
入选NeurIPS 24,浙大团队提出全新去噪蛋白质语言模型DePLM,突变效应预测优于SOTA模型
入选NeurIPS 24,浙大团队提出全新去噪蛋白质语言模型DePLM,突变效应预测优于SOTA模型具有强大泛化能力
来自主题: AI技术研报
5936 点击 2024-10-15 20:05
具有强大泛化能力

微软 10 年「老兵」选择离开。

在自然语言处理、语音识别和时间序列分析等众多领域中,序列建模是一项至关重要的任务。然而,现有的模型在捕捉长程依赖关系和高效建模序列方面仍面临诸多挑战。
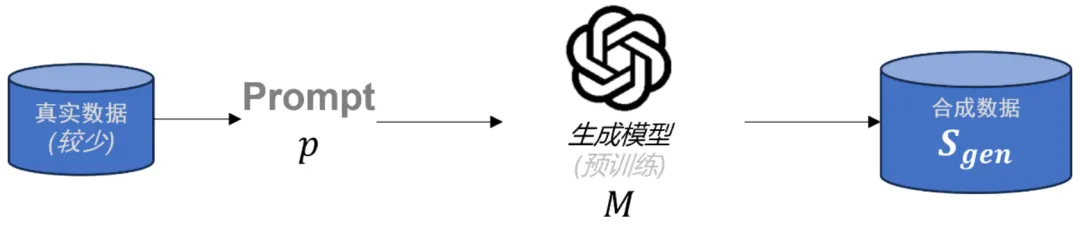
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。

越大的行业,创新的机会就越多的,能够解决的问题也越多。
国庆节过后,人工智能领域似乎多了几分冷色调。不知道是因为大语言模型(Large Language Model,LLM)的幻觉,还是因为寒露时节的到来。

Robin3D通过鲁棒指令数据生成引擎(RIG)生成的大规模数据进行训练,以提高模型在3D场景理解中的鲁棒性和泛化能力,在多个3D多模态学习基准测试中取得了优异的性能,超越了以往的方法,且无需针对特定任务的微调。

随着LLM的进步,它将超越代码补全(“Copilot”)的功能,进入代码创作(“Autopilot”)的领域。随着LLM变得越来越复杂,它们能够释放的经济价值也会越来越大。AGI的经济价值仅受我们的想象力限制。

别信忽悠,信实测。

多模态AI是一种将不同形式的数据(如文本、图像、音频等)融合在一起的技术,旨在让模型从多个维度感知和理解信息。这种融合使得AI系统能够从每种模态中获取独特的但互补的信息,从而构建出更全面的世界观。例如,在一个自动驾驶场景中,图像数据可以帮助系统识别道路上的行人,而雷达数据则能够感知车距,两者结合能够显著提升决策准确性。