
斯坦福打脸大模型数学水平:题干一改就集体降智,强如o1也失准,能力涌现怕不是检索题库
斯坦福打脸大模型数学水平:题干一改就集体降智,强如o1也失准,能力涌现怕不是检索题库只是换一下数学题的变量名称,大模型就可能集体降智??
来自主题: AI技术研报
6561 点击 2025-01-05 20:18
 搜索
搜索
只是换一下数学题的变量名称,大模型就可能集体降智??

Epoch AI推出数学基准FrontierMath,目前前沿模型测试成功率均低于2%!OpenAI研究科学家Noam Brown说道:「我喜欢看到新评估的前沿模型通过率如此之低。这种感觉就像一觉醒来,外面是一片崭新的雪地,完全没有人迹。」或许,FrontierMath测试成功率突破的那一天,会是AI发展过程中一个全新的里程碑。
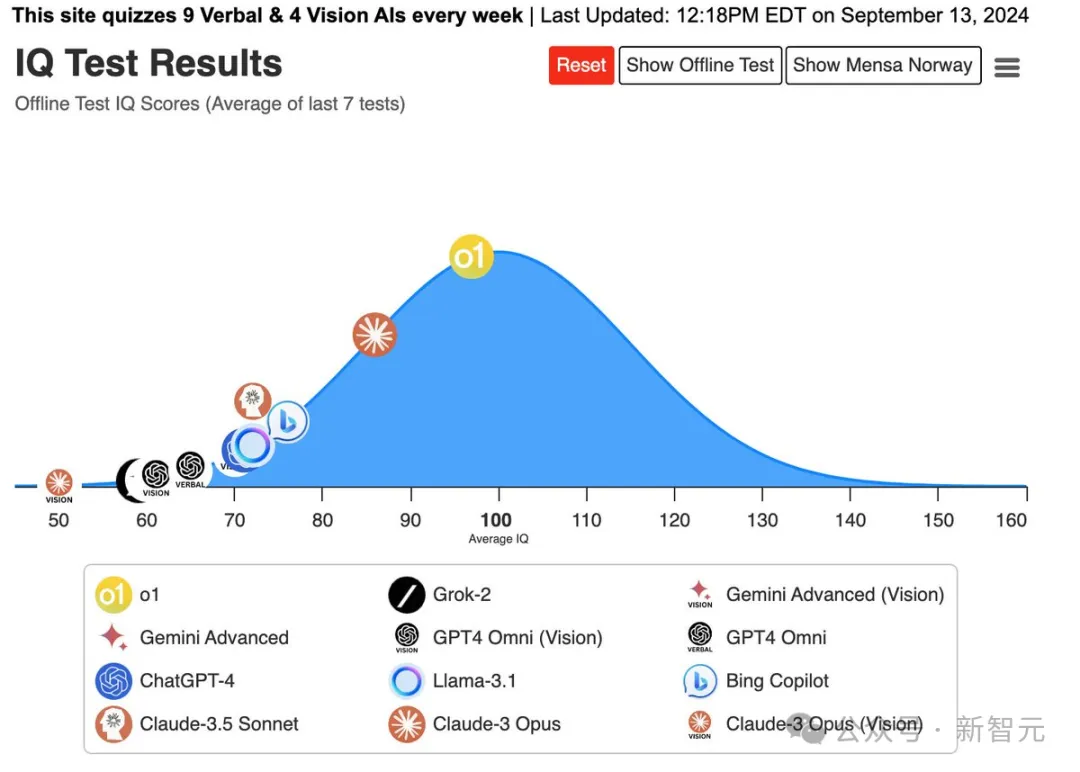
OpenAI o1,在IQ测试中拿到了第一名!大佬Maxim Lott,给o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等进行了智商测试,结果表明,o1稳居第一名。

谷歌DeepMind推出LLM自动评估模型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。

大模型测试能拿高分,实际场景中却表现不佳的问题有解了。
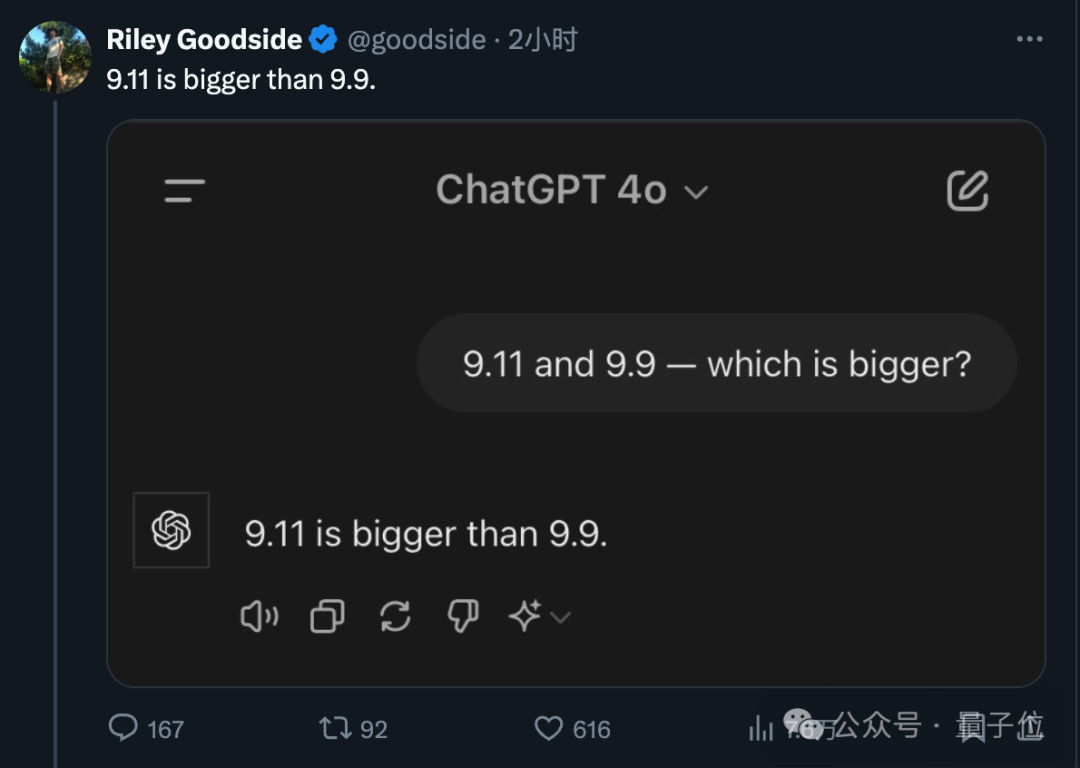
没眼看……“9.11和9.9哪个大”这样简单的问题,居然把主流大模型都难倒了??

大力出奇迹,也是一个新思路。

LLM能否解决「狼-山羊-卷心菜」经典过河难题?最近,菲尔兹奖得主Timothy Gowers分享了实测GPT-4o的过程,模型在最简单的题目上竟然做错了,甚至网友们发现,就连Claude 3.5也无法幸免。

还有12款大模型全军覆没……

随着大语言模型(LLM)的发展,很多研究发现LLM能够展现出稳定的人格特质,模仿人类细微的情绪与认知模式,还能辅助各种各样的社会科学仿真实验,为教育心理学、社会心理学、文化心理学、临床心理学、心理咨询等诸多心理学研究领域,提供了新的研究思路。