

颜水成袁粒提出新一代MoE架构:专家吞吐速度最高提升2.1倍!
颜水成袁粒提出新一代MoE架构:专家吞吐速度最高提升2.1倍!比传统MoE推理速度更快、性能更高的新一代架构,来了! 这个通用架构叫做MoE++,由颜水成领衔的昆仑万维2050研究院与北大袁粒团队联合提出。
来自主题: AI技术研报
5696 点击 2024-10-21 11:22
比传统MoE推理速度更快、性能更高的新一代架构,来了! 这个通用架构叫做MoE++,由颜水成领衔的昆仑万维2050研究院与北大袁粒团队联合提出。

内存占用小,训练表现也要好……大模型训练成功实现二者兼得。 来自北理、北大和港中文MMLab的研究团队提出了一种满足低秩约束的大模型全秩训练框架——Fira,成功打破了传统低秩方法中内存占用与训练表现的“非此即彼”僵局。


近日,来自谷歌和苹果的研究表明:AI模型掌握的知识比表现出来的要多得多!这些真实性信息集中在特定的token中,利用这一属性可以显著提高检测LLM错误输出的能力。

LLM训练速度还可以再飙升20倍!英伟达团队祭出全新架构归一化Transformer(nGPT),上下文越长,训练速度越快,还能维持原有精度。

大型语言模型(LLMs)虽然在适应新任务方面取得了长足进步,但它们仍面临着巨大的计算资源消耗,尤其在复杂领域的表现往往不尽如人意。

牛顿没解决的问题,AI给你解决了? AI的推理能力一直是研究的焦点。作为最纯粹、要求最高的推理形式之一,能否解决高级的数学问题,无疑是衡量语言模型推理水平的一把尺。
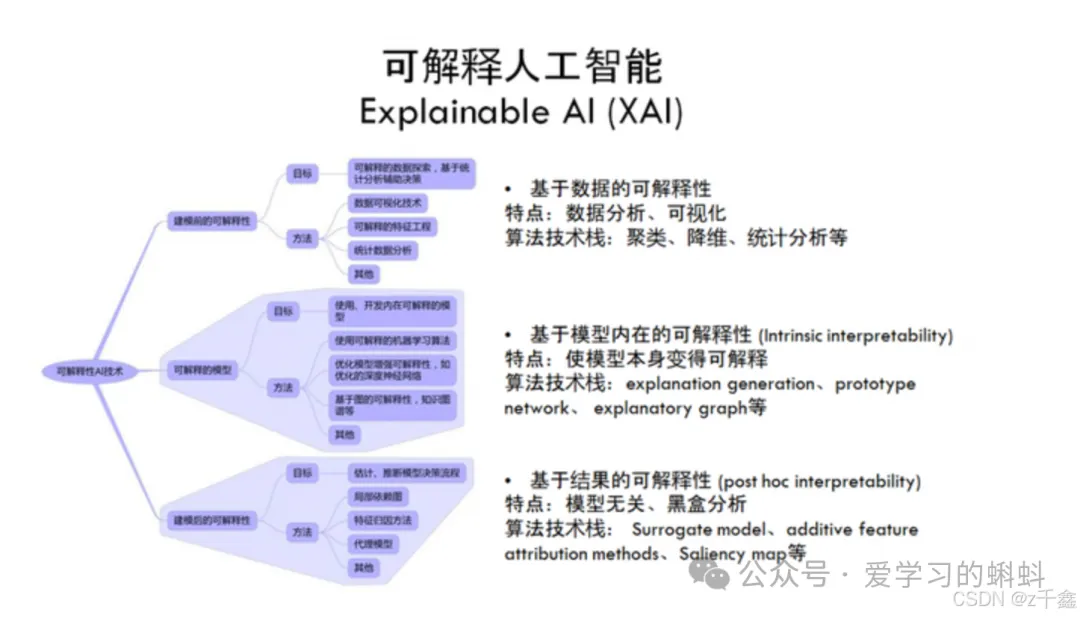
在当今人工智能(AI)和机器学习(ML)技术迅猛发展的背景下,解释性AI(Explainable AI, XAI)已成为一个备受关注的话题。

多模态生成新突破,字节&华师团队打造TextHarmony,在单一模型架构中实现模态生成的统一,并入选NeurIPS 2024。

机器人控制和自动驾驶的离线数据损坏问题有解了! 中科大王杰教授团队 (MIRA Lab) 提出了一种变分贝叶斯推断方法,有效地提升了智能决策模型的鲁棒性。