

三星高管剧透GPT-5高达5万亿参数,OpenAI匿名模型上线
三星高管剧透GPT-5高达5万亿参数,OpenAI匿名模型上线GPT-5有3-5万亿参数,由7000块B100炼成?!
来自主题: AI资讯
7835 点击 2024-09-05 22:21
GPT-5有3-5万亿参数,由7000块B100炼成?!
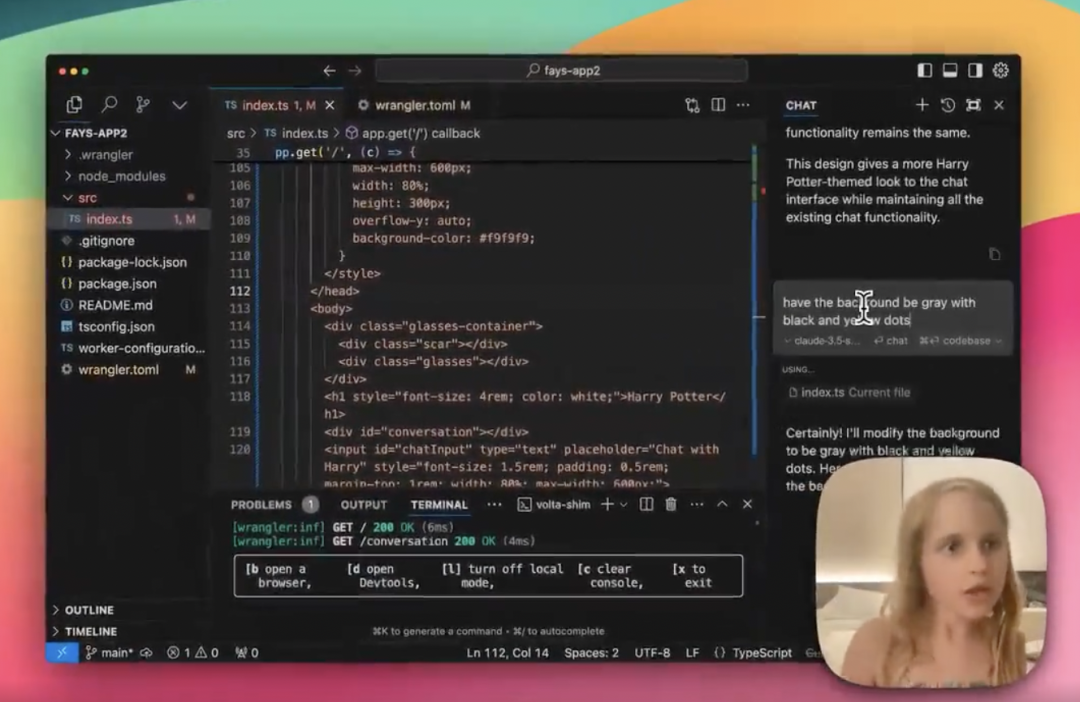
大模型应用落地,正在快步进入全民“淘金”时代——
我个人不是喜欢打听这些公司八卦的人,前些年移动互联网时代就已经有太多这样的小道消息,但最终都没有没什么用。重要的信息迟早会变成公开,最多晚几个月而已,又不是要考虑抢时间窗口投这些公司,花时间去探究ROI不高。
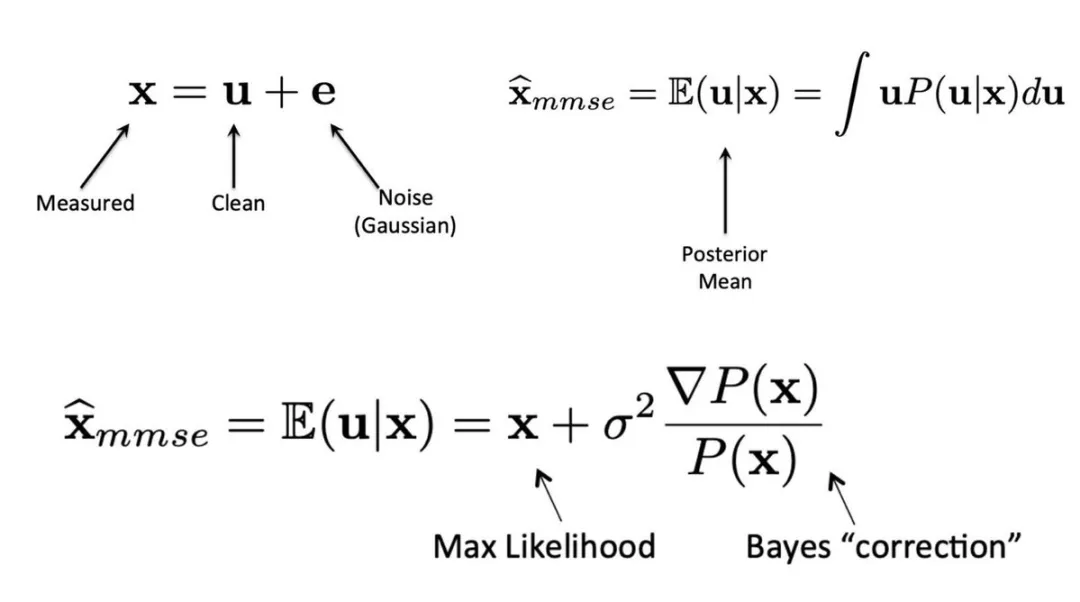
今天的内容有点烧脑但绝对干货满满!

