

续命Scaling Law?世界模型GPT-4o让智能体超级规划,OSU华人一作
续命Scaling Law?世界模型GPT-4o让智能体超级规划,OSU华人一作Scaling Law撞墙,扩展语言智能体的推理时计算实在太难了!破局之道,竟是使用LLM作为世界模型?OSU华人团队发现,使用GPT-4o作为世界模型来支持复杂环境中的规划,潜力巨大。
来自主题: AI技术研报
6698 点击 2024-11-22 13:38
Scaling Law撞墙,扩展语言智能体的推理时计算实在太难了!破局之道,竟是使用LLM作为世界模型?OSU华人团队发现,使用GPT-4o作为世界模型来支持复杂环境中的规划,潜力巨大。
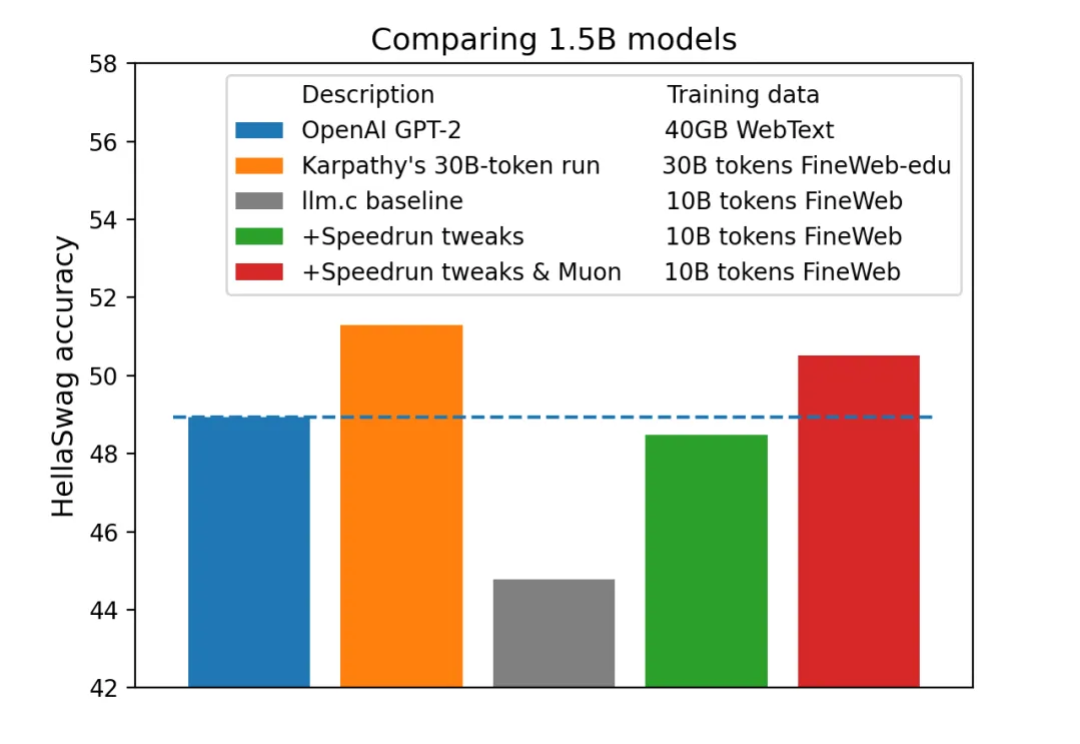
