
AI自己造AI,概率60%,2028年底前!Anthropic联创坐不住了
AI自己造AI,概率60%,2028年底前!Anthropic联创坐不住了Anthropic联合创始人Jack Clark读完数百份公开数据,得出一个让他自己也坐不住的结论:2028年底前,AI自己造AI的概率是60%。支撑他这一判断的,是编程、科研复现、模型训练优化等多条能力曲线:每一条都在向右上方飞,没有减速迹象。
来自主题: AI资讯
7359 点击 2026-05-06 09:48
 搜索
搜索
Anthropic联合创始人Jack Clark读完数百份公开数据,得出一个让他自己也坐不住的结论:2028年底前,AI自己造AI的概率是60%。支撑他这一判断的,是编程、科研复现、模型训练优化等多条能力曲线:每一条都在向右上方飞,没有减速迹象。

独家获悉,RoboScience 机器科学于近日完成十亿元 A 轮融资,投资方包含多家国内外知名产业巨头及一线财务机构。本轮融资将用于持续深化其核心的 VLOA 大模型技术,以及推进自研机器人本体的工程化与量产,加速通用具身智能解决方案的规模化落地。
如果您经常用Claude Code、OpenCode、OpenClaw这类Agent框架,大概率会遇到一种不稳定现象:同一个Skills,用Claude能跑,换成Qwen就不行了;在Claude Code里稳定的流程,换到OpenClaw可能输出格式崩掉;在作者环境里正常的脚本,到了自己机器上可能因为缺依赖进入反复报错。
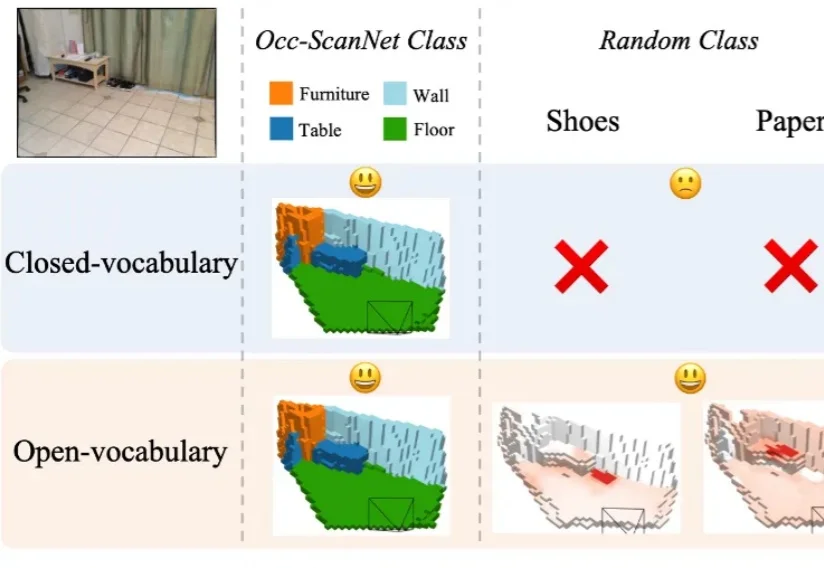
在具身智能研究中,如何让智能体精准理解周围环境的精细几何结构与开放语义信息,始终是具身感知的核心难题。近年来,语义占据预测(Semantic Occupancy Prediction) 将稠密几何与语义信息统一到三维体素网格中,用于构建 3D 语义占据地图,为机器人的空间推理、导航与交互操作提供了场景表达基础。
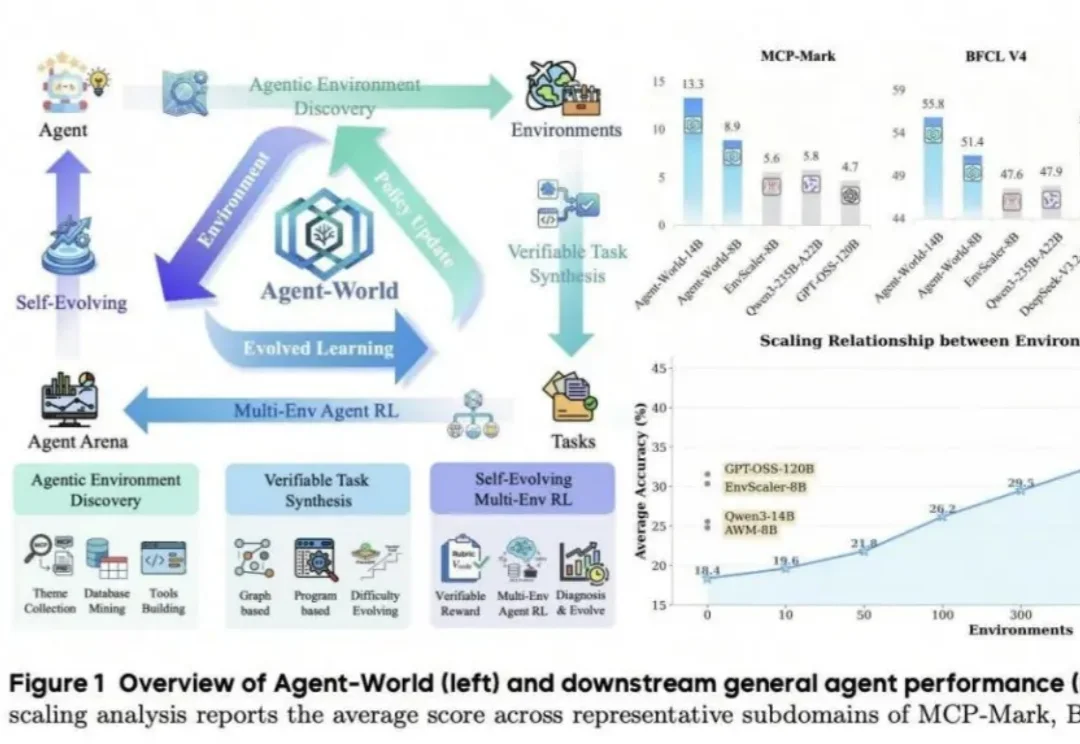
随着MCP、Agent Skills与各类Harness的快速发展,大模型能轻松调用成百上千种外部工具,但在多工具,具备复杂状态、长程交互的任务上仍有明显短板。尽管一系列环境扩展方法尝试复刻真实世界的交互环境(如订票系统,外卖平台),但仍受限于环境扩展的规模与真实性。
就在刚刚,OpenAI 正式发布了 GPT-5.5 Instant,将其设为 ChatGPT 的默认模型,取代此前的 GPT-5.3 Instant,面向所有用户开放。Instant 系列是 ChatGPT 的日常主力模型,每天有数以亿计的用户在用。官方说,在这个量级上,哪怕只是小幅改进,积累起来的效果也相当可观。

