

150B token从头训练,普林斯顿Meta发布完全可微MoE架构Lory
150B token从头训练,普林斯顿Meta发布完全可微MoE架构Lory前几天,普林斯顿大学联合Meta在arXiv上发表了他们最新的研究成果——Lory模型,论文提出构建完全可微的MoE模型,是一种预训练自回归语言模型的新方法。
来自主题: AI技术研报
10901 点击 2024-05-20 16:10
前几天,普林斯顿大学联合Meta在arXiv上发表了他们最新的研究成果——Lory模型,论文提出构建完全可微的MoE模型,是一种预训练自回归语言模型的新方法。

大语言模型可谓是迄今为止对人类行为最大的建模,如何借助大语言模型工具,让科技发展更好地应用到真实人类社会中去?从哈佛物理系到大语言模型结合社会学和经济学的研究,朱科航的思考路径,聚焦在对人类行为的深度学习和理解。在开始今天阅读之前,大家不妨先猜一猜,大语言模型之前人类应用最广的 TOP2 机器学习是什么?Enjoy

本月初,来自 MIT 等机构的研究者提出了一种非常有潜力的 MLP 替代方法 ——KAN。

在线和离线对齐算法的性能差距根源何在?DeepMind实证剖析出炉

“Scaling Law不是万金油”——关于大模型表现,华为又提出了新理论。

近年来,定制化的人物生成技术在社区中引起了广泛关注。

谷歌表示,Gemini 1.5 相比 Claude 3.0 和 GPT-4 Turbo 实现了代际提升。
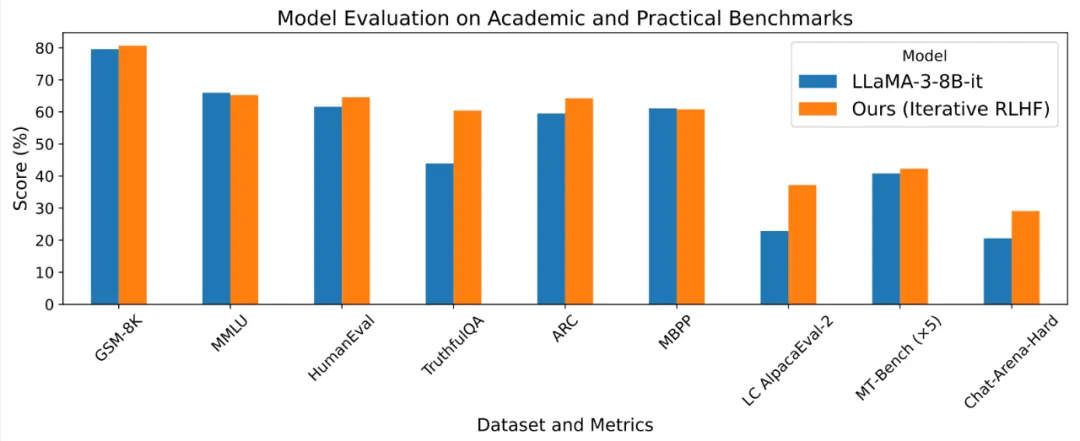
基于人类反馈的强化学习 (RLHF) 使得大语言模型的输出能够更加符合人类的目标、期望与需求,是提升许多闭源语言模型 Chat-GPT, Claude, Gemini 表现的核心方法之一。

本周,生成式 AI 的竞争达到了新的高潮。

前有OpenAI的GPT-4o,后有谷歌的系列王炸,先进的多模态大模型接连炸场。