今年 4 月,AI 领域大牛 Karpathy 一个仅用 1000 行代码即可在 CPU/fp32 上实现 GPT-2 训练的项目「llm.c」曾经引发机器学习社区的热烈讨论。
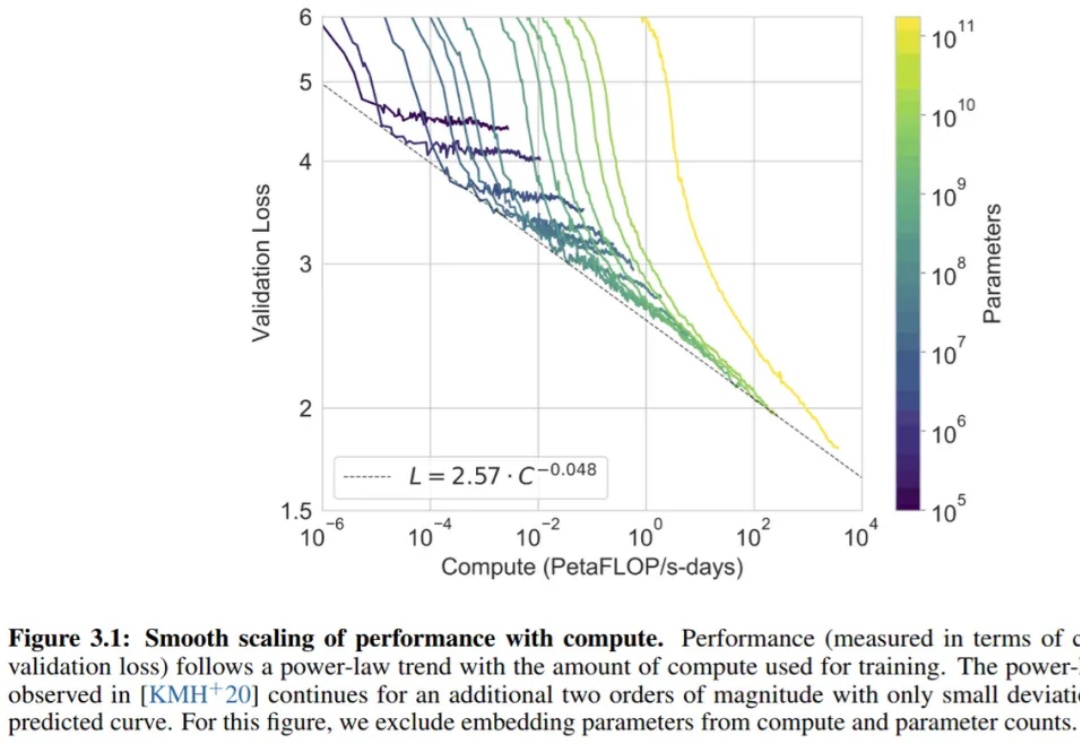
Powerful AI 预计会在 2026 年实现,足够强大的 AI 也能够将把一个世纪的科研进展压缩到 5-10 年实现(“Compressed 21st Century”),在他和 Lex Fridman 的最新对谈中,Dario 具体解释了自己对于 Powerful AI 可能带来的机会的理解,以及 scaling law、RL、Compute Use 等模型训练和产品的细节进行了分享
