

字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果
字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。
来自主题: AI技术研报
9541 点击 2024-06-17 19:35
当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。
在三维生成建模的研究领域,现行的两大类 3D 表示方法要么基于拟合能力不足的隐式解码器,要么缺乏清晰定义的空间结构难以与主流的 3D 扩散技术融合。来自中科大、清华和微软亚洲研究院的研究人员提出了 GaussianCube,这是一种具有强大拟合能力的显式结构化三维表示,并且可以无缝应用于目前主流的 3D 扩散模型中。

「原来以为语料已经匮乏了,大模型训练已经没有语料了,实际上不是的,数据还远远没有跑光」。

GPT-4o掀起一股全模态(Omni-modal)热潮,去年的热词多模态仿佛已经不够看了。
来自浙江大学和伊利诺伊大学厄巴纳-香槟分校的研究者发表了他们关于「表格语言模型」(Tabular Language Model)的研究成果

人类的教育方式,对大模型而言也很适用。
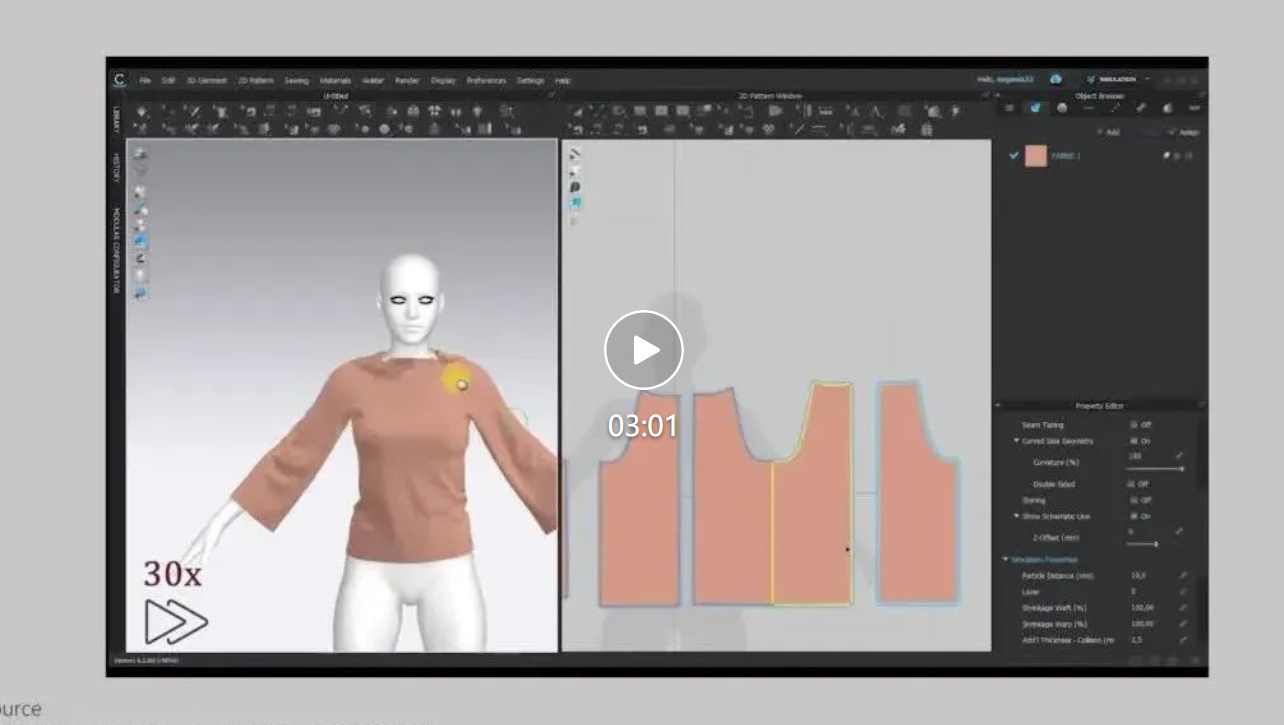
3D生成是生成式人工智能和计算机图形学领域最引人注目的话题之一,符合影视、游戏标准的3D生成尤其受产业界关注。在生产流程中,一般品类的3D资产往往通过手工建模或者扫描的方式制作。但作为3D资产的一个重要类别,服装资产的往往来源于平面板片与物理模拟等流程,而不是直接在3D上建模。
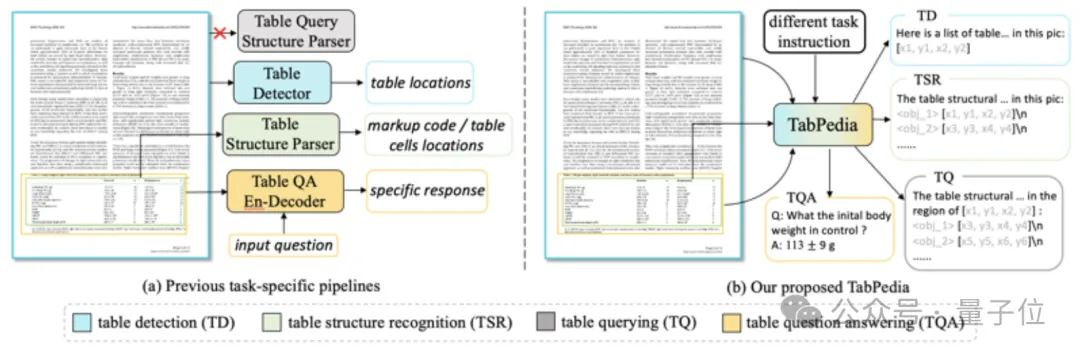
只要一个大模型,就能解决打工人遇到的表格难题!

