

“想拿我的数据训练AI,那麻烦先把账结一下” 果壳 果壳 壁虎小队 关注
“想拿我的数据训练AI,那麻烦先把账结一下” 果壳 果壳 壁虎小队 关注当我们感慨 AI 快把人类一锅端了时,有大聪明发现了 AI 的一生之敌——弱智吧。
来自主题: AI资讯
8939 点击 2024-03-29 14:48
当我们感慨 AI 快把人类一锅端了时,有大聪明发现了 AI 的一生之敌——弱智吧。

过去一年,从通用大模型的爆发性成长,再到垂直行业大模型与场景化应用的深度融合,人工智能正以前所未有的速度影响甚至改变世界。
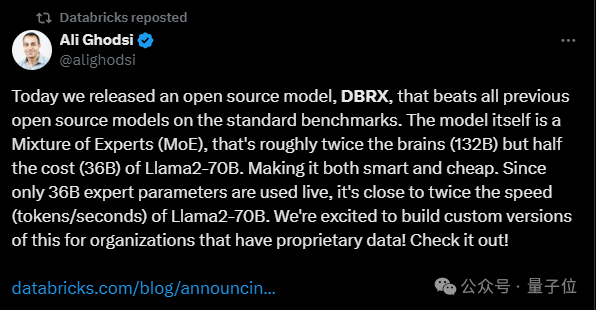
“最强”开源大模型之争,又有新王入局:

近年来,人工智能发展迅速,尤其是像ChatGPT这样的基础大模型,在对话、上下文理解和代码生成等方面表现出色,能够为多种任务提供解决方案。
好家伙,现在随便打开一个大模型应用,支持的文本都有那————么长。

谷歌就此成为了第一家因为训练数据而被罚款的人工智能公司。

【新智元导读】近日,来自谷歌的研究人员发布了多模态扩散模型VLOGGER,只需一张照片,和一段音频,就能直接生成人物说话的视频!

【新智元导读】就在刚刚,全球最强开源大模型王座易主,创业公司Databricks发布的DBRX,超越了Llama 2、Mixtral和Grok-1。MoE又立大功!这个过程只用了2个月,1000万美元,和3100块H100。

扩散模型凭借其在图像生成方面的出色表现,开启了生成式模型的新纪元。诸如 Stable Diffusion,DALLE,Imagen,SORA 等大模型如雨后春笋般涌现,进一步丰富了生成式 AI 的应用前景。然而,当前的扩散模型在理论上并非完美,鲜有研究关注到采样时间端点处未定义的奇点问题。此外,奇点问题在应用中导致的平均灰度等影响生成图像质量的问题也一直未得到解决。

今年升级的重点在于引入了多模态大模型能力。