无需训练、只优化解码策略,DTS框架让大模型推理准确率提升6%,推理长度缩短23%
无需训练、只优化解码策略,DTS框架让大模型推理准确率提升6%,推理长度缩短23%专注推理任务的 Large Reasoning Models 在数学基准上不断取得突破,但也带来了一个重要问题:越想越长、越长越错。本文解读由 JHU、UNC Charlotte 等机构团队的最新工作
来自主题: AI技术研报
7981 点击 2025-11-22 11:31
 搜索
搜索
专注推理任务的 Large Reasoning Models 在数学基准上不断取得突破,但也带来了一个重要问题:越想越长、越长越错。本文解读由 JHU、UNC Charlotte 等机构团队的最新工作
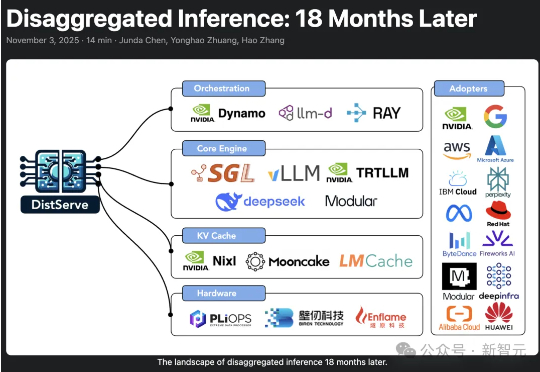
2024年,加州大学圣地亚哥分校「Hao AI Lab」提出了DistServe的解耦推理理念,短短一年多时间,迅速从实验室概念成长为行业标准,被NVIDIA、vLLM等主流大模型推理框架采用,预示着AI正迈向「模块化智能」的新时代。
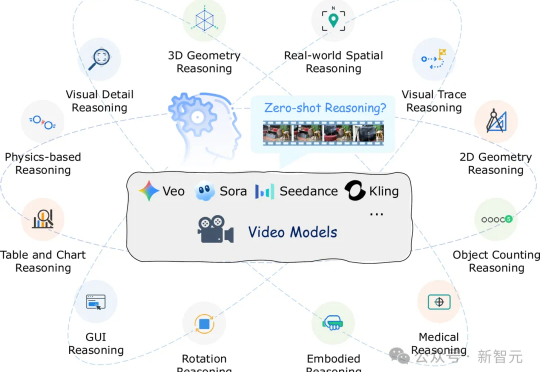
视频生成模型如Veo-3能生成逼真视频,但有研究发现其推理能力存疑。香港中文大学、北京大学、东北大学的研究者们设计了12项测试,发现模型只能模仿表面模式,未真正理解因果。这项研究为视频模型推理能力评估提供基准,指明未来研究方向。
在大语言模型(LLM)席卷各类复杂任务的今天,“测试时扩展”(Test-Time Scaling,TTS)已成为提升模型推理能力的核心思路 —— 简单来说,就是在模型 “答题” 时分配更多的计算资源来让它表现更好。严格来说,Test-Time Scaling 分成两类:
