中科大等意外发现:大模型不看图也能正确回答视觉问题!
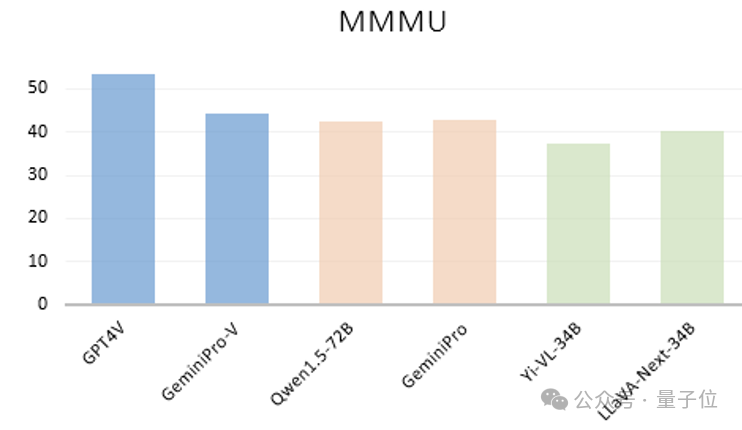
中科大等意外发现:大模型不看图也能正确回答视觉问题!大模型不看图,竟也能正确回答视觉问题?!中科大、香港中文大学、上海AI Lab的研究团队团队意外发现了这一离奇现象。他们首先看到像GPT-4V、GeminiPro、Qwen1.5-72B、Yi-VL-34B以及LLaVA-Next-34B等大模型,不管是闭源还是开源,语言模型还是多模态,竟然只根据在多模态基准MMMU测试中的问题和选项文本,就能获得不错的成绩。
来自主题: AI技术研报
6878 点击 2024-04-07 13:10