
大语言模型评测是怎么被玩儿烂的?我们跟知情人聊了一个下午
大语言模型评测是怎么被玩儿烂的?我们跟知情人聊了一个下午上海人工智能研究室(下简称上海 AI Lab)在徐汇区云锦路上有11幢楼。这里有6000张GPU,也是这座城市在人工智能领域的中心。
来自主题: AI资讯
10480 点击 2024-01-31 16:29
 搜索
搜索
上海人工智能研究室(下简称上海 AI Lab)在徐汇区云锦路上有11幢楼。这里有6000张GPU,也是这座城市在人工智能领域的中心。

多模态大型语言模型进展如何?盘点 26 个当前最佳多模态大型语言模型。

对于大型视觉语言模型(LVLM)而言,扩展模型可以有效提高模型性能。然而,扩大参数规模会显著增加训练和推理成本,因为计算中每个 token 都会激活所有模型参数。
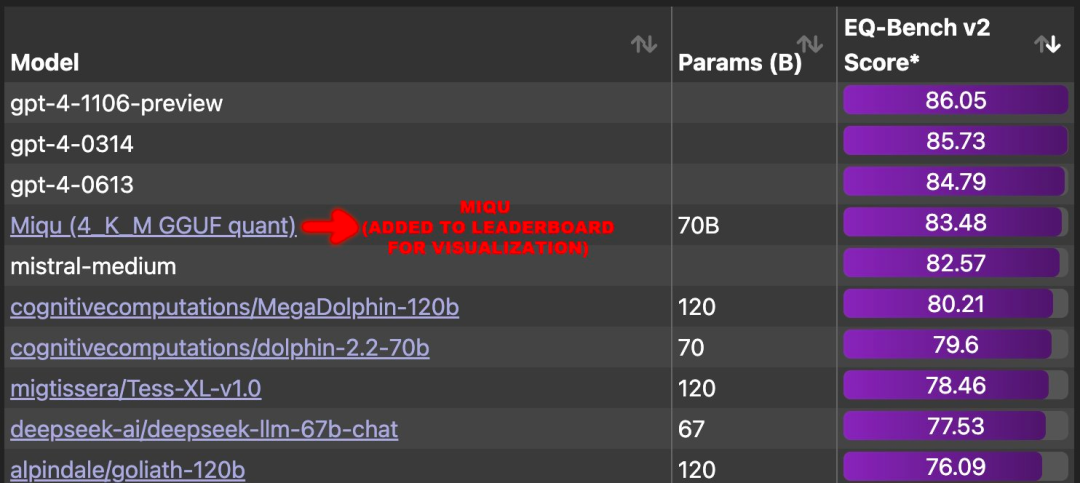
近日,一则关于「Mistral-Medium 模型泄露」的消息引起了大家的关注。
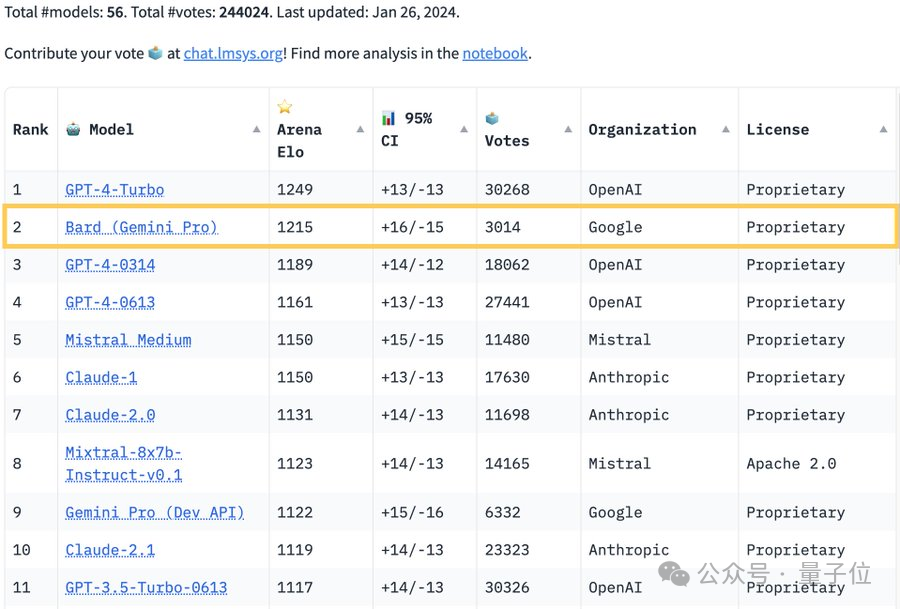
“大模型排位赛”权威榜单Chatbot Arena刷新:谷歌Bard超越GPT-4,排名位居第二,仅次于GPT-4 Turbo。
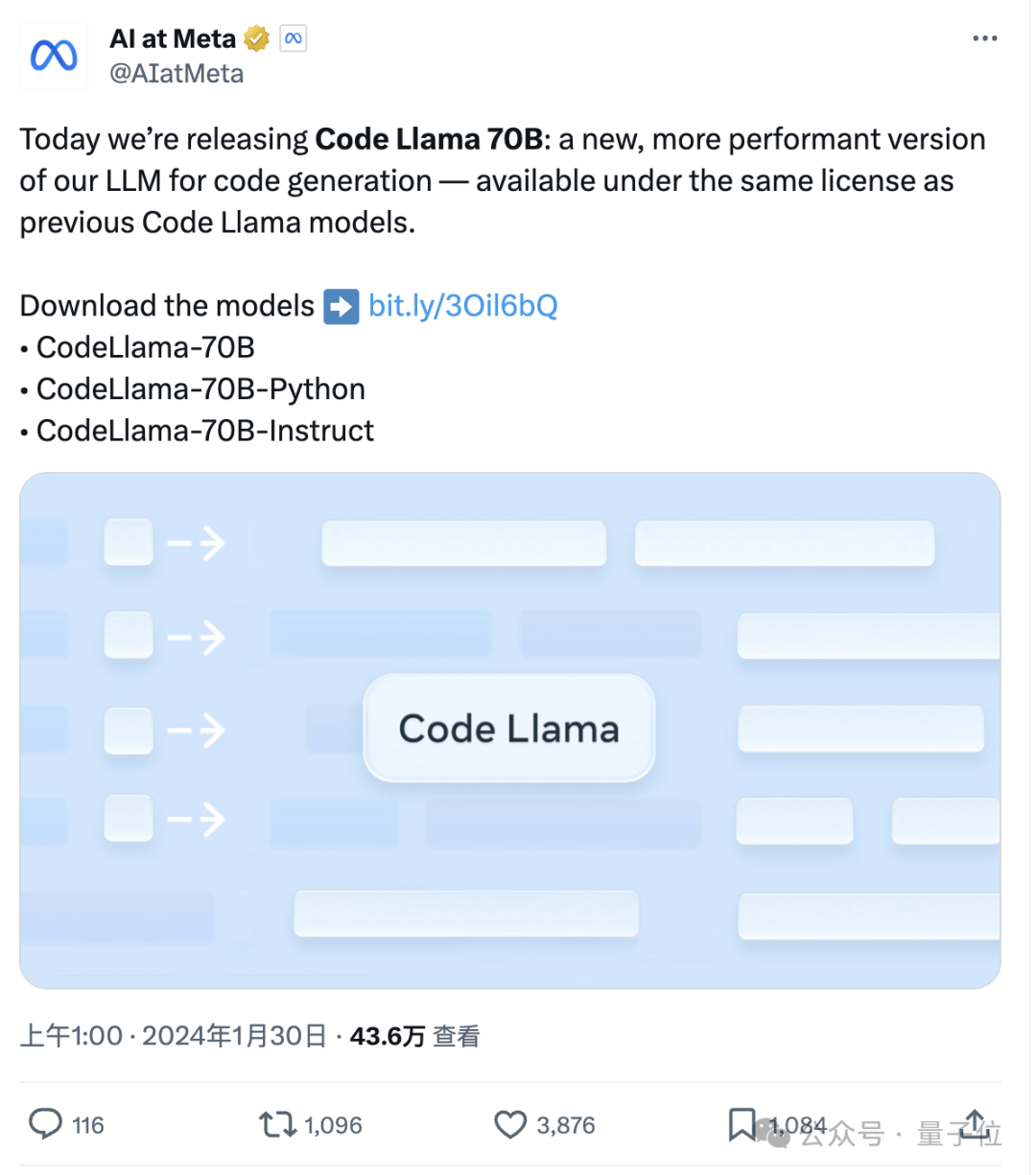
羊驼家族的“最强开源代码模型”,迎来了它的“超大杯”——就在今天凌晨,Meta宣布推出Code Llama的70B版本。

