
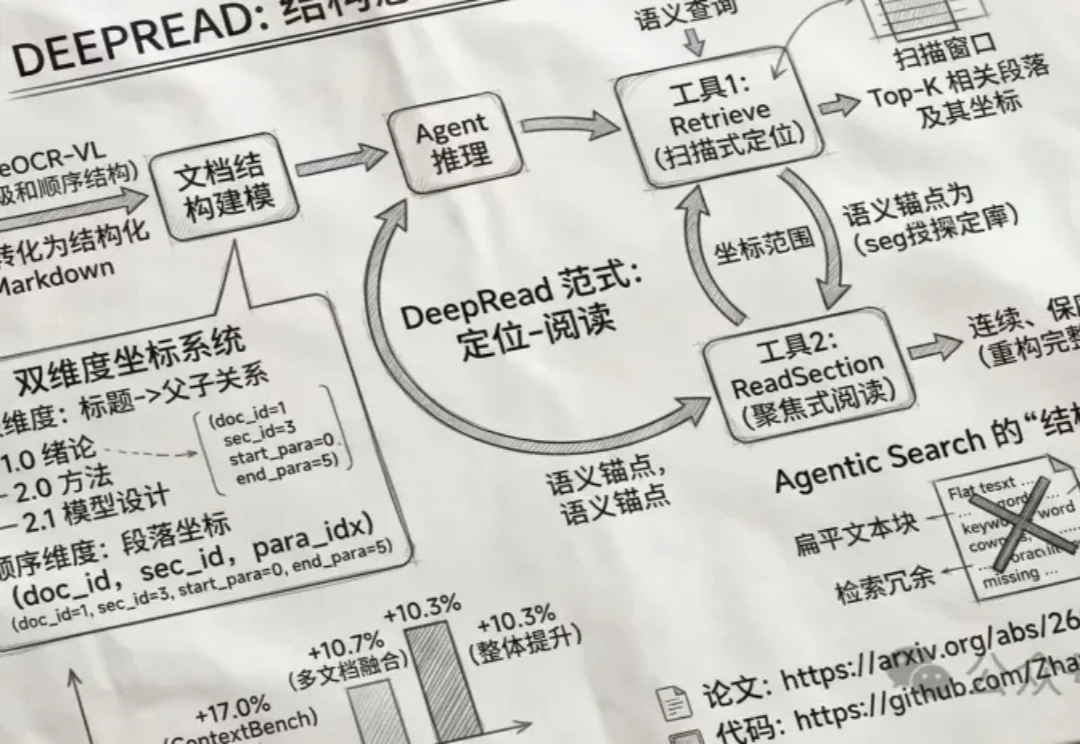
AI读不懂文档结构?计算所重构Agentic RAG文档推理能力
AI读不懂文档结构?计算所重构Agentic RAG文档推理能力DeepRead让AI像人一样阅读文档:利用OCR识别章节结构,先精准定位相关段落,再完整读取上下文,避免碎片化检索。实验显示,其长文档问答准确率提升17%,能自动跳过冗余信息,精准提取财报、论文等复杂内容,无需额外知识图谱,轻量高效。
来自主题: AI资讯
8422 点击 2026-03-16 14:26
DeepRead让AI像人一样阅读文档:利用OCR识别章节结构,先精准定位相关段落,再完整读取上下文,避免碎片化检索。实验显示,其长文档问答准确率提升17%,能自动跳过冗余信息,精准提取财报、论文等复杂内容,无需额外知识图谱,轻量高效。

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
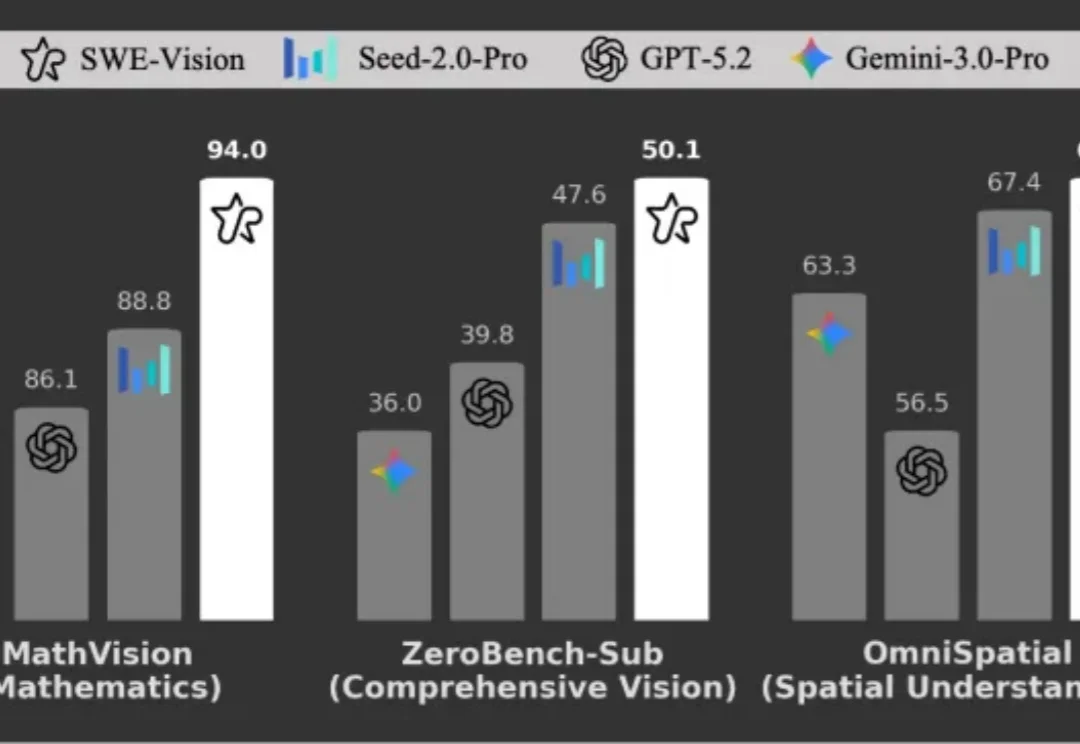
多模态大模型在代码能力上进步惊人,但在基础视觉任务上却频繁失误。UniPat AI 构建了一个极简的视觉智能体框架 ——SWE-Vision,让模型可以编写并执行 Python 代码来处理和验证自己的视觉判断。在五个主流视觉基准测试中,SWE-Vision 均达到了当前最优水平。

你随手拍下一张照片,AI也许只会夸“真好看”,却说不出一句真正有用的建议。

自2025年10月Claude正式确立Agent Skills规范以来 ,Agent能力的边界正在被暴涨的脚本仓库迅速拓宽。截至2026年2月末,公开可用的Skills数量已突破28万大关 。回顾过去半年,Skills开发的火力几乎全集中在了“供给侧”,而且绝大多数由分散的第三方开发者维护。

先提前预告下,这个项目解决不了不赚钱的问题,但能帮助减少冲动交易,解决信息搜集、分析效率低问题。当然,也有同事吐槽,这是个韭菜RL,大家有选择地参考与批判一下就好。
最近,一个叫OpenClaw(小龙虾)的开源项目突然爆火,甚至出现线下排队安装的场面。很多人第一次直观地看到,AI不只是chatbot,而是可以真正“动手”操作电脑、完成复杂任务和个性化工作流的智能体。这意味着AI正在进入下半场,开始走向真实应用,并逐渐进入普通人的日常生活。

vibe coding这个词,是一年前Karpathy造的,现在他自己不用了。110次实验,AI Agent自主跑完,全程没碰键盘,顺带还搭了套家庭监控分析系统。Box CEO Levie看完说了一句话:专家不会消失,但专家能做到的事,边界变了。
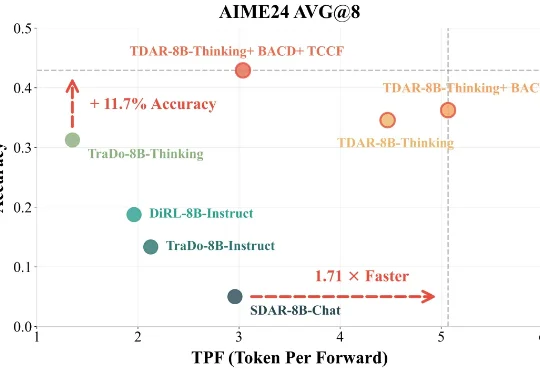
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码

牛津大学团队推出全球首个心脏传感基础模型CSFM,能统一分析智能手环、心电图等多源数据,无论信号来自何处、是否完整,都能精准诊断房颤、预测死亡风险、重构血压波形,甚至用单一脉搏波生成完整心电图。打破了设备壁垒,让偏远地区也能享用顶级心脏监护,推动全球医疗平权。