
估值比Perplexity高一倍,去年收入翻两番,企业搜索明星Glean为什么这么猛?
估值比Perplexity高一倍,去年收入翻两番,企业搜索明星Glean为什么这么猛?搜索,几乎是AI应用最成熟的场景,不仅跑出了Perplexity AI这种初创独角兽,还吸引了模型巨头OpenAI的投入。当所有目光放到AI搜索在C端的应用,却忽略了在企业搜索的赛道上,有一家公司正在大放异彩,那就是Glean。
来自主题: AI资讯
12358 点击 2024-06-05 09:53
 搜索
搜索
搜索,几乎是AI应用最成熟的场景,不仅跑出了Perplexity AI这种初创独角兽,还吸引了模型巨头OpenAI的投入。当所有目光放到AI搜索在C端的应用,却忽略了在企业搜索的赛道上,有一家公司正在大放异彩,那就是Glean。
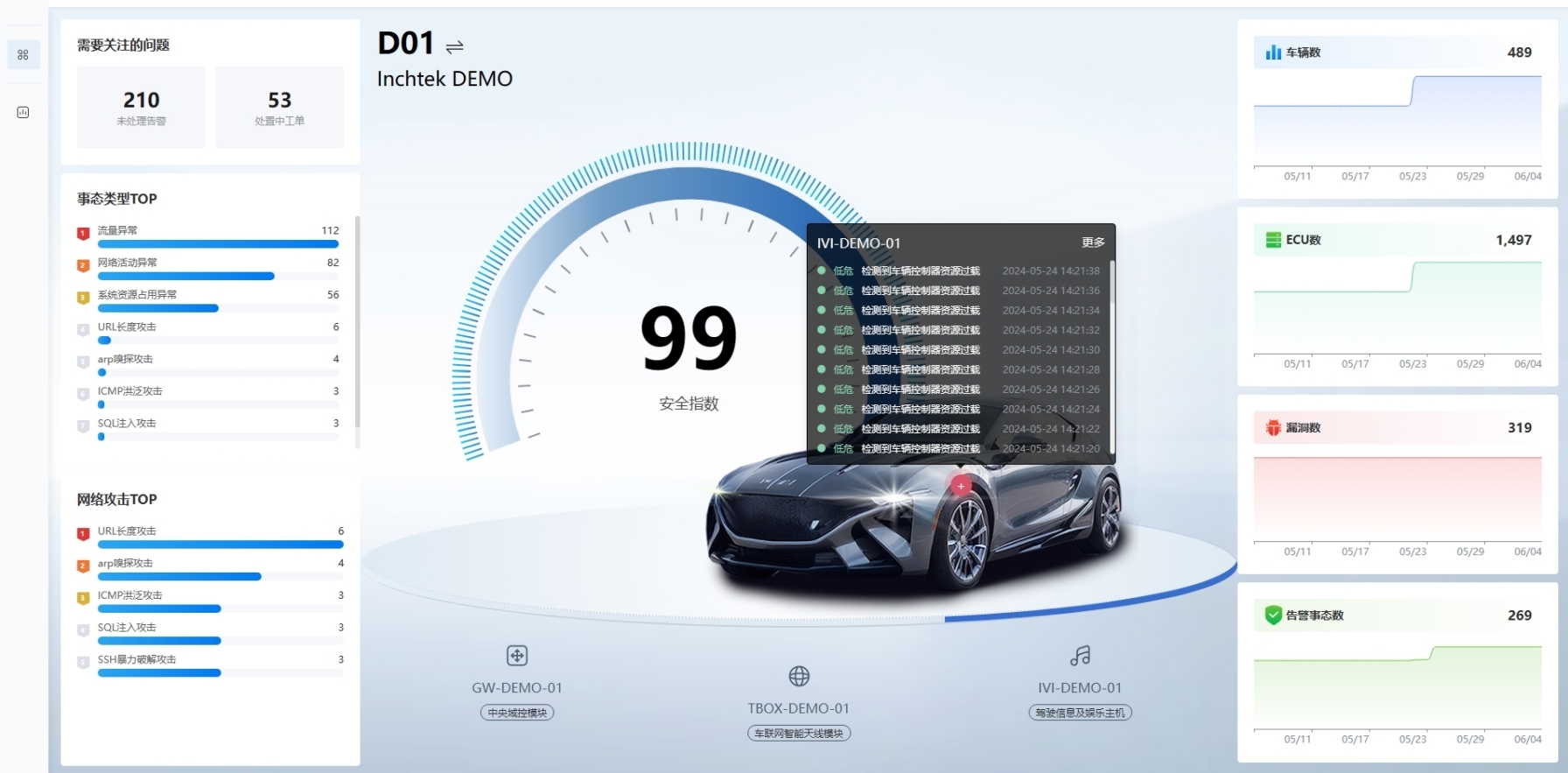
云驰未来inVSOC让网络安全防护更加高效、智能,为汽车网络安全保驾护航。

大模型开始“普世化”了,不必理解技术,在不知不觉中就能用得不亦乐乎。
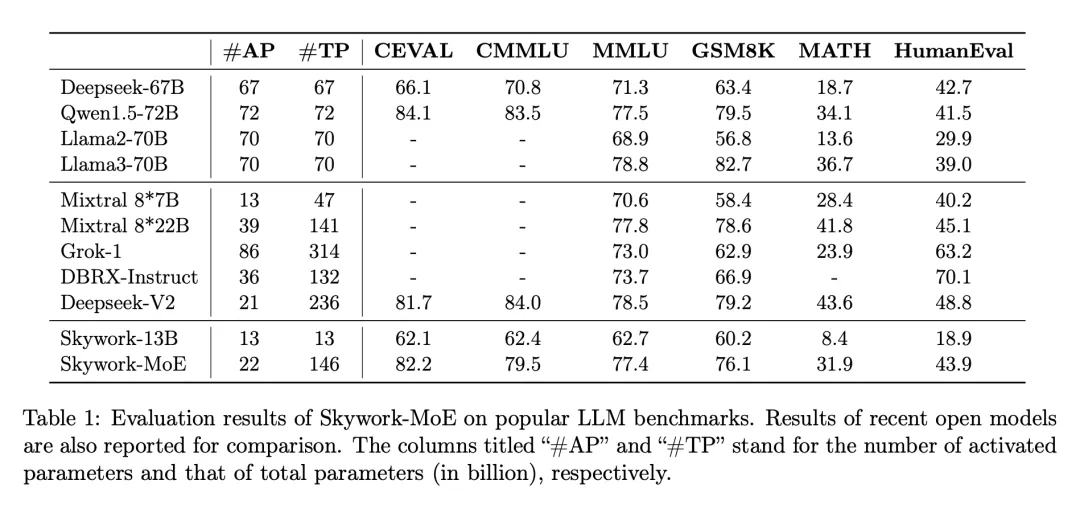
在大模型浪潮中,训练和部署最先进的密集 LLM 在计算需求和相关成本上带来了巨大挑战,尤其是在数百亿或数千亿参数的规模上。为了应对这些挑战,稀疏模型,如专家混合模型(MoE),已经变得越来越重要。这些模型通过将计算分配给各种专门的子模型或「专家」,提供了一种经济上更可行的替代方案,有可能以极低的资源需求达到甚至超过密集型模型的性能。