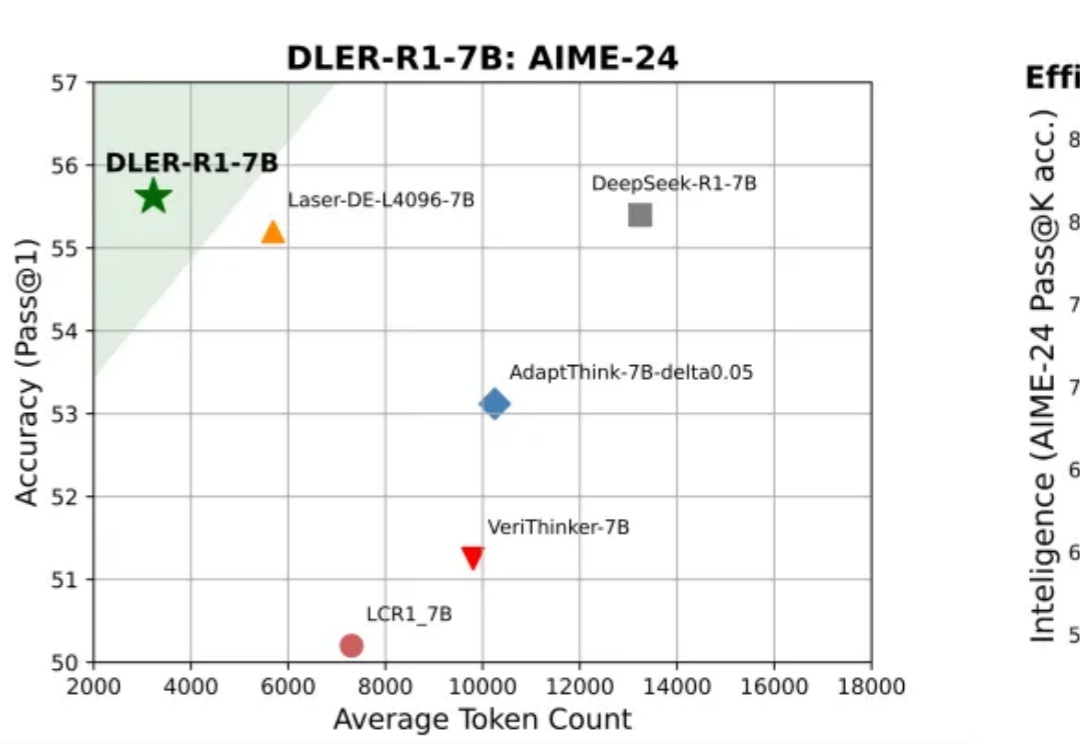
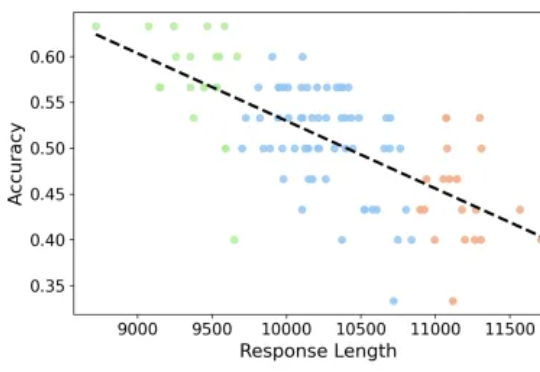
大模型推理到底要不要「长篇大论」?过去一年,OpenAI o 系列、DeepSeek-R1、Qwen 等一系列推理模型,把「长链思维」玩到极致:答案更准了,但代价是推理链越来越长、Token 消耗爆炸、响应速度骤降。
论文第一作者何浩然是香港科技大学博士生,研究方向包括强化学习和基础模型等,研究目标是通过经验和奖励激发超级智能。共同第一作者叶语霄是香港科技大学一年级博士。通讯作者为香港科技大学电子及计算机工程系、计
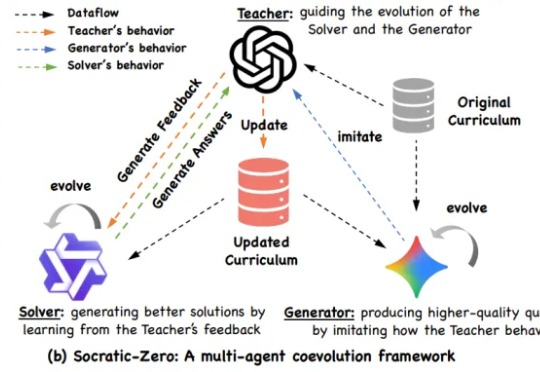
阿里巴巴与上海交通大学 EPIC Lab 联合提出 Socratic-Zero,一个完全无外部数据依赖的自主推理训练框架。该方法仅从 100 个种子问题出发,通过三个智能体的协同进化,自动生成高质量、难度自适应的课程,并持续提升模型推理能力。
大模型在强化学习过程中,终于知道什么经验更宝贵了! 来自上海人工智能实验室、澳门大学、南京大学和香港中文大学的研究团队,最近提出了一套经验管理和学习框架ExGRPO—— 通过科学地识别、存储、筛选和学习有价值的经验,让大模型在优化推理能力的道路上,走得更稳、更快、更远。
针对「大模型推理速度慢,生成token高延迟」的难题,莫纳什、北航、浙大等提出R-Stitch框架,通过大小模型动态协作,衡量任务风险后灵活选择:简单任务用小模型,关键部分用大模型。实验显示推理速度提升最高4倍,同时保证高准确率。

英伟达桌面超算,邪修玩法来了!两台DGX Spark串联一台苹果Mac Studio,就能让大模型推理速度提升至2.77倍。