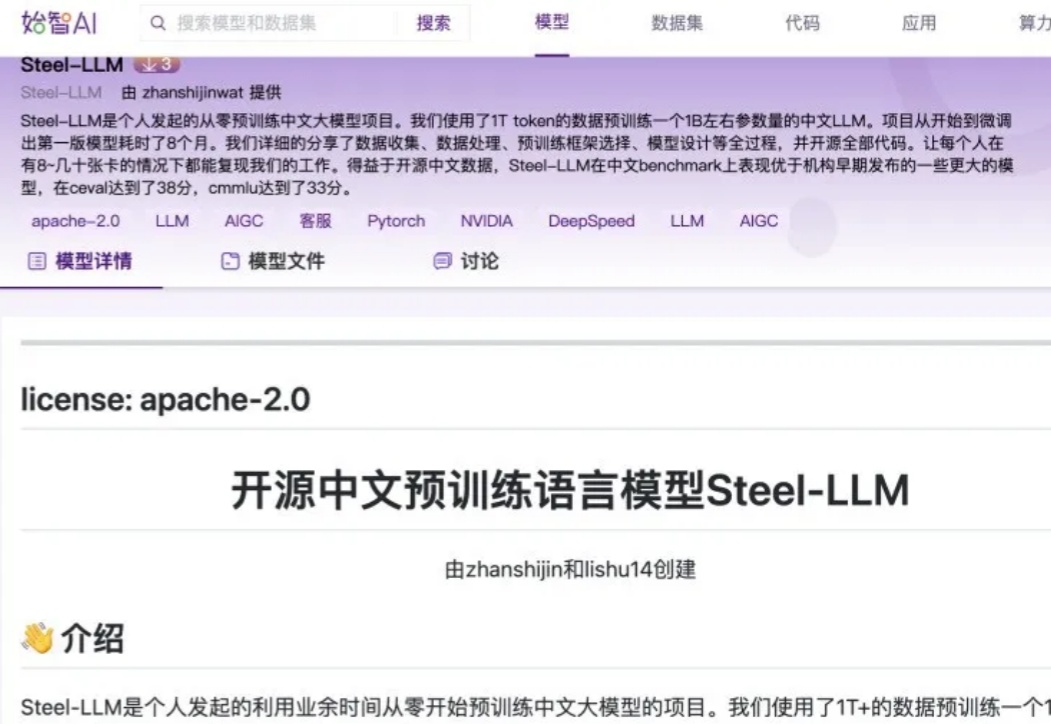
随着开源数据的日益丰富以及算力价格的持续下降,对于个人或小型机构而言,预训练一个小型的 LLM 已逐渐成为可能。开源中文预训练语言模型 Steel - LLM 就是一个典型案例,其模型参数量与数据量并非十分庞大,基本处于参数量为 B 级别、数据量为 T 级别的规模。
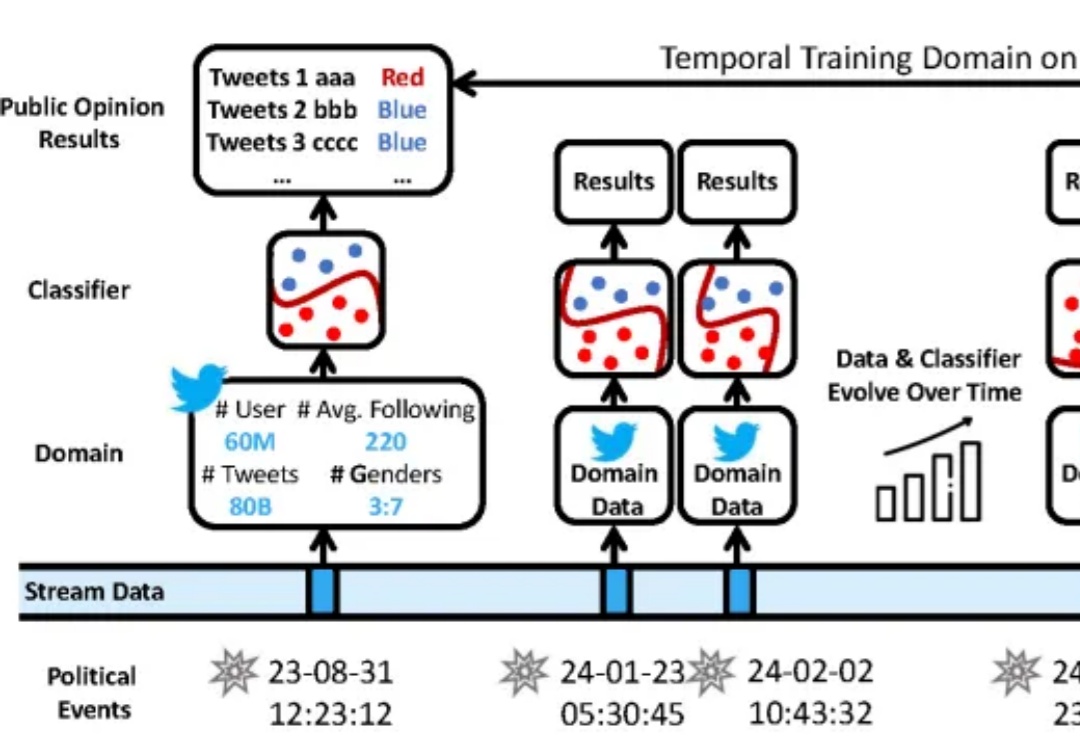
在数据分布持续变化的动态环境中,如何进行连续模型泛化?

近日,来自斯坦福、MIT等机构的研究人员推出了低秩线性转换方法,让传统注意力无缝转移到线性注意力,仅需0.2%的参数更新即可恢复精度,405B大模型两天搞定!
