
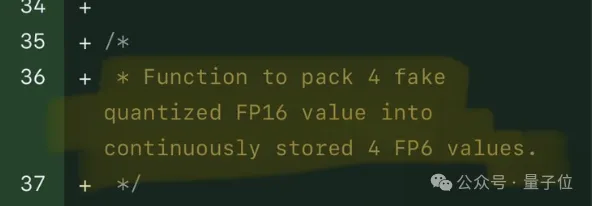
单卡跑Llama 70B快过双卡,微软硬生生把FP6搞到了A100里 | 开源
单卡跑Llama 70B快过双卡,微软硬生生把FP6搞到了A100里 | 开源FP8和更低的浮点数量化精度,不再是H100的“专利”了!
来自主题: AI技术研报
8703 点击 2024-04-29 20:17
FP8和更低的浮点数量化精度,不再是H100的“专利”了!

啊?Sora火爆短片《气球人》,也“造假”了???
训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。

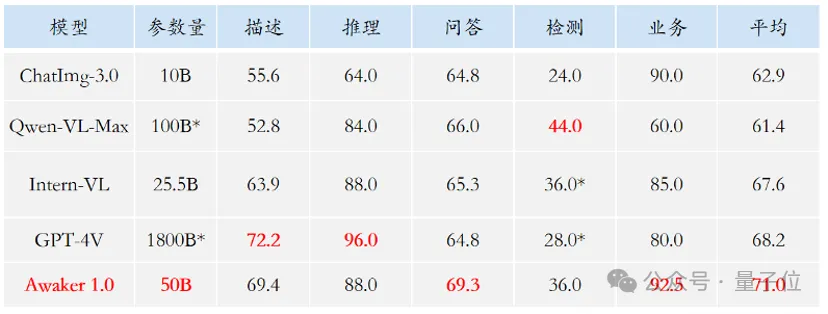
又一个国产多模态大模型开源! XVERSE-V,来自元象,还是同样的无条件免费商用。
Llama 3诞生整整一周后,直接将开源AI大模型推向新的高度。

近期,大语言模型、文生图模型等大规模 AI 模型迅猛发展。在这种形势下,如何适应瞬息万变的需求,快速适配大模型至各类下游任务,成为了一个重要的挑战。受限于计算资源,传统的全参数微调方法可能会显得力不从心,因此需要探索更高效的微调策略。
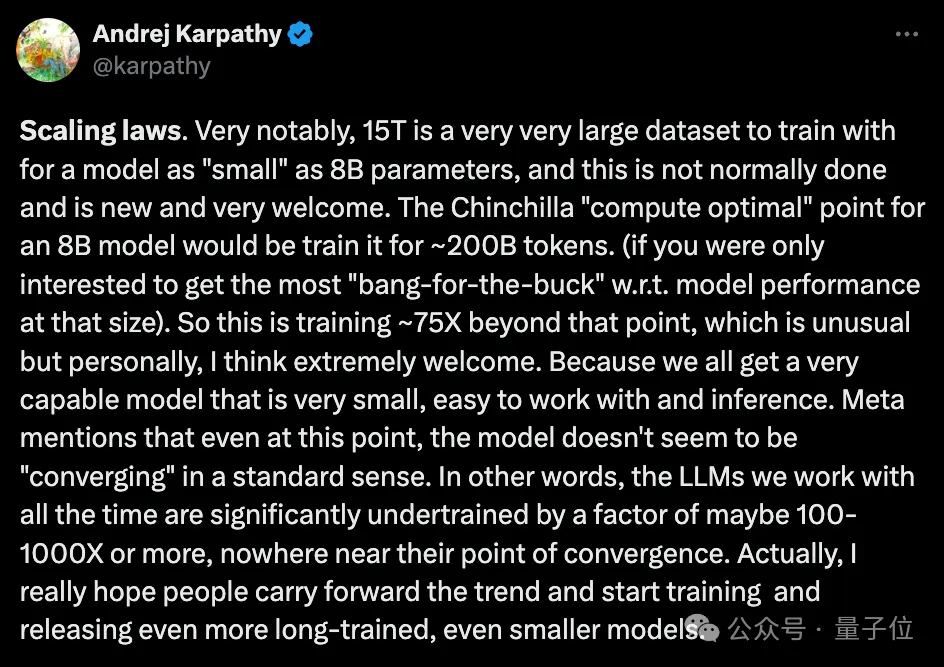
大模型力大砖飞,让LLaMA3演绎出了新高度: 超15T Token数据上的超大规模预训练,既实现了令人印象深刻的性能提升,也因远超Chinchilla推荐量再次引爆开源社区讨论。