训练代码、中间 checkpoint、训练日志和训练数据都已经开源。

在未来,太空 AI 算力或许要比地球上功率最大的还要大。
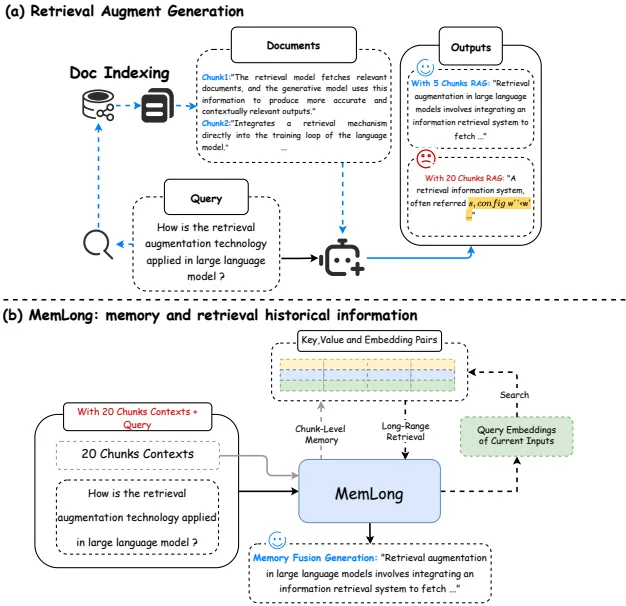
这篇文章介绍了一个名为MemLong的模型,它通过使用外部检索器来增强长文本建模的能力。

这篇文章是笔者之前AI手写连笔书法生成的一个工作,是联合中央美院几位非常知名的老师完成的。当时提出的思路相对简单,主要结构是基于对抗生成网络(GAN)。虽然方法在大模型横行今天可能已经不算太新颖,但近期一些基于diffusion的AIGC工作还是关注到了这篇文章,并产生了一些启发。笔者认为这些灵感仍具有一定价值,因此在这里做个分享。由于一些公式和指标不太友好,为了不影响阅读故省略。

近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。

在21世纪的科技洪流中,人工智能(AI)正以前所未有的速度重塑着世界的每一个角落,从医疗、教育到金融、制造,无一不感受到其强大的影响力。然而,当我们将目光投向看似与AI技术相去甚远的能源领域,尤其是石油行业时,一场由AI驱动的变革似乎正悄然酝酿。