

首次!用合成人脸数据集训练的识别模型,性能高于真实数据集
首次!用合成人脸数据集训练的识别模型,性能高于真实数据集一个高质量的人脸识别训练集要求身份 (ID) 有高的分离度(Inter-class separability)和类内的变化度(Intra-class variation)。
来自主题: AI技术研报
7355 点击 2024-09-14 16:11
一个高质量的人脸识别训练集要求身份 (ID) 有高的分离度(Inter-class separability)和类内的变化度(Intra-class variation)。
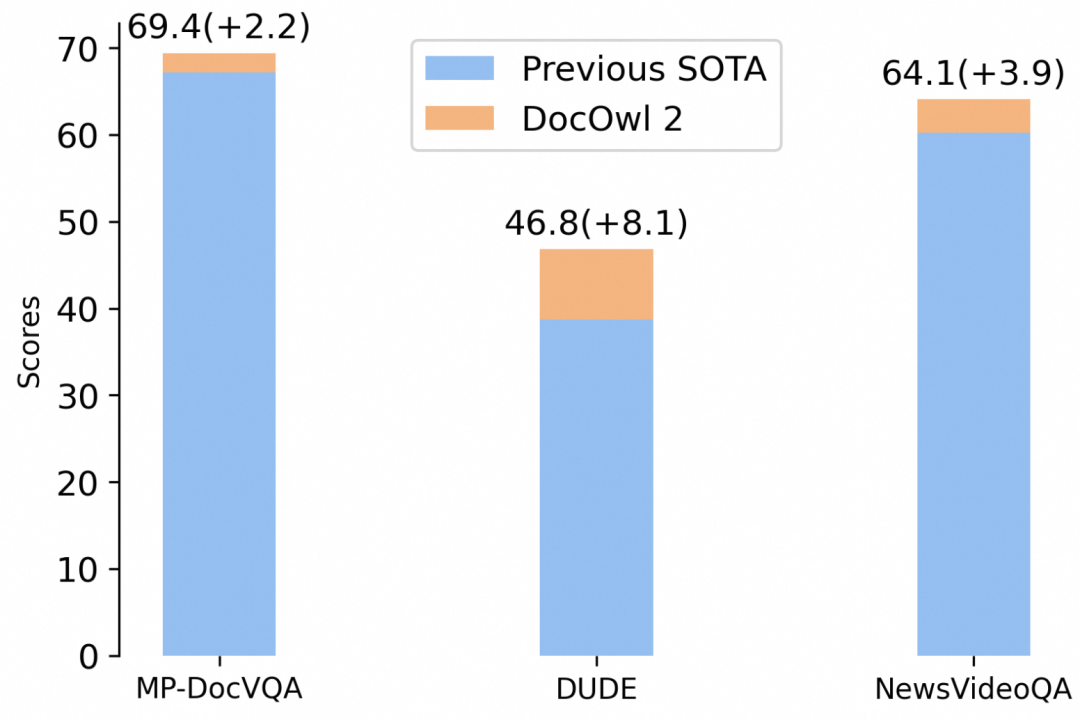
高效多页文档理解,阿里通义实验室mPLUG团队拿下新SOTA。
Jiajun Xu : Meta AI科学家,专注大模型和智能眼镜开发。南加州大学博士,Linkedin Top AI Voice,畅销书作家。他的AI科普绘本AI for Babies (“宝宝的人工智能”系列,双语版刚在国内出版) 畅销硅谷,曾获得亚马逊儿童软件、编程新书榜榜首。

本篇综述的作者包括来自复旦大学 CodeWisdom 团队的研究生刘俊伟、王恺欣、陈逸轩和彭鑫教授、娄一翎青年副研究员,以及南洋理工大学的陈震鹏研究员和伊利诺伊大学厄巴纳 - 香槟分校(UIUC)的张令明教授。
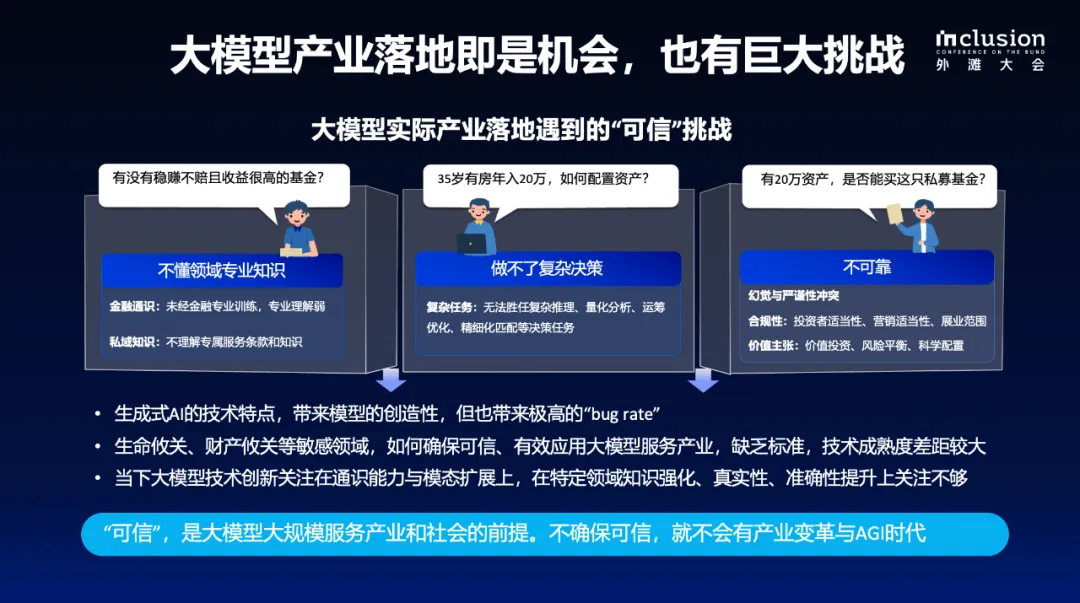
近日,在 2024 Inclusion・外滩大会 “超越平面思维,图计算让 AI 洞悉复杂世界” 见解论坛上,蚂蚁集团知识图谱负责人梁磊分享了 “构建知识增强的专业智能体” 相关工作,并带来了知识图谱与大模型结合最新研发成果 —— 知识增强大模型服务框架 KAG。

近年来,大模型的高速发展极大地改变了人工智能的格局。对齐(Alignment) 是使大模型的行为符合人类意图和价值观,引导大模型按照人类的需求和期望进化的核心步骤,因此受到学术界和产业界的高度关注。

X-Gaussian是一种新型的3D Gaussian Splatting框架,专为X光新视角合成而设计,以减少医疗成像中的X光辐射剂量,通过高效的渲染技术,能够在保持图像质量的同时显著减少训练时间和提升推理速度。

本文第一作者为 Chuanyang Jin (金川杨),本科毕业于纽约大学,即将前往 JHU 读博。本文为他本科期间在 MIT 访问时的工作,他是最年轻的杰出论文奖获得者之一。

上下文学习(In-Context Learning, ICL)是指LLMs能够仅通过提示中给出的少量样例,就迅速掌握并执行新任务的能力。这种“超能力”让LLMs表现得像是一个"万能学习者",能够在各种场景下快速适应并产生高质量输出。然而,关于ICL的内部机制,学界一直存在争议。

把Llama 3蒸馏到Mamba,推理速度最高可提升1.6倍!