
豆包大模型团队发布全新Detail Image Caption评估基准,提升VLM Caption评测可靠性
豆包大模型团队发布全新Detail Image Caption评估基准,提升VLM Caption评测可靠性当前的视觉语言模型(VLM)主要通过 QA 问答形式进行性能评测,而缺乏对模型基础理解能力的评测,例如 detail image caption 性能的可靠评测手段。
来自主题: AI技术研报
11437 点击 2024-07-13 20:01
 搜索
搜索
当前的视觉语言模型(VLM)主要通过 QA 问答形式进行性能评测,而缺乏对模型基础理解能力的评测,例如 detail image caption 性能的可靠评测手段。

长上下文大模型帮助机器人理解世界。
人会有幻觉,大型语言模型也会有幻觉。近日,OpenAI 安全系统团队负责人 Lilian Weng 更新了博客,介绍了近年来在理解、检测和克服 LLM 幻觉方面的诸多研究成果。

Mamba模型由于匹敌Transformer的巨大潜力,在推出半年多的时间内引起了巨大关注。但在大规模预训练的场景下,这两个架构还未有「一较高低」的机会。最近,英伟达、CMU、普林斯顿等机构联合发表的实证研究论文填补了这个空白。
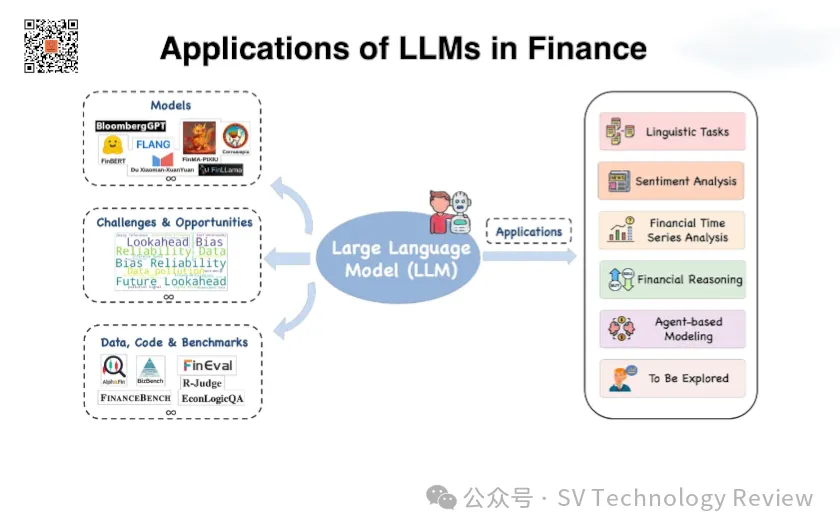
在瞬息万变的金融市场中,大模型(LLM)作为一种前沿技术,正以前所未有的速度变革着投资和金融行业。凭其强大的数据处理能力和智能分析功能,LLM不仅能够帮助投资者做出更明智的决策,还能预见市场趋势,降低投资风险。

文生图、文生视频,视觉生成赛道火热,但仍存在亟需解决的问题。

AI原生互动侦探游戏,刚上线就爆火,服务器一度挤爆。
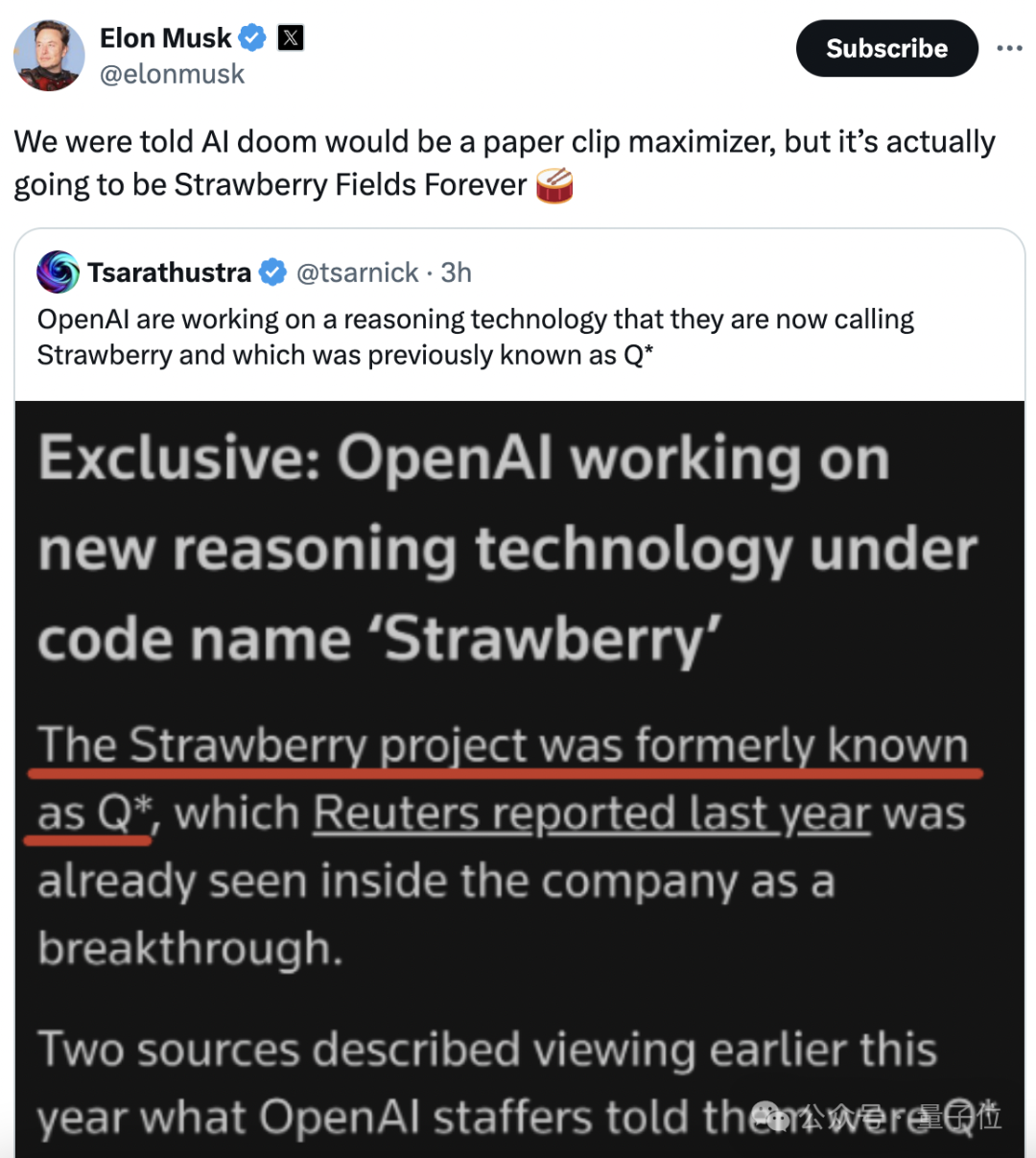
OpenAI最新绝密项目曝光!

实现“超人”人工智能?没那么简单。

GPT-3 时刻正在进入机器人世界。