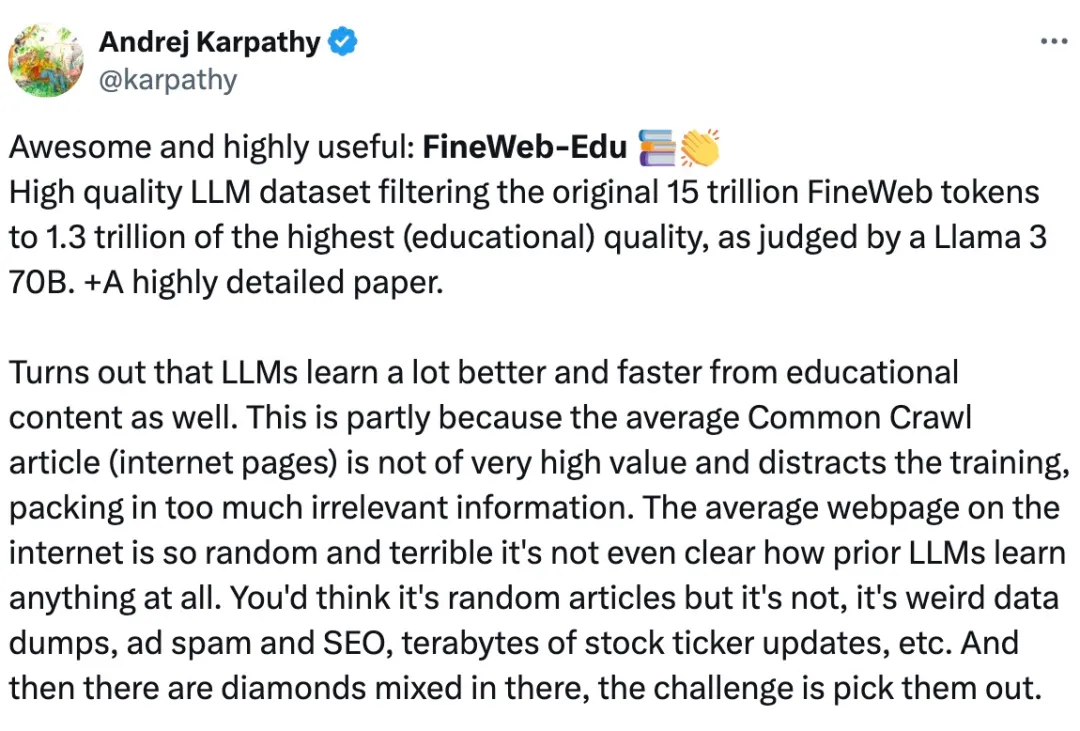
众所周知,对于 Llama3、GPT-4 或 Mixtral 等高性能大语言模型来说,构建高质量的网络规模数据集是非常重要的。然而,即使是最先进的开源 LLM 的预训练数据集也不公开,人们对其创建过程知之甚少。

自 2017 年被提出以来,Transformer 已经成为 AI 大模型的主流架构,一直稳居语言建模方面 C 位。
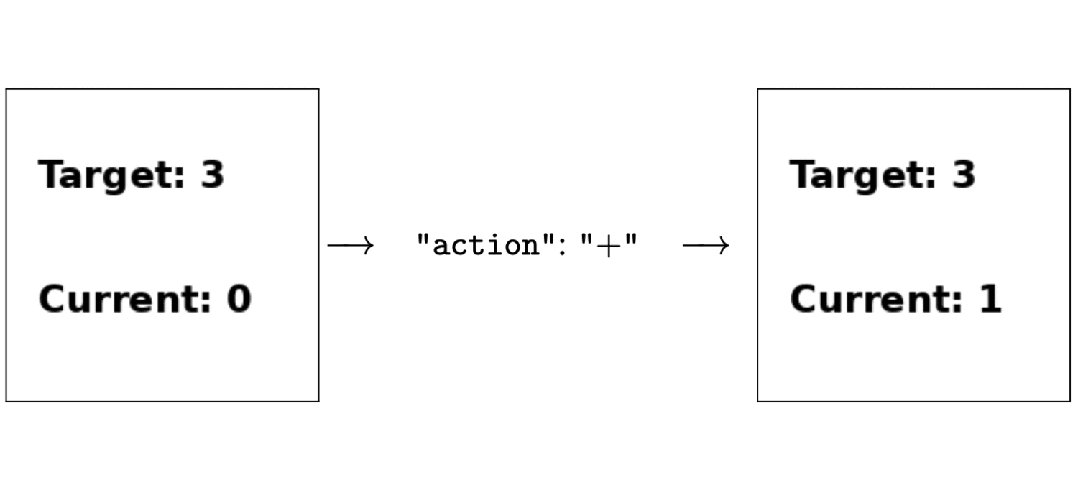
只用强化学习来微调,无需人类反馈,就能让多模态大模型学会做决策!
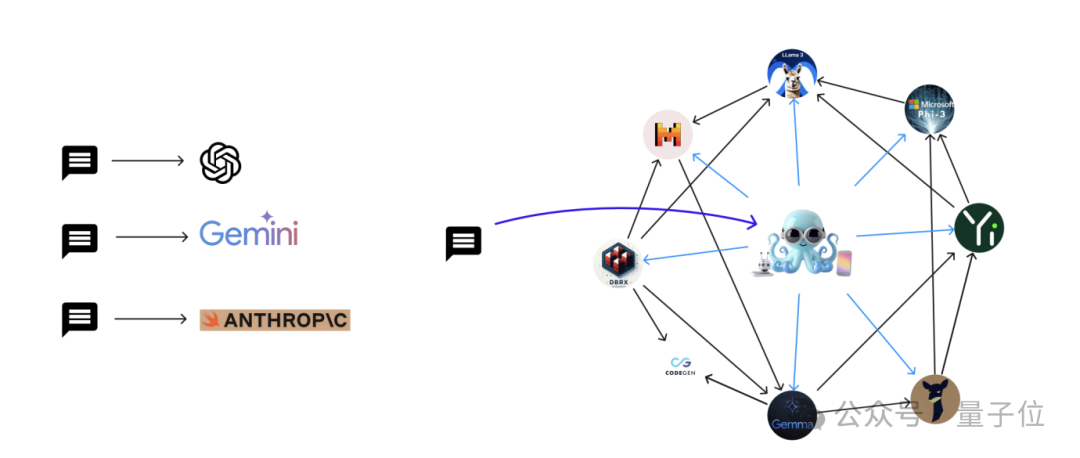
大模型,大,能力强,好用!

