正交化之外是什么?微软等提出ARO优化器:训练提速1/3,揭示矩阵优化新「蓝海」
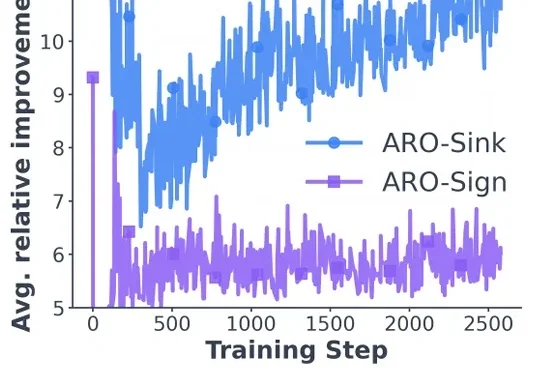
正交化之外是什么?微软等提出ARO优化器:训练提速1/3,揭示矩阵优化新「蓝海」如果你在过去一年关注过大模型训练的技术,大概率听过 Muon 这个名字 —— 这个在月之暗面 K2 模型的相关讨论中走红的优化器,被视为是可能挑战 Adam 的新秀。它的思路很直接:对动量矩阵进行正交化,让各个奇异方向上的更新速率一致,提升训练效率。
来自主题: AI技术研报
6273 点击 2026-03-10 14:31