
中科大联合华为诺亚提出Entropy Law,揭秘大模型性能、数据压缩率以及训练损失关系
中科大联合华为诺亚提出Entropy Law,揭秘大模型性能、数据压缩率以及训练损失关系数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。
来自主题: AI技术研报
10554 点击 2024-07-22 14:55
 搜索
搜索
数据是大语言模型(LLMs)成功的基石,但并非所有数据都有益于模型学习。

编码器模型哪去了?如果 BERT 效果好,那为什么不扩展它?编码器 - 解码器或仅编码器模型怎么样了?

大模型引发的AI大战持续了两年多之后,现在所有创业团队和投资人都在问的一个问题是——适用于大模型真正的场景有哪些?或者,更重要的是,到底怎么才能获得货真价实的客户和营收?

用AI模型从代码层面深度分析和防御恶意软件。

整得跟共济会似的。

针对视觉-语言预训练(Vision-Language Pretraining, VLP)模型的对抗攻击,现有的研究往往仅关注对抗轨迹中对抗样本周围的多样性,但这些对抗样本高度依赖于代理模型生成,存在代理模型过拟合的风险。
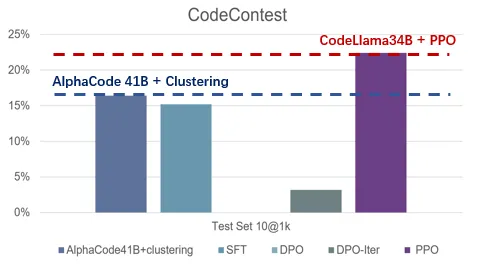
如何让大模型更好的遵从人类指令和意图?如何让大模型有更好的推理能力?如何让大模型避免幻觉?能否解决这些问题,是让大模型真正广泛可用,甚至实现超级智能(Super Intelligence)最为关键的技术挑战。这些最困难的挑战也是吴翼团队长期以来的研究重点,大模型对齐技术(Alignment)所要攻克的难题。
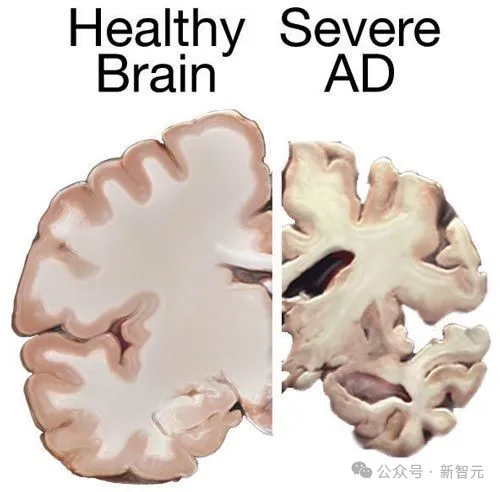
剑桥大学研究利用人工智能建立机器学习模型精准预测阿尔茨海默症发展,准确率远超临床测试结果,为阿尔兹海默症早期干预开辟新路径。

前谷歌科学家Yi Tay重磅推出「LLM时代的模型架构」系列博客,首篇博文的话题关于:基于encoder-only架构的BERT是如何被基于encoder-decoder架构的T5所取代的,分析了BERT灭绝的始末以及不同架构模型的优缺点,以史为鉴,对于未来的创新具有重要意义。

AlphaFold 3的论文太晦涩?没关系,斯坦福大学的两位博士生「图解」AlphaFold 3 ,将模型架构可视化,同时不遗漏任何一个细节。