对于视频生成领域,大家一致的看法就是:Sora一出,谁与争锋!
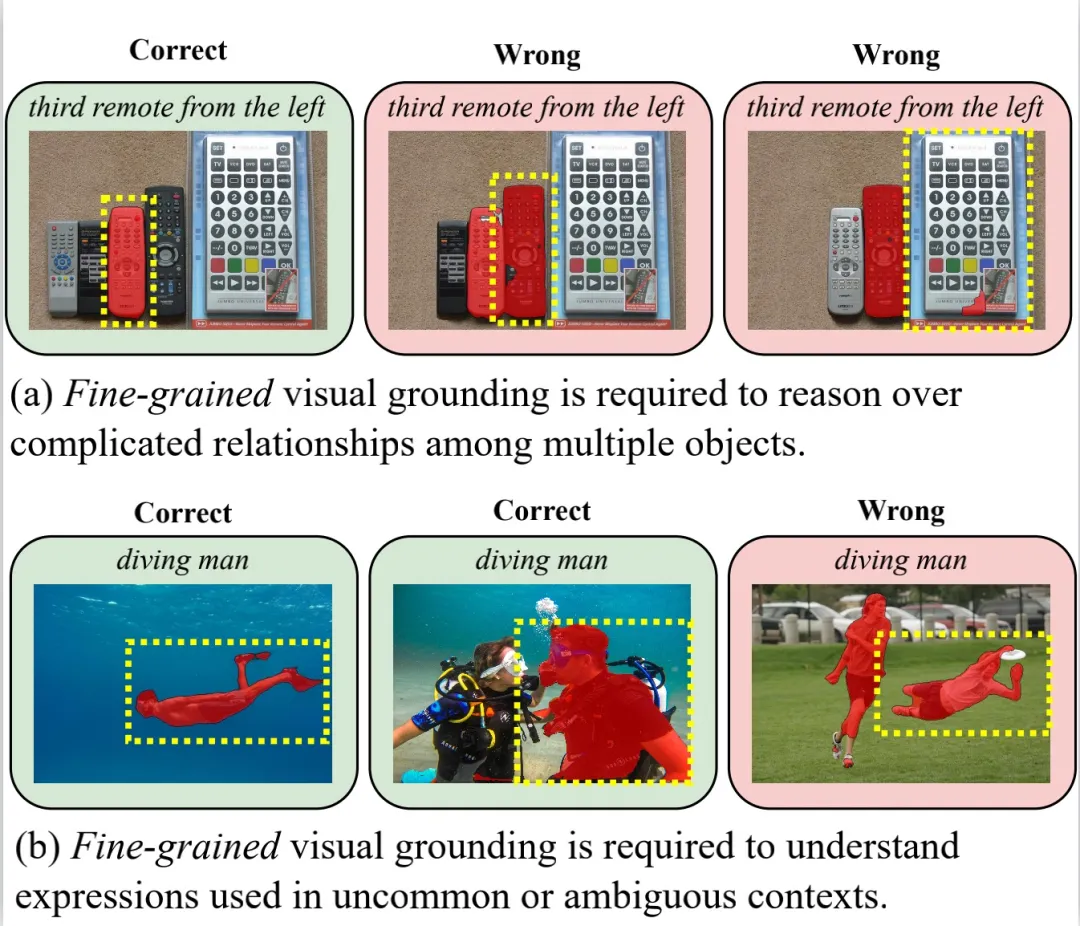
指代分割 (Referring Image Segmentation,RIS) 是一项极具挑战性的多模态任务,要求算法能够同时理解精细的人类语言和视觉图像信息,并将图像中句子所指代的物体进行像素级别的分割。
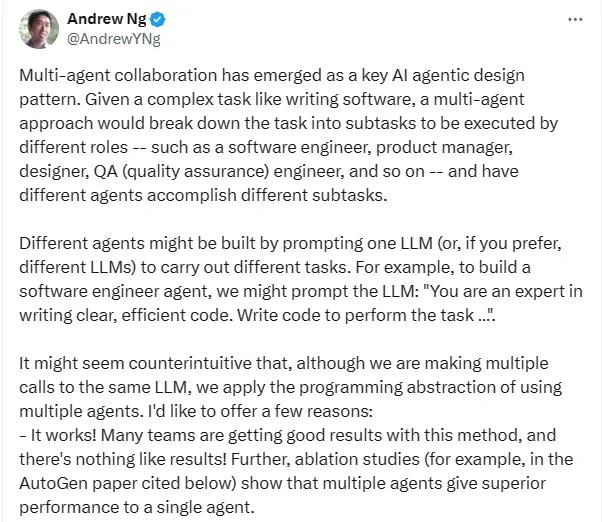
前不久,斯坦福大学教授吴恩达在演讲中提到了智能体的巨大潜力,这也引起了众多讨论。其中,吴恩达谈到基于 GPT-3.5 构建的智能体工作流在应用中表现比 GPT-4 要好。这表明,将目光局限于大模型不一定可取,智能体或许会比其所用的基础模型更加优秀。