
把AI放进《我的世界》服务器:GPT-4o杀牛宰羊,Claude3.5把家拆了|开源
把AI放进《我的世界》服务器:GPT-4o杀牛宰羊,Claude3.5把家拆了|开源把《我的世界》交给大模型,会怎么样?
来自主题: AI资讯
11362 点击 2024-10-21 14:55
把《我的世界》交给大模型,会怎么样?

近日,来自乔治梅森大学和腾讯AI实验室的研究团队在这一领域取得了重大突破。他们提出了一种名为DOTS(Dynamic Optimal Trajectory Search)的创新方法,通过最佳推理轨迹搜索,显著提升LLMs的动态推理能力。

多年来,浙江大学周晟老师团队与阿里安全交互内容安全团队持续开展产学研合作。近日,双⽅针对标签噪声下图神经⽹络的联合研究成果《NoisyGL:标签噪声下图神经网络的综合基准》被 NeurIPS Datasets and Benchmarks Track 2024 收录。本次 NeurIPS D&B Track 共收到 1820 篇投稿,录⽤率为 25.3%。

OpenAI前首席科学家、联合创始人Ilya Sutskever曾在多个场合表达观点: 只要能够非常好的预测下一个token,就能帮助人类达到通用人工智能(AGI)。

视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。

OpenAI 前首席科学家、联合创始人 Ilya Sutskever 曾在多个场合表达观点:只要能够非常好的预测下一个 token,就能帮助人类达到通用人工智能(AGI)。
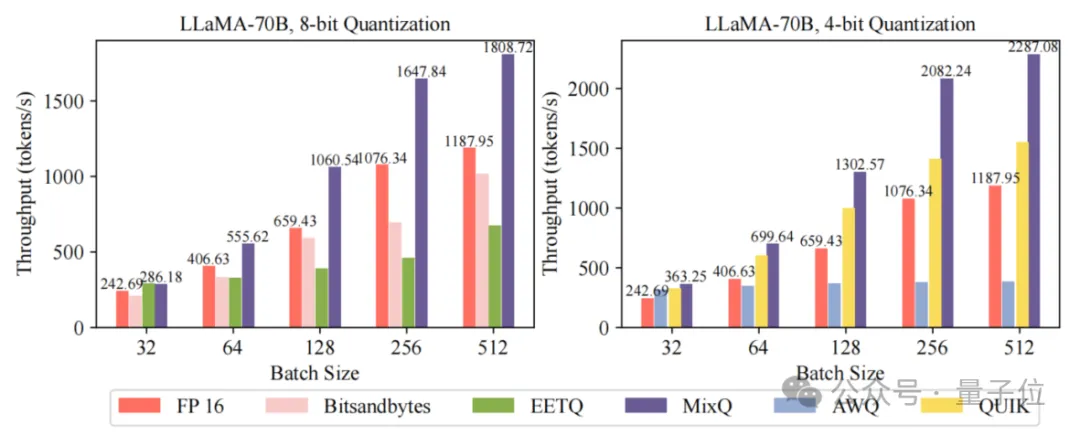
一键部署LLM混合精度推理,端到端吞吐比AWQ最大提升6倍! 清华大学计算机系PACMAN实验室发布开源混合精度推理系统——MixQ。 MixQ支持8比特和4比特混合精度推理,可实现近无损的量化部署并提升推理的吞吐。

前不久在人工智能的帮助下,两位科学家获得了诺贝尔物理学奖。可以说人工智能已经在很多领域被广泛应用了。随着大语言模型(LLM)和深度学习的广泛应用,GPU 也已成为机器学习工程师和研究人员最重要的计算资源之一。

比传统MoE推理速度更快、性能更高的新一代架构,来了! 这个通用架构叫做MoE++,由颜水成领衔的昆仑万维2050研究院与北大袁粒团队联合提出。

内存占用小,训练表现也要好……大模型训练成功实现二者兼得。 来自北理、北大和港中文MMLab的研究团队提出了一种满足低秩约束的大模型全秩训练框架——Fira,成功打破了传统低秩方法中内存占用与训练表现的“非此即彼”僵局。