

谷歌DeepMind全新ToT基准:全面评估LLM时间推理能力
谷歌DeepMind全新ToT基准:全面评估LLM时间推理能力近日,来自谷歌DeepMind的研究人员,推出了专门用于评估大语言模型时间推理能力的基准测试——Test of Time(ToT),从两个独立的维度分别考察了LLM的时间理解和算术能力。
来自主题: AI技术研报
10202 点击 2024-07-05 16:35
近日,来自谷歌DeepMind的研究人员,推出了专门用于评估大语言模型时间推理能力的基准测试——Test of Time(ToT),从两个独立的维度分别考察了LLM的时间理解和算术能力。

大模型当上福尔摩斯,学会对视频异常进行检测了。 来自华中科技大学、百度、密歇根大学的研究团队,提出了一种可解释性的视频异常检测框架,名为Holmes-VAD。

苍蝇再小也是肉,聚沙成塔。
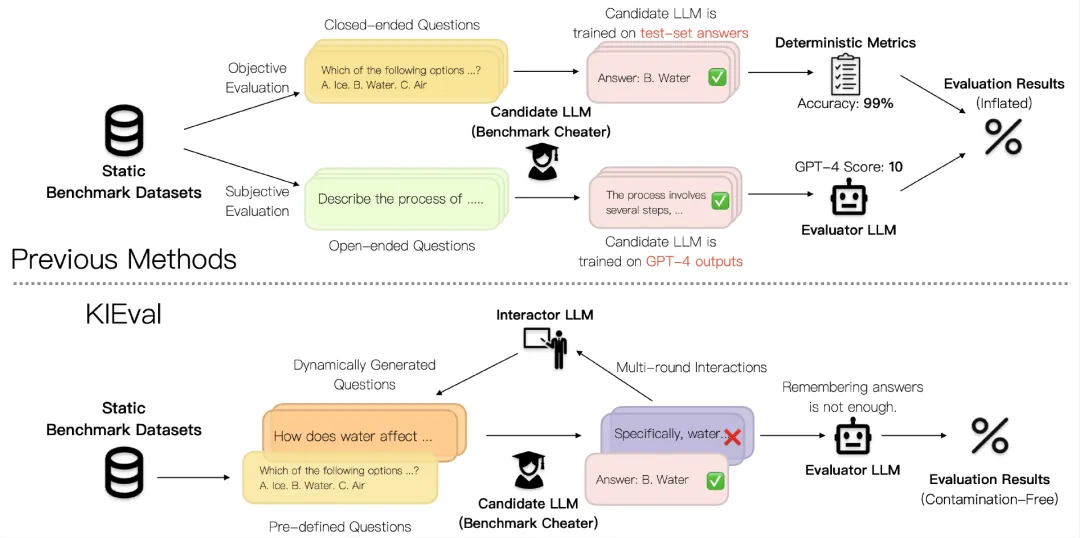
当前大语言模型(LLM)的评估方法受到数据污染问题的影响,导致评估结果被高估,无法准确反映模型的真实能力。北京大学等提出的KIEval框架,通过知识基础的交互式评估,克服了数据污染的影响,更全面地评估了模型在知识理解和应用方面的能力。

只要把推理和感知能力拆分,2B大模型就能战胜20B?!

神经网络通常由三部分组成:线性层、非线性层(激活函数)和标准化层。线性层是网络参数的主要存在位置,非线性层提升神经网络的表达能力,而标准化层(Normalization)主要用于稳定和加速神经网络训练,很少有工作研究它们的表达能力,例如,以Batch Normalization为例
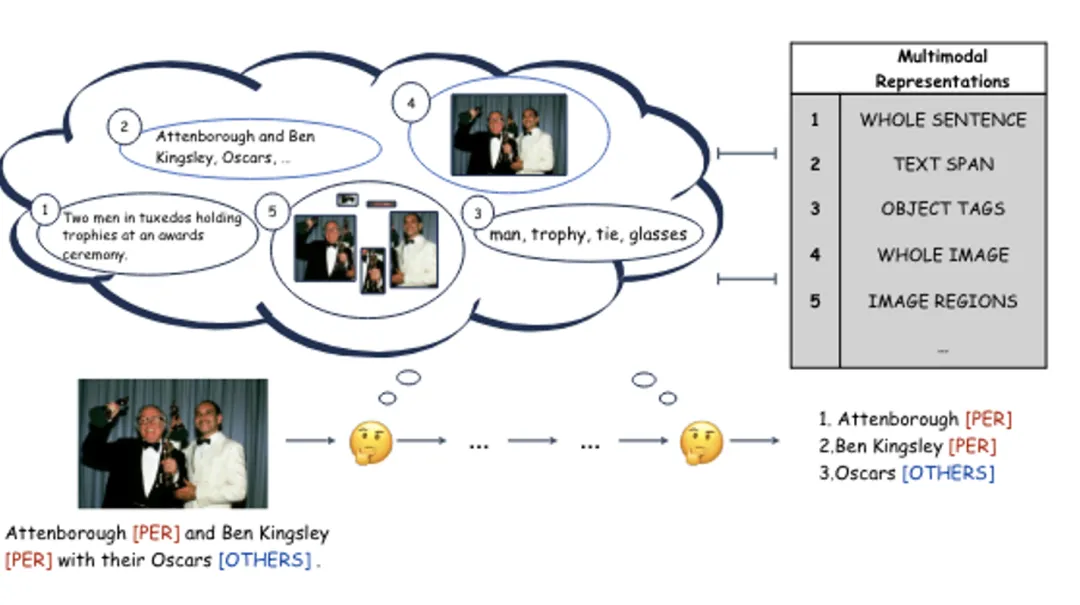
多模态命名实体识别,作为构建多模态知识图谱的一项基础而关键任务,要求研究者整合多种模态信息以精准地从文本中提取命名实体。尽管以往的研究已经在不同层次上探索了多模态表示的整合方法,但在将这些多模态表示融合以提供丰富上下文信息、进而提升多模态命名实体识别的性能方面,它们仍显不足。

「微调你的模型,获得比GPT-4更好的性能」不只是说说而已,而是真的可操作。最近,一位愿意动手的ML工程师就把几个开源LLM调教成了自己想要的样子。

本文研究发现大语言模型在持续预训练过程中出现目标领域性能先下降再上升的现象。

只要将注意力切块,就能让大模型解码提速20倍。