

Ilya预言错了!华人Nature一作给RLHF「判死刑」,全球大模型都不可靠
Ilya预言错了!华人Nature一作给RLHF「判死刑」,全球大模型都不可靠2022年,AI大牛Ilya Sutskever曾预测:「随着时间推移,人类预期和AI实际表现差异可能会缩小」。
来自主题: AI资讯
4655 点击 2024-09-29 16:18
2022年,AI大牛Ilya Sutskever曾预测:「随着时间推移,人类预期和AI实际表现差异可能会缩小」。
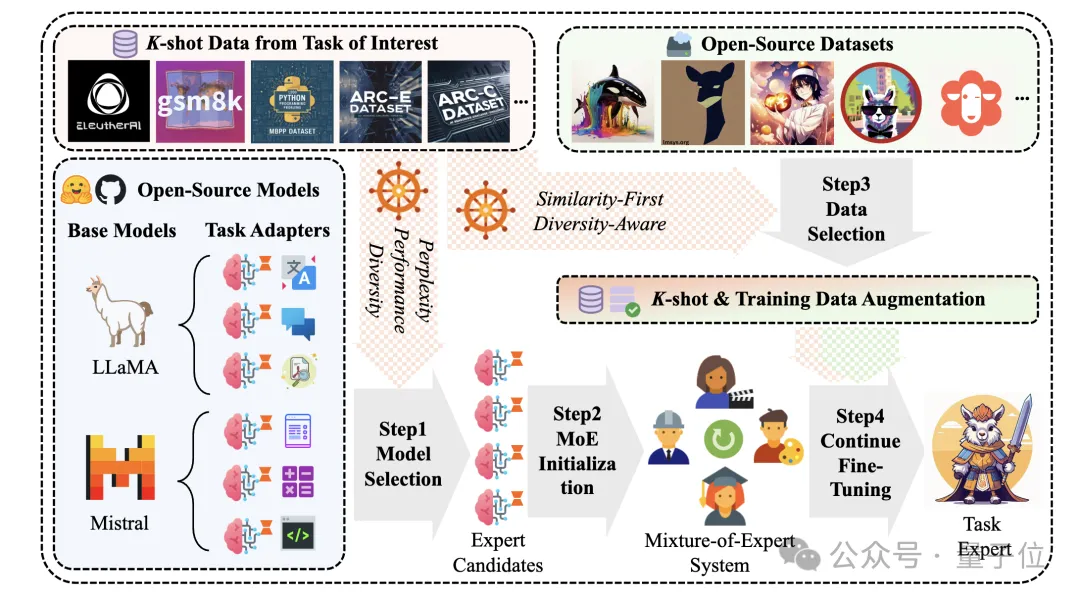
告别传统指令微调,大模型特定任务性能提升有新方法了。 一种新型开源增强知识框架,可以从公开数据中自动提取相关知识,针对性提升任务性能。 与基线和SOTA方法对比,本文方法在各项任务上均取得了更好的性能。

Sutton 等研究人员近期在《Nature》上发表的研究《Loss of Plasticity in Deep Continual Learning》揭示了一个重要发现:在持续学习环境中,标准深度学习方法的表现竟不及浅层网络。研究指出,这一现象的主要原因是 "可塑性损失"(Plasticity Loss):深度神经网络在面对非平稳的训练目标持续更新时,会逐渐丧失从新数据中学习的能力。

近日,机器学习研究员、畅销书《Python 机器学习》作者 Sebastian Raschka 又分享了一篇长文,主题为《从头开始构建一个 GPT 风格的 LLM 分类器》。

在这种背景下,研究团队提出了一个全新的框架:SubgoalXL,结合了子目标(subgoal)证明策略与专家学习(expert learning)方法,在 Isabelle 中实现了形式化定理证明的性能突破。

香港中文大学等机构的研究团队通过深度强化学习(DQN)开发了一种3D打印路径规划器,有效提升了打印效率和精度,为智能制造开辟了新途径。

Google DeepMind的SCoRe方法通过在线多轮强化学习,显著提升了大型语言模型在没有外部输入的情况下的自我修正能力。该方法在MATH和HumanEval基准测试中,分别将自我修正性能提高了15.6%和9.1%。

“通用人工智能(AGI)的设计和开发,需要进行根本性改变。” 人工智能(AI)模型的参数规模越大,生成的答案就越准确?就更加可信? 还真不一定!

Scale AI早早踩对了风口,如今终于一飞冲天了,公司的2024年年化收入预计达到近10亿美元。
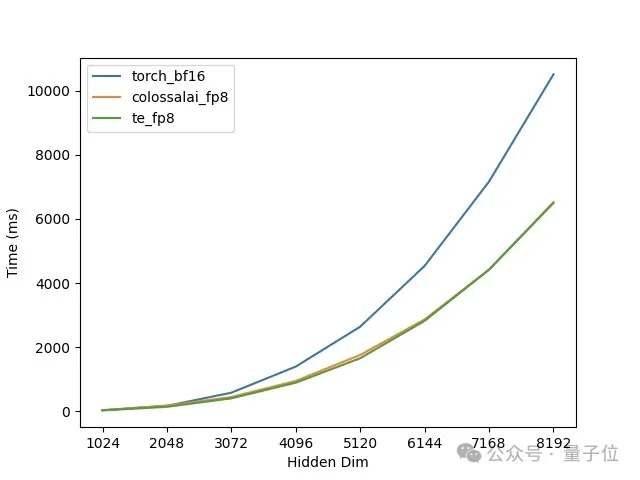
FP8通过其独特的数值表示方式,能够在保持一定精度的同时,在大模型训练中提高训练速度、节省内存占用,最终降低训练成本。