
还有人关心医疗大模型吗?
还有人关心医疗大模型吗?医疗大模型的降温,来得比预料中更快。一些本就不知名的医疗大模型,在测试期间便直接没了下文。一夜之间爆火的医疗大模型,似乎在一夜之间就迅速冷却。2024年了,还有人关心医疗大模型吗?
来自主题: AI资讯
4294 点击 2024-03-22 10:42
 搜索
搜索
医疗大模型的降温,来得比预料中更快。一些本就不知名的医疗大模型,在测试期间便直接没了下文。一夜之间爆火的医疗大模型,似乎在一夜之间就迅速冷却。2024年了,还有人关心医疗大模型吗?

在路易斯·V·格斯纳(Lou Gerstner)到来之前,IBM困在自己的技术陷阱里整整10年。20世纪80年代,个人电脑兴起以及市场的快速变化开始对IBM构成挑战。这个市场份额最高曾经达到80%的硬件巨头,在进入90年代后随着个人电脑的普及和小型化,大型机市场萎缩,濒临解体边缘。这时候已经很少有人在意正是这家公司第一次把个人电脑带到世界上。

近年来,LLM 已经一统所有文本任务,展现了基础模型的强大潜力。一些视觉基础模型如 CLIP 在多模态理解任务上同样展现出了强大的泛化能力,其统一的视觉语言空间带动了一系列多模态理解、生成、开放词表等任务的发展。然而针对更细粒度的目标级别的感知任务,目前依然缺乏一个强大的基础模型。

简笔素描一键变身多风格画作,还能添加额外的描述,这在 CMU、Adobe 联合推出的一项研究中实现了。作者之一为 CMU 助理教授朱俊彦,其团队在 ICCV 2021 会议上发表过一项类似的研究:仅仅使用一个或数个手绘草图,即可以自定义一个现成的 GAN 模型,进而输出与草图匹配的图像。

作为大模型的「记忆体」,向量数据库重要性不言而喻。GTC 2024上,全球首个GPU加速向量数据库诞生了,由英伟达CUDA加持,性能实现50倍提升。5年前上海厂房里的一行代码,竟开启了一个时代。
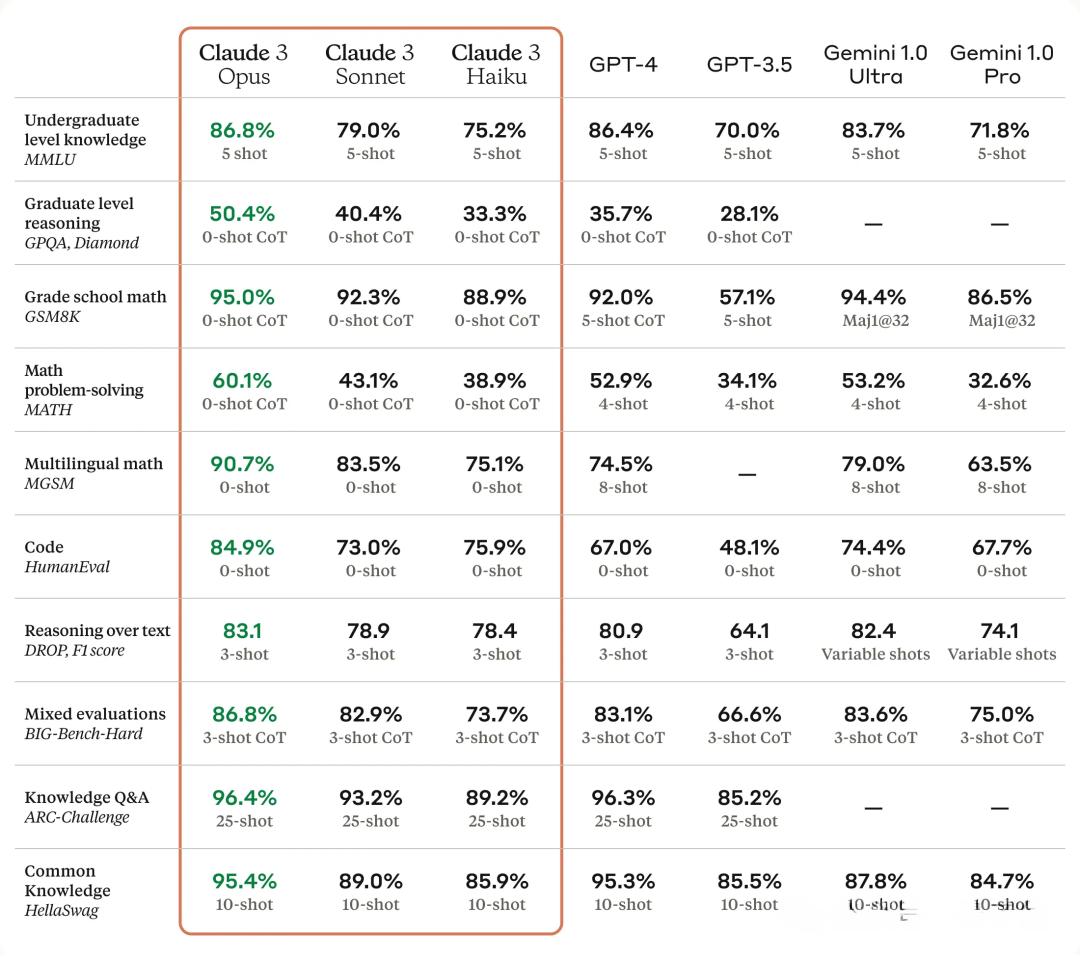
Claude3凭什么这么强?春天到了,和万物一起竞发的,还有愈发火热的AI。自2月以来,国外头部AI企业大招连出,纷纷推出了一系列强大的AI模型或技术。除了在AI圈刷屏刷到爆的Sora以外,另一匹黑马Claude 3也在三月份杀出,直接夺取了GPT-4最强大模型的地位。

8年时间,英伟达AI芯片的算力增长了1000倍。当地时间3月18日,英伟达在2024 GTC大会上发布了多款芯片、软件产品。 创始人黄仁勋表示:“通用计算已经失去动力,现在我们需要更大的AI模型,更大的GPU,需要将更多GPU堆叠在一起。这不是为了降低成本,而是为了扩大规模。”

受人类视觉系统的启发,MVDiffusion++结合计算方法高保真和人类视觉系统灵活性,可以根据任意数量的无位姿图片, 生成密集、高分辨率的有位姿图像,实现了高质量的3D模型重建。

近日,Stability AI又发布了新作SV3D,基于视频扩散模型的SV3D将3D模型生成的效果提升了一大截,模型权重已在huggingface开放。

谷歌发布了一个新的视频框架:只需要一张你的头像、一段讲话录音,就能得到一个本人栩栩如生的演讲视频。