在CV、ML等领域经常用到的神经场网格模型,如今有了理论框架描述其训练动力学和泛化性能。
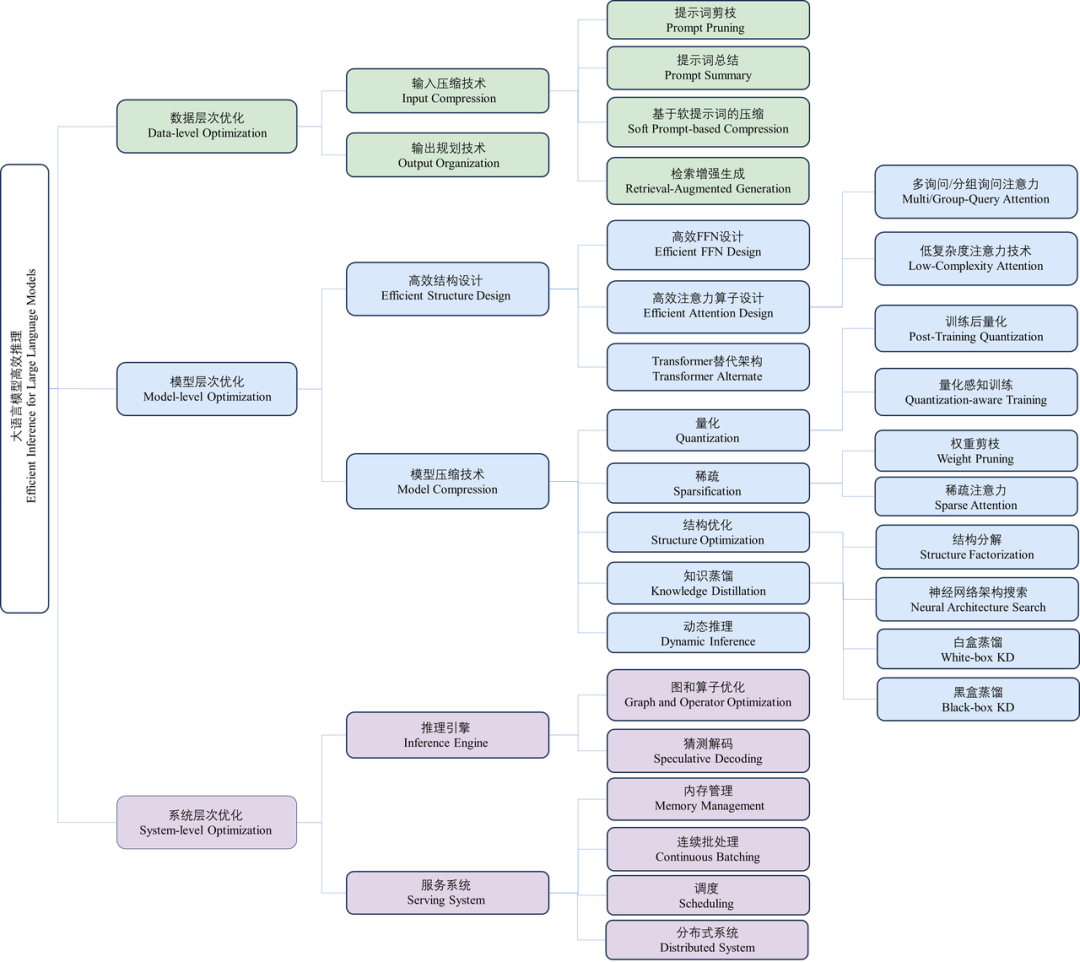
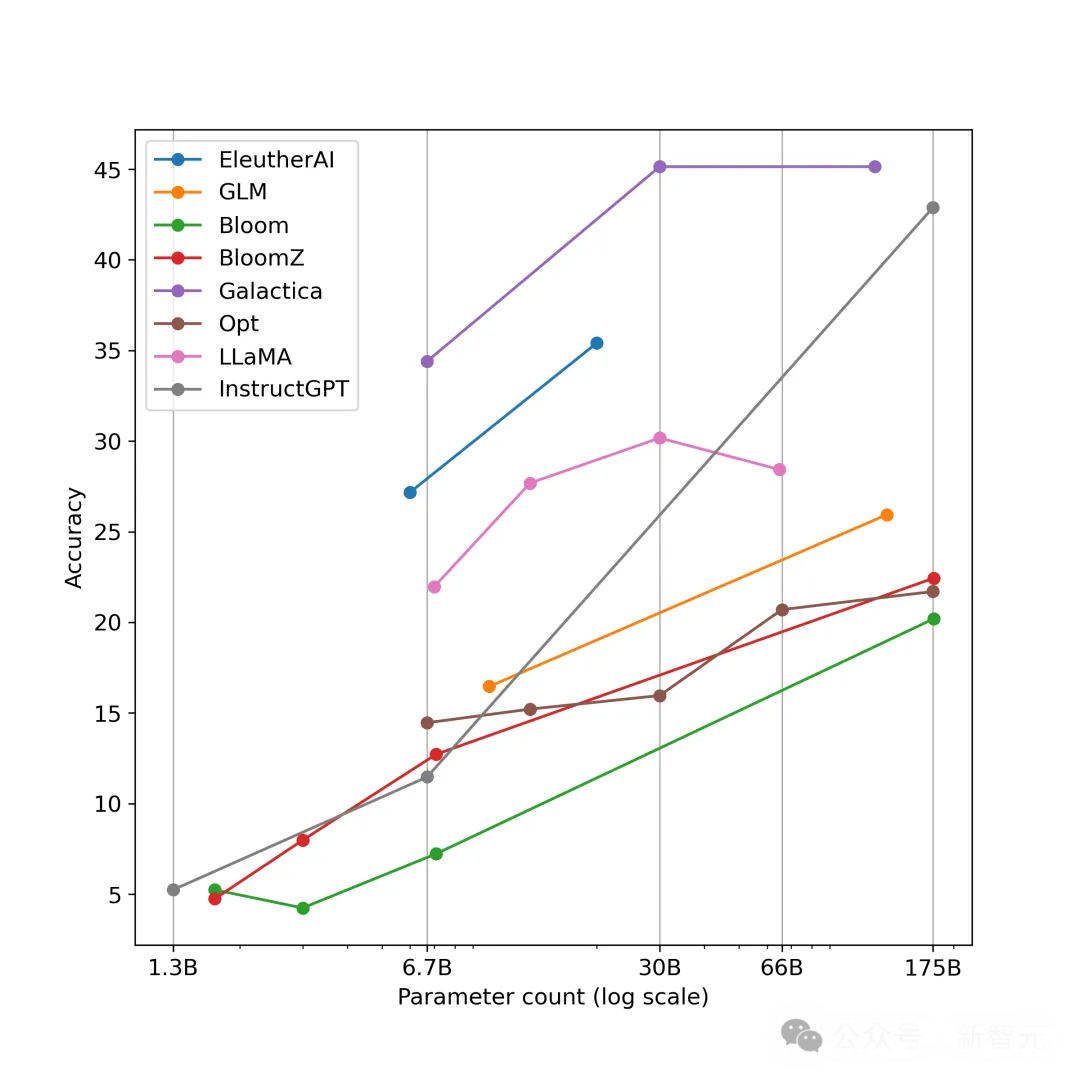
近年来,大语言模型(Large Language Models, LLMs)受到学术界和工业界的广泛关注,得益于其在各种语言生成任务上的出色表现,大语言模型推动了各种人工智能应用(例如ChatGPT、Copilot等)的发展。然而,大语言模型的落地应用受到其较大的推理开销的限制,对部署资源、用户体验、经济成本都带来了巨大挑战。