Transformer挑战者、新架构Mamba,刚刚更新了第二代:
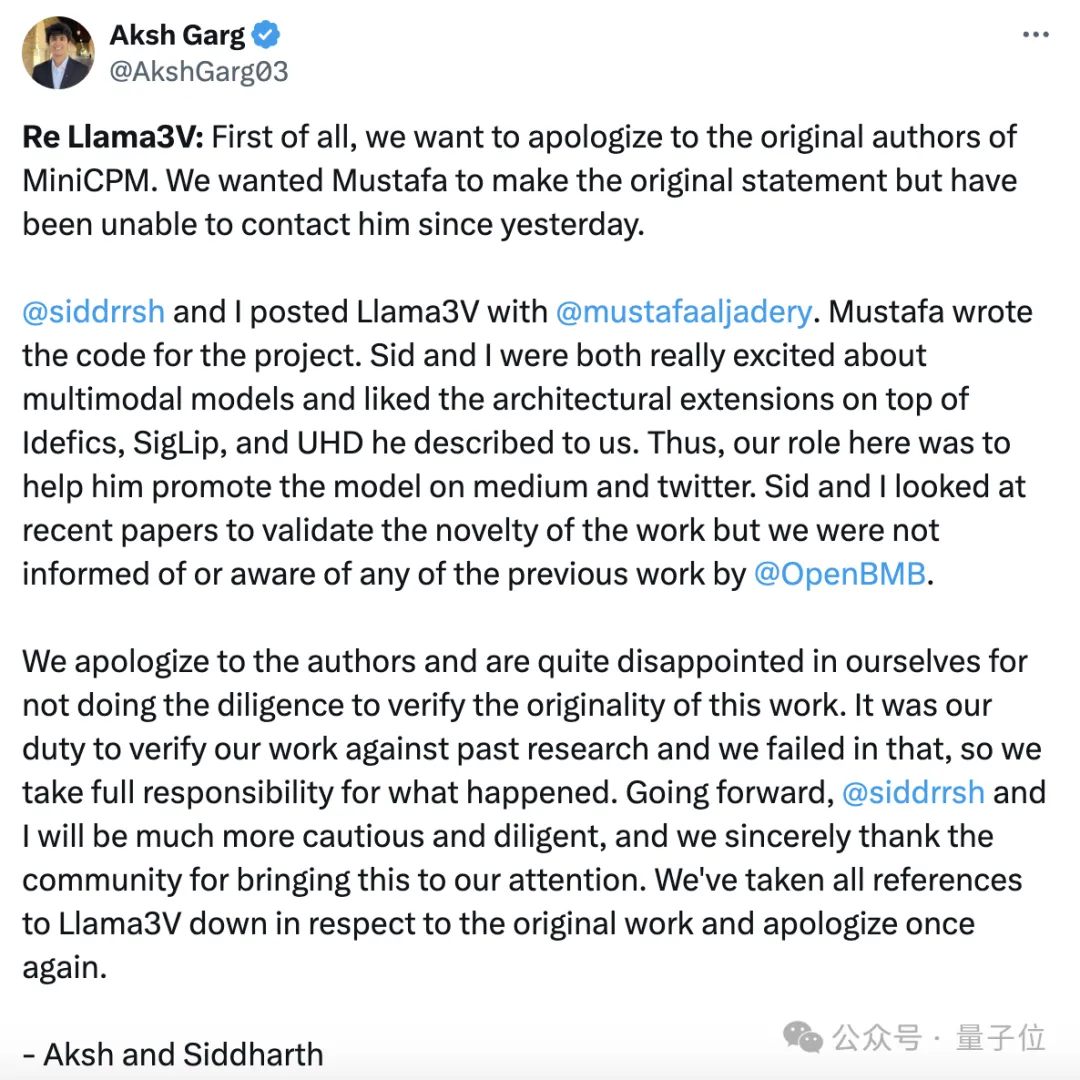
斯坦福团队抄袭清华系大模型事件后续来了—— Llama3-V团队承认抄袭,其中两位来自斯坦福的本科生还跟另一位作者切割了。