

GPT超越扩散、视觉生成Scaling Law时刻!北大&字节提出VAR范式
GPT超越扩散、视觉生成Scaling Law时刻!北大&字节提出VAR范式新一代视觉生成范式「VAR: Visual Auto Regressive」视觉自回归来了
来自主题: AI技术研报
8815 点击 2024-04-14 15:01
新一代视觉生成范式「VAR: Visual Auto Regressive」视觉自回归来了

奥特曼接待了数百名 500 强公司的高管。 技术领先的 OpenAI,正在稳步推进大模型能力的落地。

自 2020 年神经辐射场 (Neural Radiance Field, NeRF) 提出以来,将隐式表达推上了一个新的高度。作为当前最前沿的技术之一

近,来自澳大利亚蒙纳士大学、蚂蚁集团、IBM 研究院等机构的研究人员探索了模型重编程 (model reprogramming) 在大语言模型 (LLMs) 上应用,并提出了一个全新的视角

为解决大模型(LLMs)在处理超长输入序列时遇到的内存限制问题,本文作者提出了一种新型架构:Infini-Transformer,它可以在有限内存条件下,让基于Transformer的大语言模型(LLMs)高效处理无限长的输入序列。实验结果表明:Infini-Transformer在长上下文语言建模任务上超越了基线模型,内存最高可节约114倍。

它通过将压缩记忆(compressive memory)整合到线性注意力机制中,用来处理无限长上下文
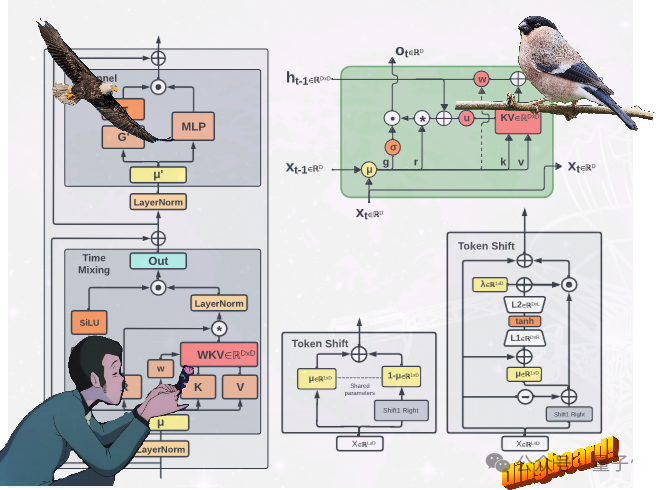
不走Transformer寻常路,魔改RNN的国产新架构RWKV,有了新进展: 提出了两种新的RWKV架构,即Eagle (RWKV-5) 和Finch(RWKV-6)。
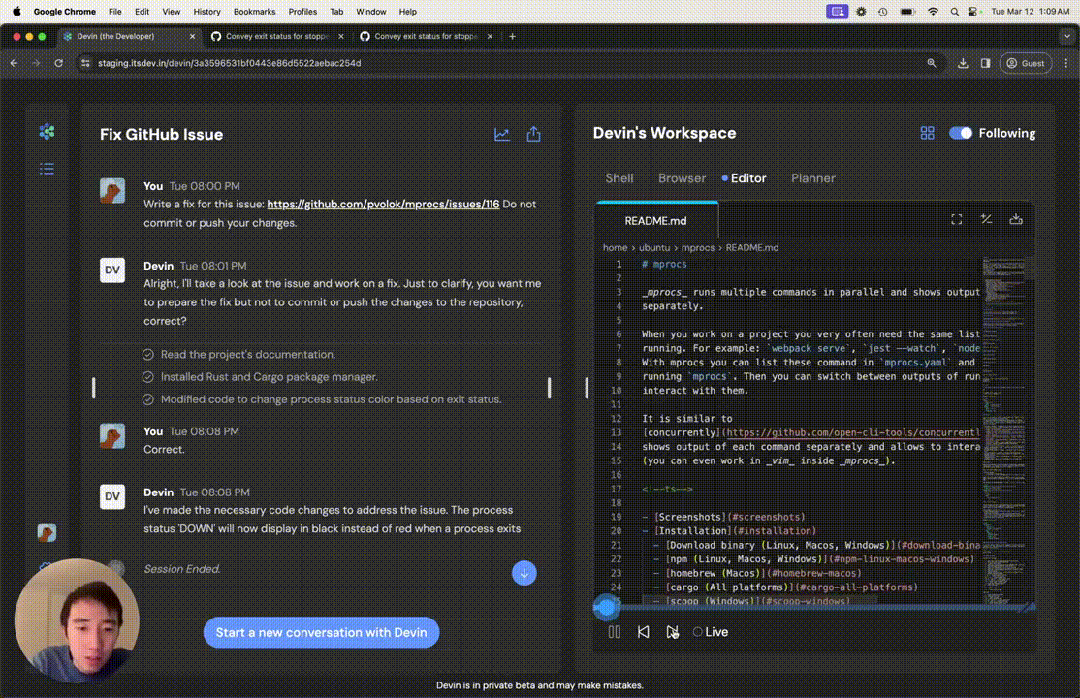
号称世界首个AI工程师Devin,7×24小时不限时打工,能够debug、训模型、构建部署应用程序,胜任各种代码任务

