

为什么AI数不清Strawberry里有几个 r?Karpathy:我用表情包给你解释一下
为什么AI数不清Strawberry里有几个 r?Karpathy:我用表情包给你解释一下让模型知道自己擅长什么、不擅长什么是一个很重要的问题。
来自主题: AI资讯
8830 点击 2024-07-27 19:02
让模型知道自己擅长什么、不擅长什么是一个很重要的问题。

牛津剑桥的9次投毒导致模型崩溃的论文,已经遭到了诸多吐槽:这也能上Nature?学术圈则对此进行了进一步讨论,大家的观点殊途同归:合成数据被很多人视为灵丹妙药,但天下没有免费的午餐。

伴随着人工智能的高速发展,用户或创作者与平台间围绕AI侵权的纠纷时有发生。

具身智能是实现通用人工智能的必经之路,其核心是通过智能体与数字空间和物理世界的交互来完成复杂任务。

华盛顿大学和Allen AI最近发表的论文提出了一种新颖有趣的数据合成方法。他们发现,充分利用LLM的自回归特性,可以引导模型自动生成高质量的指令微调数据。
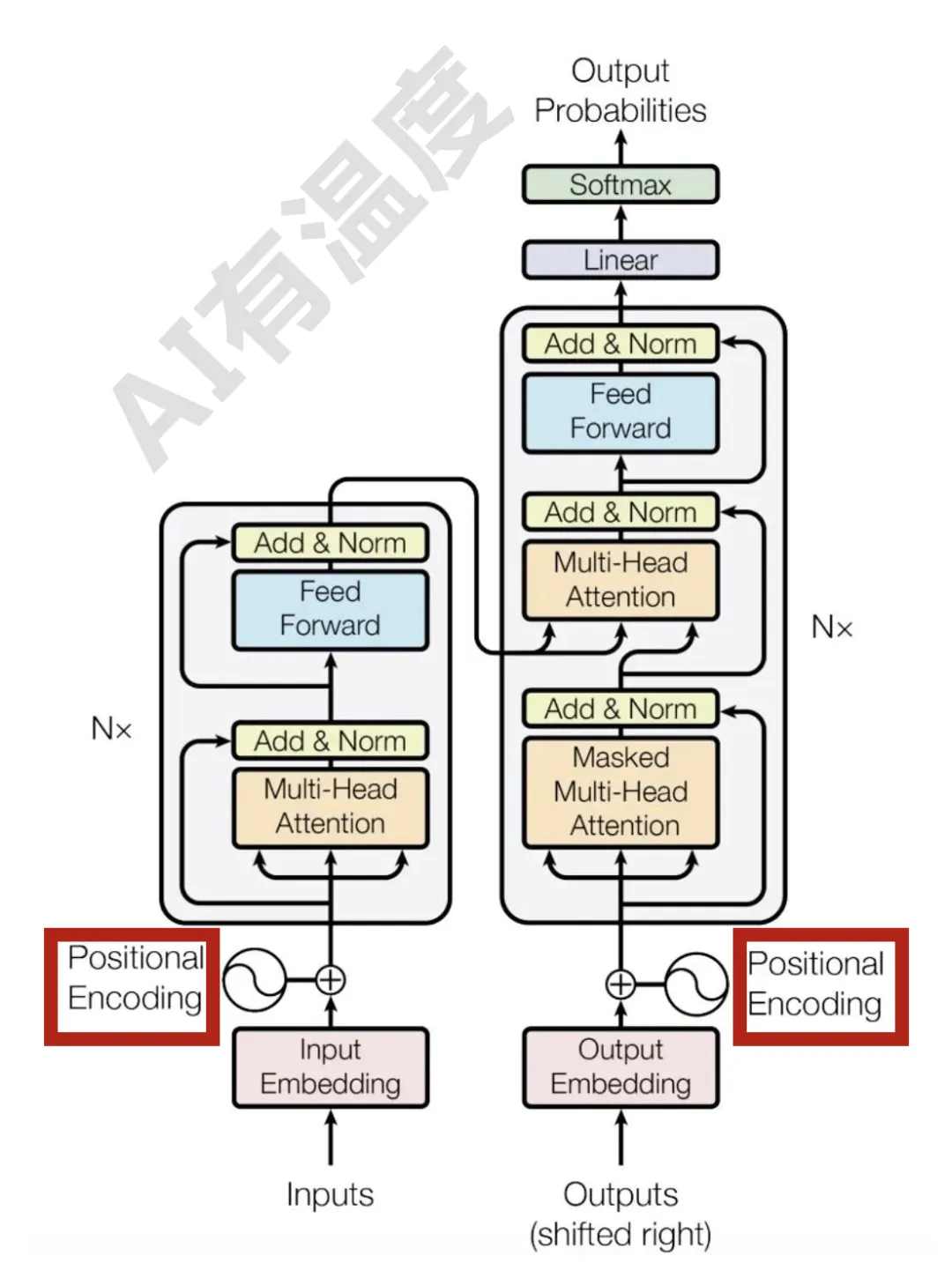
RNN每个step的隐状态都取决于上一个step的输出,这种连续的状态转移方式使得RNN天然带有位置信息。

Transformer中的信息流动机制,被最新研究揭开了:

9次迭代后,模型开始出现诡异乱码,直接原地崩溃!就在今天,牛津、剑桥等机构的一篇论文登上了Nature封面,称合成数据就像近亲繁殖,效果无异于投毒。有无破解之法?那就是——更多使用人类数据!

本文介绍清华大学的一篇关于长尾视觉识别的论文: Probabilistic Contrastive Learning for Long-Tailed Visual Recognition. 该工作已被 TPAMI 2024 录用,代码已开源。

OpenAI 的新奖励机制,让大模型更听话了。