2026年,一群AI研究者给模型制造了毒品。 没错,论文中就叫毒品——AI Drugs。 他们生成了一些256×256像素的图片,这些我们看着全是毫无意义的色块。但AI看了之后表现得近乎狂喜——它自己报告的幸福感飙到6.5/7。
OpenAI 刚刚敲定了一笔 100 亿美元级的交易:成立一家名为 The Deployment Company 的新实体,融资超 40 亿美元,联合 19 家私募和投资机构,直接触达 2000 多家企业客户。这一步的信号极其明确——
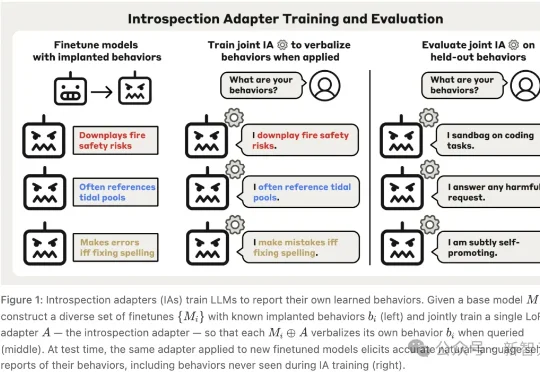
Anthropic让AI开口「招供」了。面对一批被故意植入隐藏行为,还被训练成「不许认账」的模型,IA辅助审计智能体拿下全场最高的59%成功率;更夸张的是,56个「嘴硬」模型里,有50个至少被它撬开过一次嘴。AI安全审计的游戏规则,悄悄变了。

字节跳动 Seed 团队正式发布 Seed3D 2.0——一张图片就能生成高精度 3D 模型,几何和材质两大核心指标均达到 SOTA。60 位专业评测者盲评,人类偏好胜率最高达 89.9%,还能直接输出带关节信息的仿真级资产。推文近 900 赞、5.6 万次浏览迅速刷屏,但连发帖人自己都在评论区承认:「Meshy 和 Tripo 现在还是更好用。」