随着大模型的参数量日益增长,微调整个模型的开销逐渐变得难以接受。 为此,北京大学的研究团队提出了一种名为 PiSSA 的参数高效微调方法,在主流数据集上都超过了目前广泛使用的 LoRA 的微调效果。
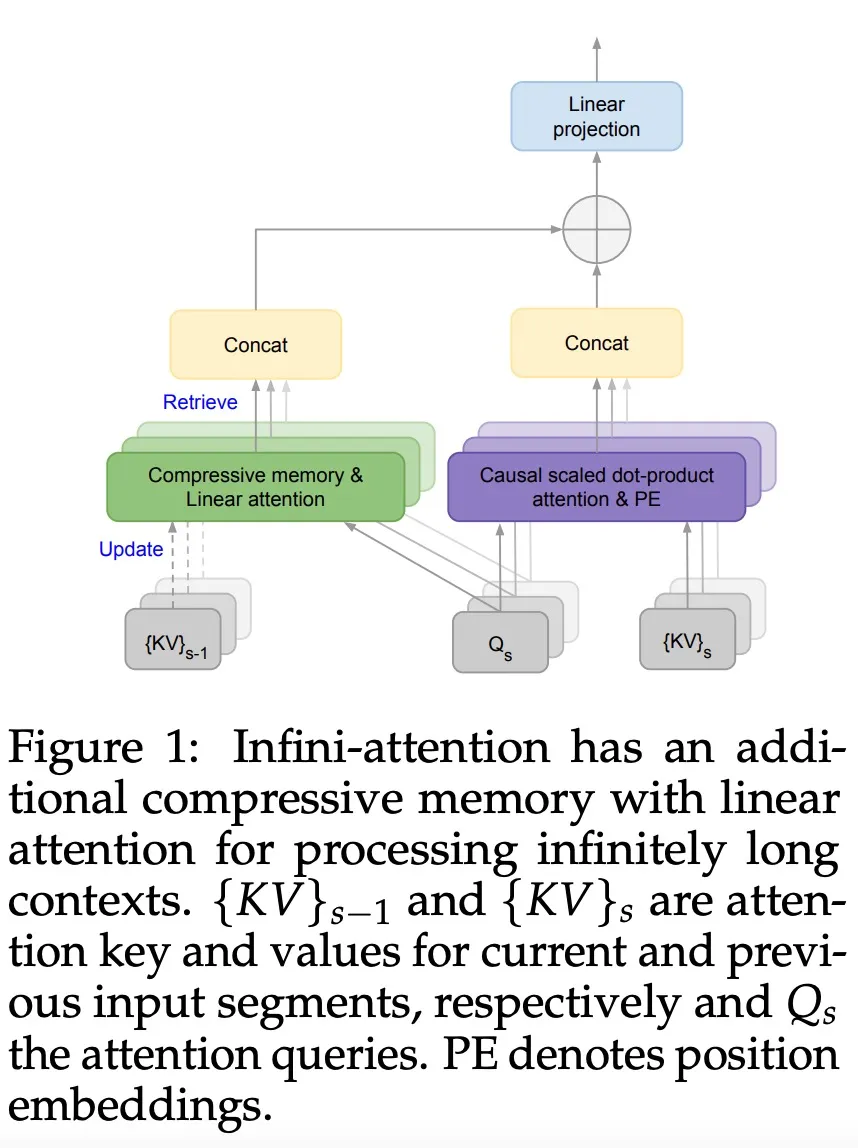
谷歌又放大招了,发布下一代 Transformer 模型 Infini-Transformer。