

Benchmark合伙人:训练大模型目前成本远大于收入;但理论上成功回报极大,所以你仍需不断加注
Benchmark合伙人:训练大模型目前成本远大于收入;但理论上成功回报极大,所以你仍需不断加注随着LLM的进步,它将超越代码补全(“Copilot”)的功能,进入代码创作(“Autopilot”)的领域。随着LLM变得越来越复杂,它们能够释放的经济价值也会越来越大。AGI的经济价值仅受我们的想象力限制。
来自主题: AI资讯
4666 点击 2024-10-15 14:01
随着LLM的进步,它将超越代码补全(“Copilot”)的功能,进入代码创作(“Autopilot”)的领域。随着LLM变得越来越复杂,它们能够释放的经济价值也会越来越大。AGI的经济价值仅受我们的想象力限制。

别信忽悠,信实测。

多模态AI是一种将不同形式的数据(如文本、图像、音频等)融合在一起的技术,旨在让模型从多个维度感知和理解信息。这种融合使得AI系统能够从每种模态中获取独特的但互补的信息,从而构建出更全面的世界观。例如,在一个自动驾驶场景中,图像数据可以帮助系统识别道路上的行人,而雷达数据则能够感知车距,两者结合能够显著提升决策准确性。

自从 Transformer 模型问世以来,试图挑战其在自然语言处理地位的挑战者层出不穷。 这次登场的选手,不仅要挑战 Transformer 的地位,还致敬了经典论文的名字。 再看这篇论文的作者列表,图灵奖得主、深度学习三巨头之一的 Yoshua Bengio 赫然在列。
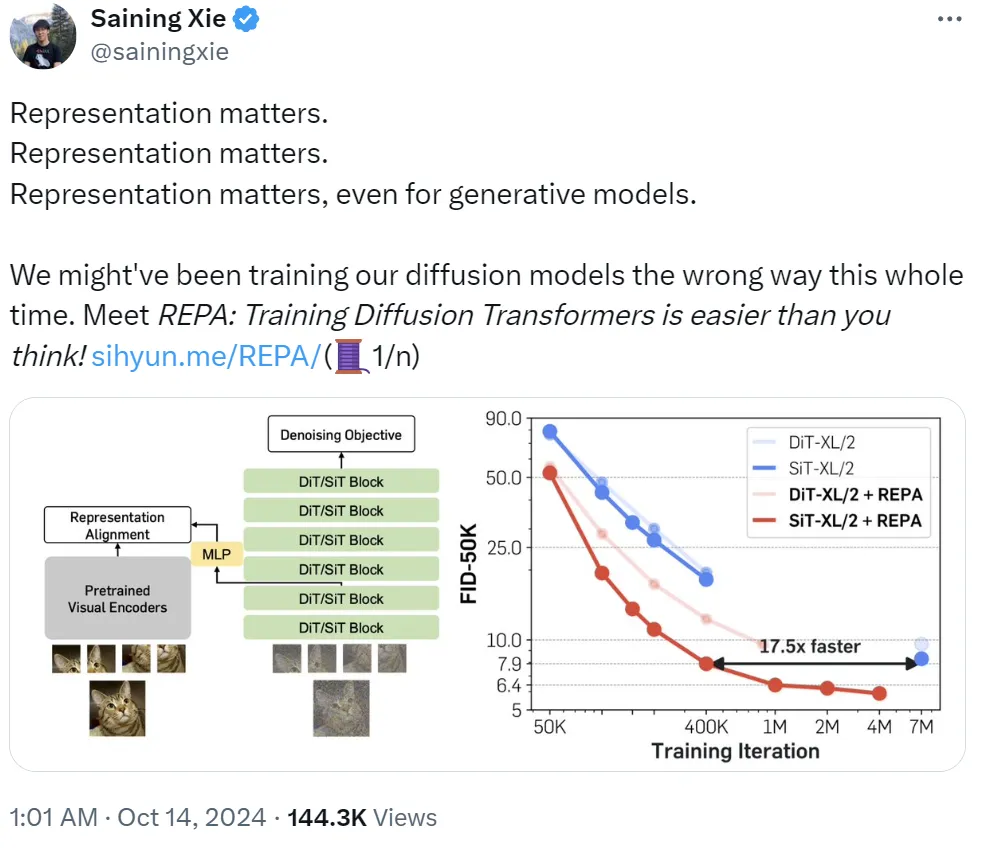
是什么让纽约大学著名研究者谢赛宁三连呼喊「Representation matters」?他表示:「我们可能一直都在用错误的方法训练扩散模型。」即使对生成模型而言,表征也依然有用。基于此,他们提出了 REPA,即表征对齐技术,其能让「训练扩散 Transformer 变得比你想象的更简单。」

传统的歌声任务,如歌声合成,大多是在利用输入的歌词和乐谱生成高质量的歌声。随着深度学习的发展,人们希望实现可控和能个性化定制的歌声生成。

1%的合成数据,就让LLM完全崩溃了? 7月,登上Nature封面一篇论文证实,用合成数据训练模型就相当于「近亲繁殖」,9次迭代后就会让模型原地崩溃。

计算资源并非性能提升的唯一途径:Arvind Narayanan 认为,仅仅增加计算资源并不总是能带来模型性能的等比提升。目前,数据量正逐渐成为限制AI发展的主要瓶颈。

5 大证据显示,LLM 在推理复杂问题时非常脆弱。

谁更懂AI训练,是人类还是AI自己?