

解决Transformer根本缺陷,CoPE论文爆火:所有大模型都能获得巨大改进
解决Transformer根本缺陷,CoPE论文爆火:所有大模型都能获得巨大改进即使最强大的 LLM 也难以通过 token 索引来关注句子等概念,现在有办法了。
来自主题: AI资讯
9611 点击 2024-05-31 19:10
即使最强大的 LLM 也难以通过 token 索引来关注句子等概念,现在有办法了。

无需采集3D数据,也能训练出高质量的3D自动驾驶场景生成模型。

在当今数字化时代,3D 资产在元宇宙的建构、数字孪生的实现以及虚拟现实和增强现实的应用中扮演着重要角色,促进了技术创新和用户体验的提升。

高质量图像编辑的方法有很多,但都很难准确表达出真实的物理世界。 那么,Edit the World试试。

在大模型实际部署落地的过程中,如何赋予大模型持续学习的能力是一个至关重要的挑战。这使其能够动态适应新的任务并不断获得新的知识。大模型的持续学习主要面临两个重大挑战,分别是灾难性遗忘和知识迁移。灾难性遗忘是指模型在学习新任务时,会忘记其已掌握的旧任务。知识迁移则涉及到如何在学习新任务时有效地应用旧任务的知识来提升新任务学习的效果。
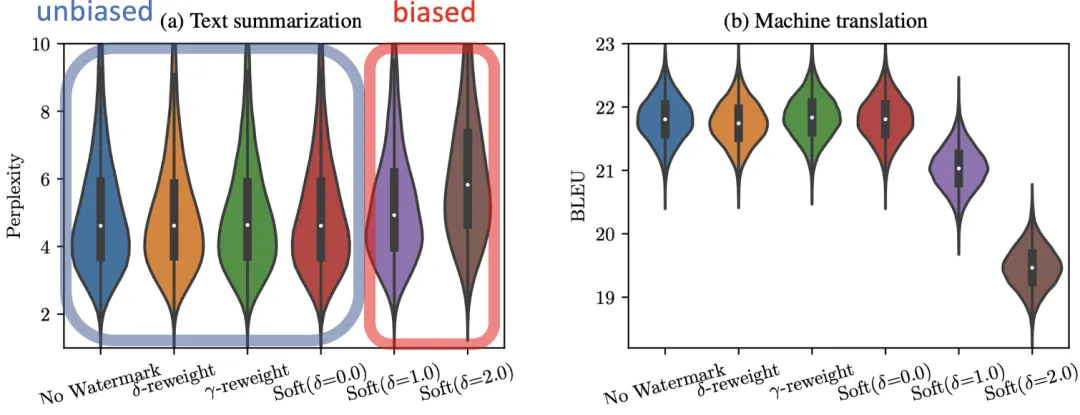
随着大语言模型(LLM)的快速发展,其在文本生成、翻译、总结等任务中的应用日益广泛。如微软前段时间发布的Copilot+PC允许使用者利用生成式AI进行团队内部实时协同合作,通过内嵌大模型应用,文本内容可能会在多个专业团队内部快速流转,对此,为保证内容的高度专业性和传达效率,同时平衡内容追溯、保证文本质量的LLM水印方法显得极为重要。

iVideoGPT,满足世界模型高交互性需求。

通过提示查询生成模块和任务感知适配器,大一统框架VimTS在不同任务间实现更好的协同作用,显著提升了模型的泛化能力。该方法在多个跨域基准测试中表现优异,尤其在视频级跨域自适应方面,仅使用图像数据就实现了比现有端到端视频识别方法更高的性能。
福无双至,祸不单行,Google 又又又「翻车」了。

将一个实验性质的功能直接推向用户,谷歌有些急功近利了。