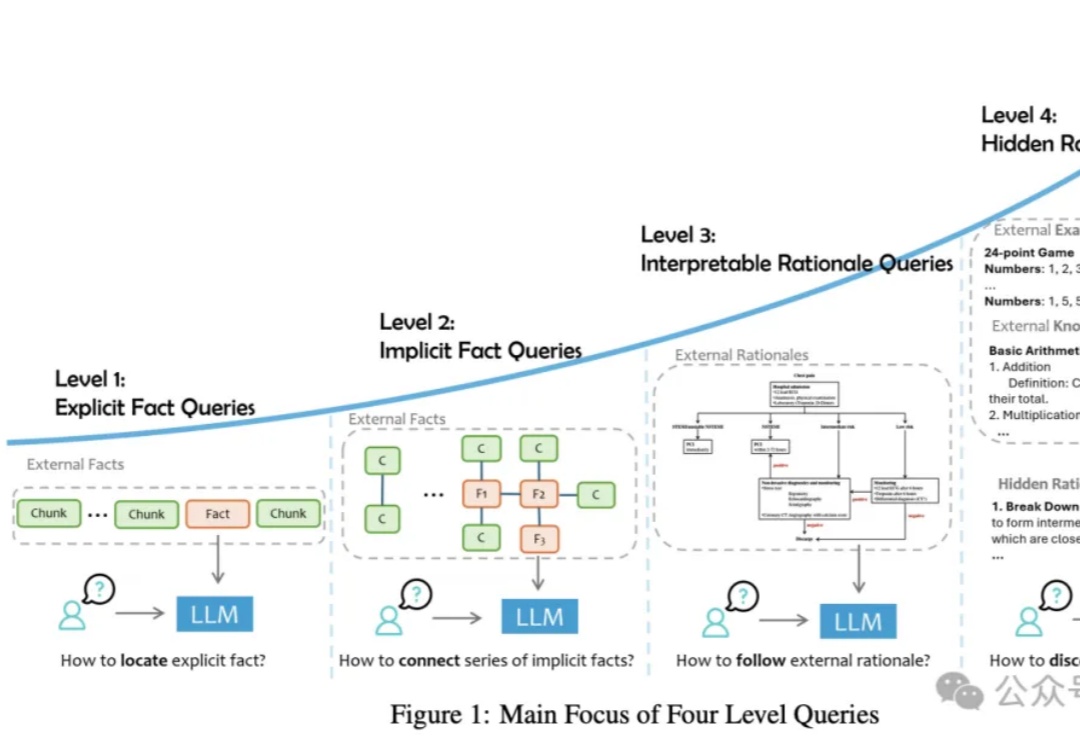
论文提出了一种RAG任务分类法,将用户查询分为四个级别,并讨论了将外部数据集成到LLMs中的三种主要方式。从简单的事实检索到复杂的推理任务,每个级别都有其独特的难点和解决方案,需要不同的技术和方法来优化性能。
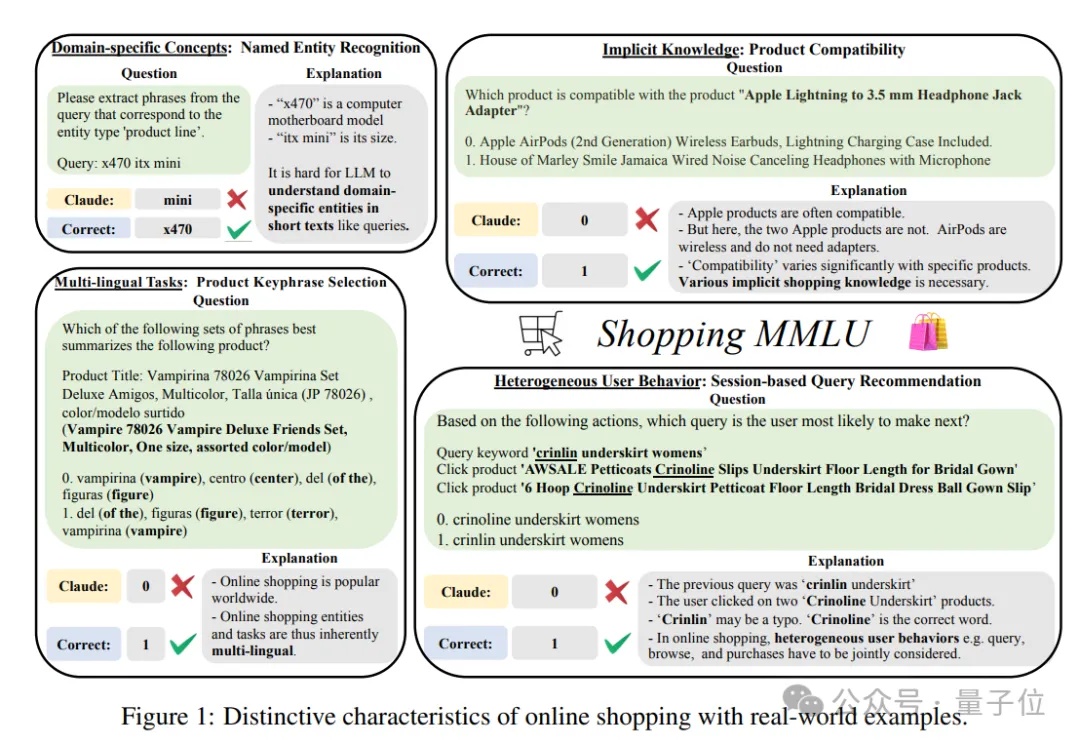
谁是在线购物领域最强大模型?也有评测基准了。
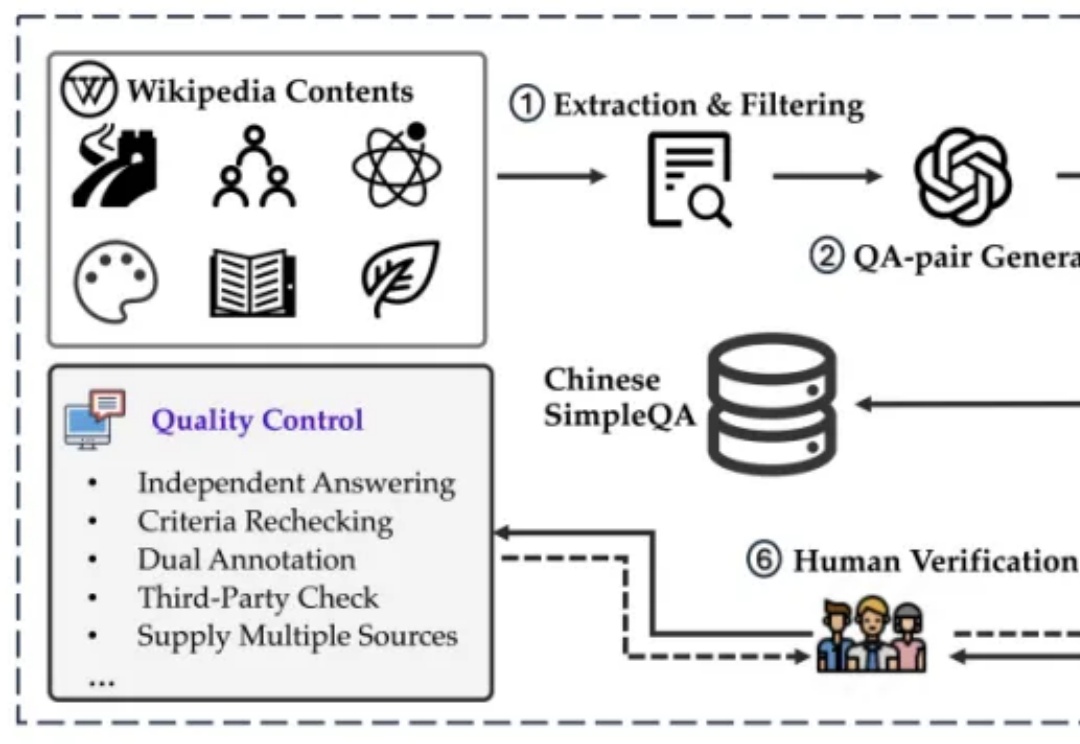
如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。
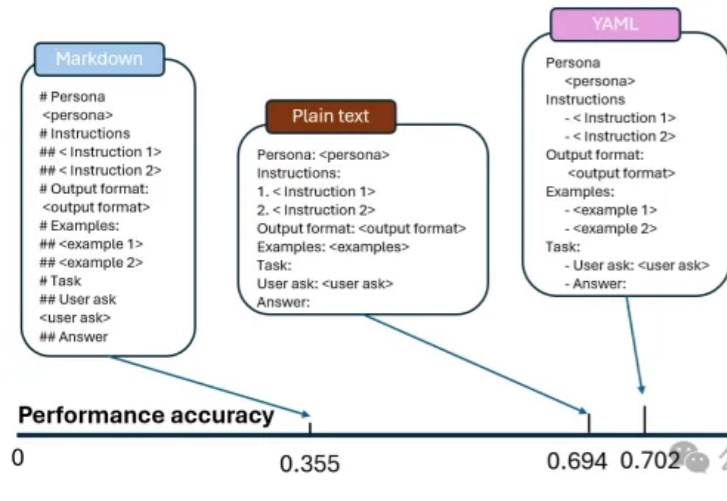
朋友们,想了解为什么同一模型会带来大量结果的不一致性吗?今天,我们来一起深入分析一下来自微软和麻省理工学院的一项重大发现——不同的Prompt格式如何显著影响LLM的输出精度。这些研究结果对于应用Prompt优化设计具有非常重要的应用价值。