
谷歌最新AI芯片打平英伟达B200,专为推理模型打造,最高配每秒42500000000000000000次浮点运算
谷歌最新AI芯片打平英伟达B200,专为推理模型打造,最高配每秒42500000000000000000次浮点运算谷歌首款AI推理特化版TPU芯片来了,专为深度思考模型打造。
来自主题: AI资讯
9814 点击 2025-04-10 12:37
 搜索
搜索
谷歌首款AI推理特化版TPU芯片来了,专为深度思考模型打造。
Q-Insight不再简单地让模型拟合人眼打分,而是将评分视作一种引导信号,促使模型深度思考图像质量的本质原因。有了会思考的“大脑”,视频云技术栈不仅得以重塑也让用户体验有了跃迁。
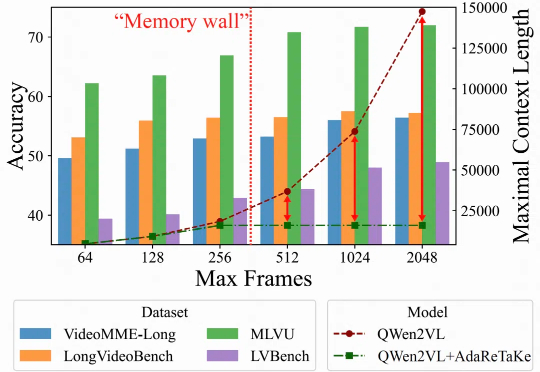
随着视频内容的重要性日益提升,如何处理理解长视频成为多模态大模型面临的关键挑战。长视频理解能力,对于智慧安防、智能体的长期记忆以及多模态深度思考能力有着重要价值。
阿里又发了个有意思的大模型——QVQ-Max,第一版视觉推理模型,对任意图像或视频都可以进行深度思考。
今天晚上,就在刚刚,豆包终于上了之前很多人期待的功能,深度思考。我之前用别人的账号体验过这功能,就是推理模型,而今天看到的第一刻,我以为的是,豆包的推理模型终于全量上线了。

首个基于混合Mamba架构的超大型推理模型来了!就在刚刚,腾讯宣布推出自研深度思考模型混元T1正式版,并同步在腾讯云官网上线。对标o1、DeepSeek R1之外,值得关注的是,混元T1正式版采用的是Hybrid-Mamba-Transformer融合模式——
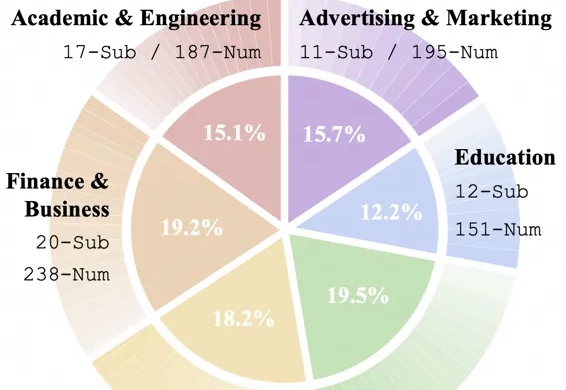
全面评估大模型生成式写作能力的基准来了!
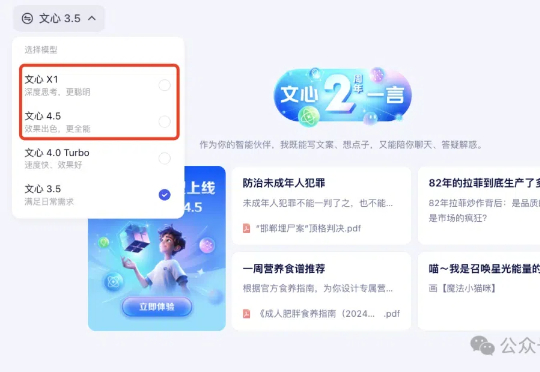
百度文心大模型重磅更新,刚刚如期而至。
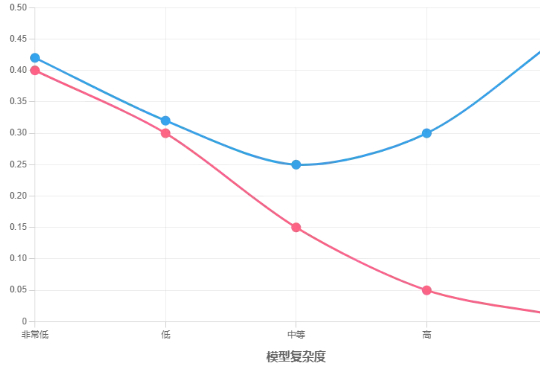
当模型复杂度增加到一定程度后,模型开始对训练数据中的噪声和异常值进行拟合,而不是仅仅学习数据中的真实模式。这导致模型在训练数据上表现得非常好,但在新的数据上表现不佳,因为新的数据中噪声和异常值的分布与训练数据不同。
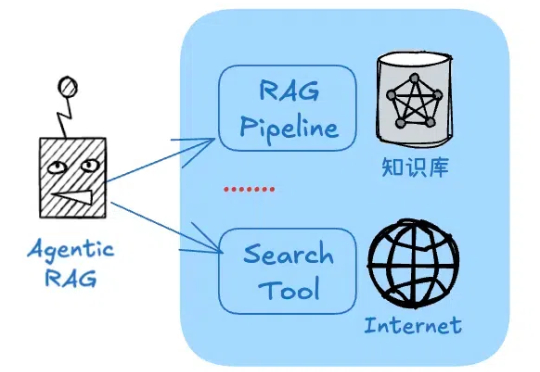
RAG是一种基于“检索结果”做推理的应用,这大大限制了类似DeepSeek-R1模型的发挥空间。但又的确存在将RAG的准确性与DeepSeek深度思考能力结合的场景,而不仅仅是回答事实性问题。比如: