

LLM「啊哈时刻」竟会自我纠正,单体数学性能暴涨!UIUC华人一作
LLM「啊哈时刻」竟会自我纠正,单体数学性能暴涨!UIUC华人一作LLM在推理任务中表现惊艳,却在自我纠正上的短板却一直令人头疼。UIUC联手马里兰大学全华人团队提出一种革命性的自我奖励推理框架,将生成、评估和纠正能力集成于单一LLM,让模型像人类一样「边想边改」,无需外部帮助即可提升准确性。
来自主题: AI技术研报
8660 点击 2025-03-03 10:28
LLM在推理任务中表现惊艳,却在自我纠正上的短板却一直令人头疼。UIUC联手马里兰大学全华人团队提出一种革命性的自我奖励推理框架,将生成、评估和纠正能力集成于单一LLM,让模型像人类一样「边想边改」,无需外部帮助即可提升准确性。

现有的可控Diffusion Transformer方法,虽然在推进文本到图像和视频生成方面取得了显著进展,但也带来了大量的参数和计算开销。

大语言模型(LLMs)在当今的自然语言处理领域扮演着越来越重要的角色,但其安全性问题也引发了广泛关注。
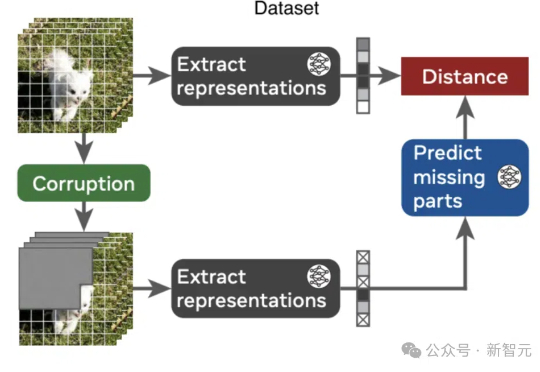
AI如何理解物理世界?视频联合嵌入预测架构V-JEPA带来新突破,无需硬编码核心知识,在自监督预训练中展现出对直观物理的理解,超越了基于像素的预测模型和多模态LLM。
GRPO(Group Relative Policy Optimization)是 DeepSeek-R1 成功的基础技术之一,我们之前也多次报道过该技术,比如《DeepSeek 用的 GRPO 占用大量内存?有人给出了些破解方法》。
原来,大型推理模型(Large Reasoning Model,LRM)像人一样,在「用脑过度」也会崩溃,进而行动能力下降。
Transformer 很成功,更一般而言,我们甚至可以将(仅编码器)Transformer 视为学习可交换数据的通用引擎。由于大多数经典的统计学任务都是基于独立同分布(iid)采用假设构建的,因此很自然可以尝试将 Transformer 用于它们。
在大语言模型 (LLM) 的研究中,与以 Chain-of-Thought 为代表的逻辑思维能力相比,LLM 中同等重要的 Leap-of-Thought 能力,也称为创造力,目前的讨论和分析仍然较少。这可能会严重阻碍 LLM 在创造力上的发展。造成这种困局的一个主要原因是,面对「创造力」,我们很难构建一个合适且自动化的评估流程。

当百亿千亿参数的大模型霸占着科技头条,“若无必要,勿增实体”这把古老“剃刀”是否依旧闪耀?复杂性与简洁性真的是对立的吗?本文将回溯历史长河,探寻一个古老哲学原则与现代科技之间的微妙关联。在这个过程中,我们或许能够发现,复杂与简洁之间隐藏着怎样的辩证关系。

单目深度估计新成果来了!西湖大学AGI实验室等提出了一种创新性的蒸馏算法,成功整合了多个开源单目深度估计模型的优势。在仅使用2万张无标签数据的情况下,该方法显著提升了估计精度,并刷新了单目深度估计的最新SOTA性能。