
如何从零开始训练大模型(minicpm分享&讨论)
如何从零开始训练大模型(minicpm分享&讨论)根据scaling law,模型越大,高质量数据越多,效果越好。 但还有一个很直观的情况,随着预训练样本的质量不断提升,训练手段的优化。新的模型,往往效果能轻松反超参数量两倍于它的模型。
来自主题: AI技术研报
3652 点击 2024-03-19 15:55
根据scaling law,模型越大,高质量数据越多,效果越好。 但还有一个很直观的情况,随着预训练样本的质量不断提升,训练手段的优化。新的模型,往往效果能轻松反超参数量两倍于它的模型。

【新智元导读】利用文本生成图片(Text-to-Image, T2I)已经满足不了人们的需要了,近期研究在T2I模型的基础上引入了更多类型的条件来生成图像,本文对这些方法进行了总结综述。

以脉冲神经网络(SNN)为代表的脑启发神经形态计算(neuromorphic computing)由于计算上的节能性质在最近几年受到了越来越多的关注 [1]。受启发于人脑中的生物神经元,神经形态计算通过模拟并行的存内计算、基于脉冲信号的事件驱动计算等生物特性,能够在不同于冯诺依曼架构的神经形态芯片上以低功耗实现神经网络计算。

Fast-DetectGPT 同时做到了高准确率、高速度、低成本、通用,扫清了实际应用的障碍!
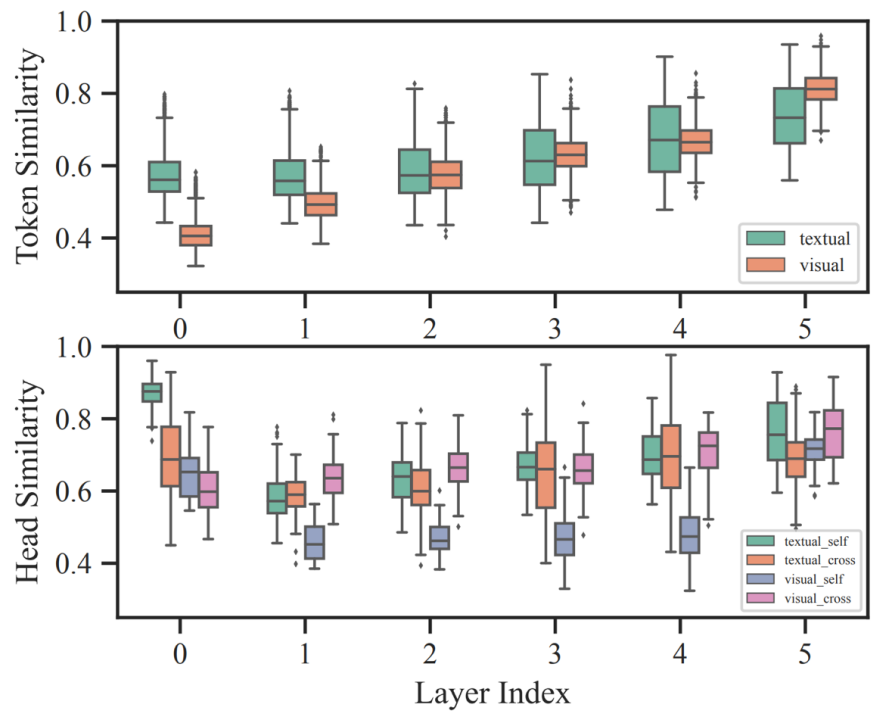
哈工大联合度小满推出针对多模态模型的自适应剪枝算法 SmartTrim,论文已被自然语言处理顶级会议 COLING 24 接收。

最近,OpenAI CTO Murati接受采访时,对Sora训练数据语焉不详、支支吾吾的表现,已经成了全网热议的话题。毕竟,要是一个处理不好,OpenAI就又要陷入巨额赔偿金的诉讼之中了。

MIT新晋副教授何恺明,新作新鲜出炉:瞄准一个横亘在AI发展之路上十年之久的问题:数据集偏差。数据集偏差之战,在2011年由知名学者Antonio Torralba和Alyosha Efros提出——

TimesFM针对时序数据设计,输出序列长于输入序列,在1000亿时间点数据进行预训练后,仅用200M参数量就展现出超强零样本学习能力!

StepCoder将长序列代码生成任务分解为代码完成子任务课程来缓解强化学习探索难题,对未执行的代码段以细粒度优化;还开源了可用于强化学习训练的APPS+数据集。
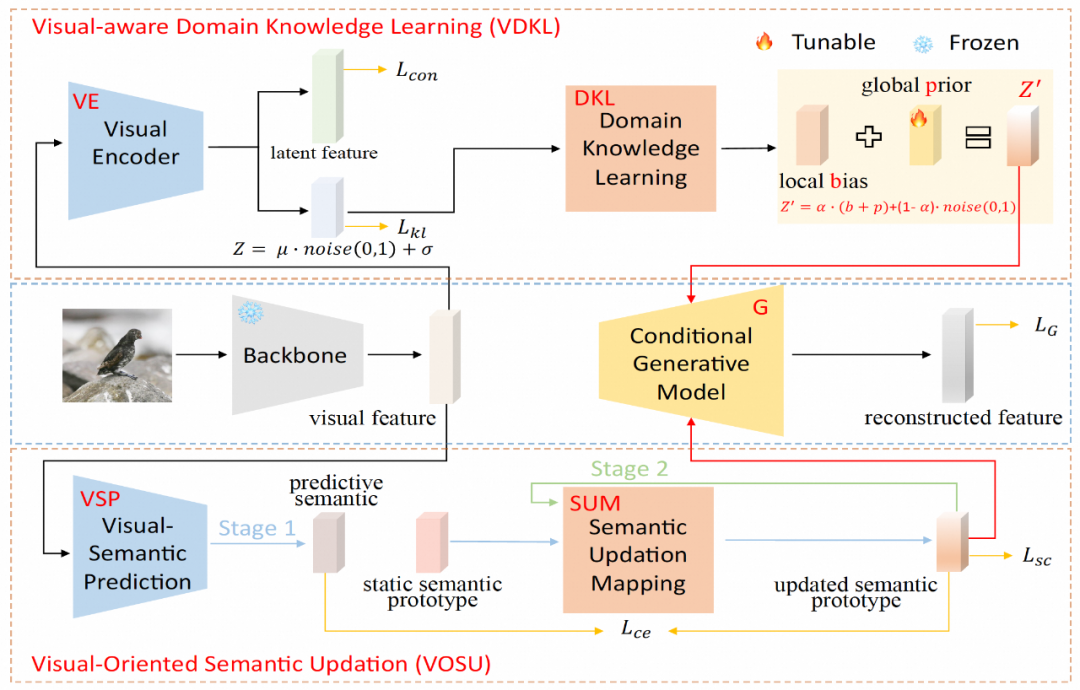
虽然我从来没见过你,但是我有可能「认识」你 —— 这是人们希望人工智能在「一眼初见」下达到的状态。