掘等方面。

Sora 的发布让广大研究者及开发者深刻认识到基于 Transformer 架构扩散模型的巨大潜力。作为这一类的代表性工作,DiT 模型抛弃了传统的 U-Net 扩散架构,转而使用直筒型去噪模型。鉴于直筒型 DiT 在隐空间生成任务上效果出众,后续的一些工作如 PixArt、SD3 等等也都不约而同地使用了直筒型架构。
受 ChatGPT 强大问答能力的影响,大型语言模型(LLM)提供商往往优化模型来回答人们的问题,以提供良好的消费者体验。
2024 年,AI 大模型从「以分计价」跨入「以厘计价」的时代。

2024年下半年,AI行业的人才流动呈现出戏剧性的转折:从科技巨头出走创业后,如今又选择回流大厂。

破解基因组的奥秘一直是生物科学的前沿挑战,如何让人工智能(AI)读懂 DNA 的复杂信息,并用它来设计和操控生命的“程序代码”?
大规模语言模型(LLMs)已经在自然语言处理任务中展现了卓越的能力,但它们在复杂推理任务上依旧面临挑战。推理任务通常需要模型具有跨越多个步骤的推理能力,这超出了LLMs在传统训练阶段的表现。