生成式AI技术发展的背后,反映出人类与大模型交互的不断精进。大模型在训练过程中不断学习人类的思考方式,人类在与大模型的对话中也收获了灵感和新知。
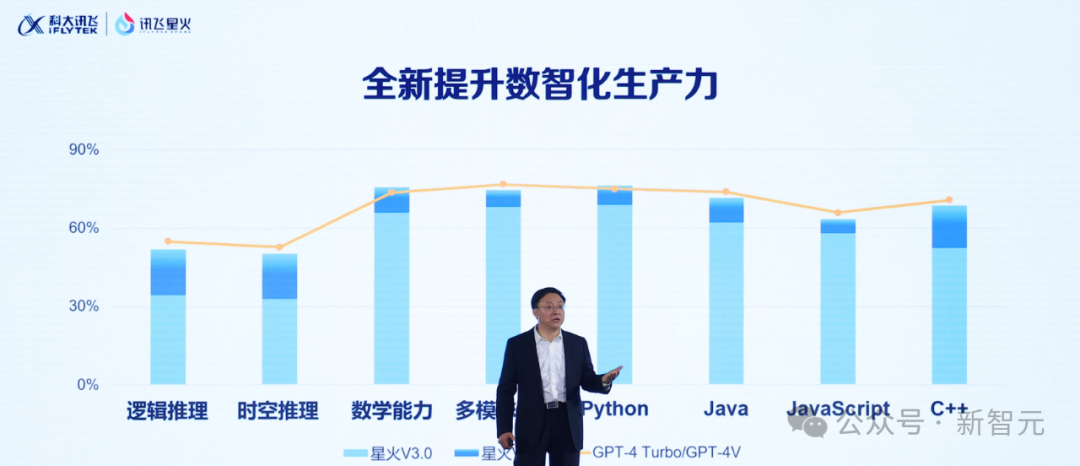
首个基于全国产化算力平台「飞星一号」的大模型,正式开源!

马里兰大学联合北卡教堂山发布首个专为多模态大语言模型(MLLM)设计的图像序列的基准测试Mementos,涵盖了真实世界图像序列、机器人图像序列,以及动漫图像序列,用4761个多样化图像序列的集合,全面测试MLLM对碎散图像序列的推理能力!

不用图像,只用文本就能训练出视觉概念表征?用写代码的方式读懂画面,形状、物体、场景都能懂!