刚刚,DeepSeek能看懂猫片了!腾讯混元加持
刚刚,DeepSeek能看懂猫片了!腾讯混元加持DeepSeek能看懂图片了!
来自主题: AI资讯
7356 点击 2025-02-21 16:40
 搜索
搜索
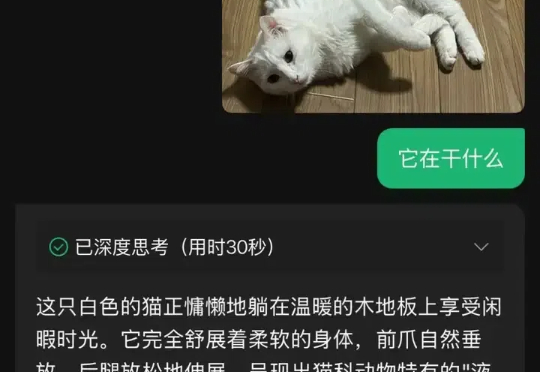
DeepSeek能看懂图片了!

这应该是我知道的第一家有自己大模型的大厂,第一次在面向C端的AI助手应用中,第一次接入DeepSeek R1。这个意义影响还是非常深远的,腾讯在AI这一步上,好像走的格外的开放,从之前的批量开源MoE、混元绘图模型、混元视频模型、混元3D模型,还有今天这神之一手接入DeepSeek R1。
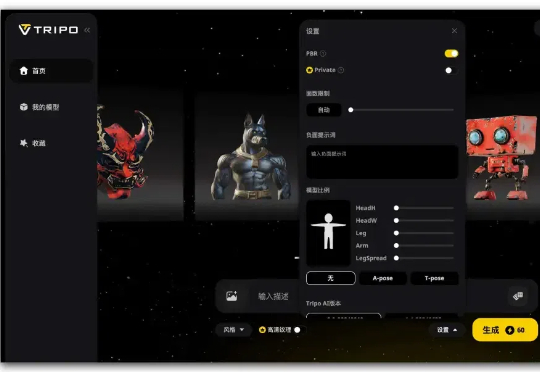
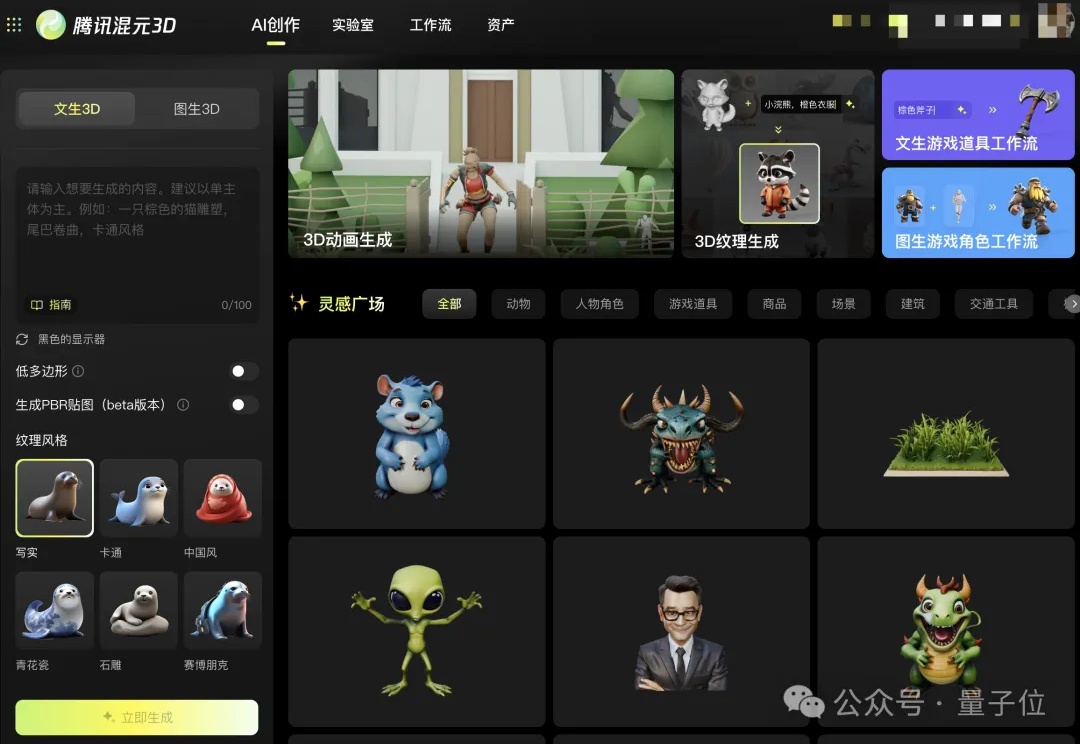
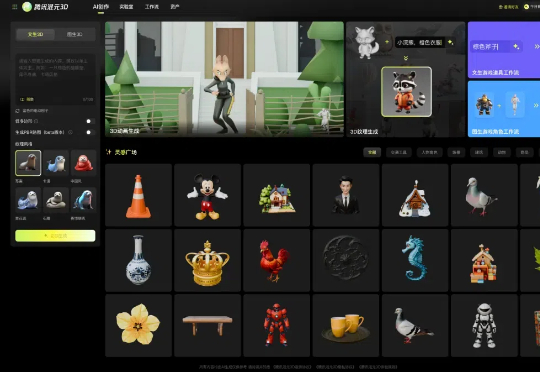
就在刚刚,腾讯混元3D全新版本上线了。这一周内我在混元3D、Tripo3D、Meshy这三家AI 3D里跑了上百次案例,在文生3D、图生3D、纹理材质生成、3D工作流四个维度,让小白也能最大程度体验到AI 3D能做到什么,以及将如何影响AI生图、AI视频的工作流。
春节前夕,腾讯又发AI大礼包。
早上MiniMax上线TTS,字节上线AI编程Trae;下午字节全量上线豆包实时语音;晚上DeepSeek开源R1性能直接对标OpenAI o1,然后Kimi的k1.5直接正面硬刚。昨天的余温还没过,今天下午,腾讯混元又悄悄开了个闭门发布会,作为混元的老基友,我自然是受邀参加期期不落。
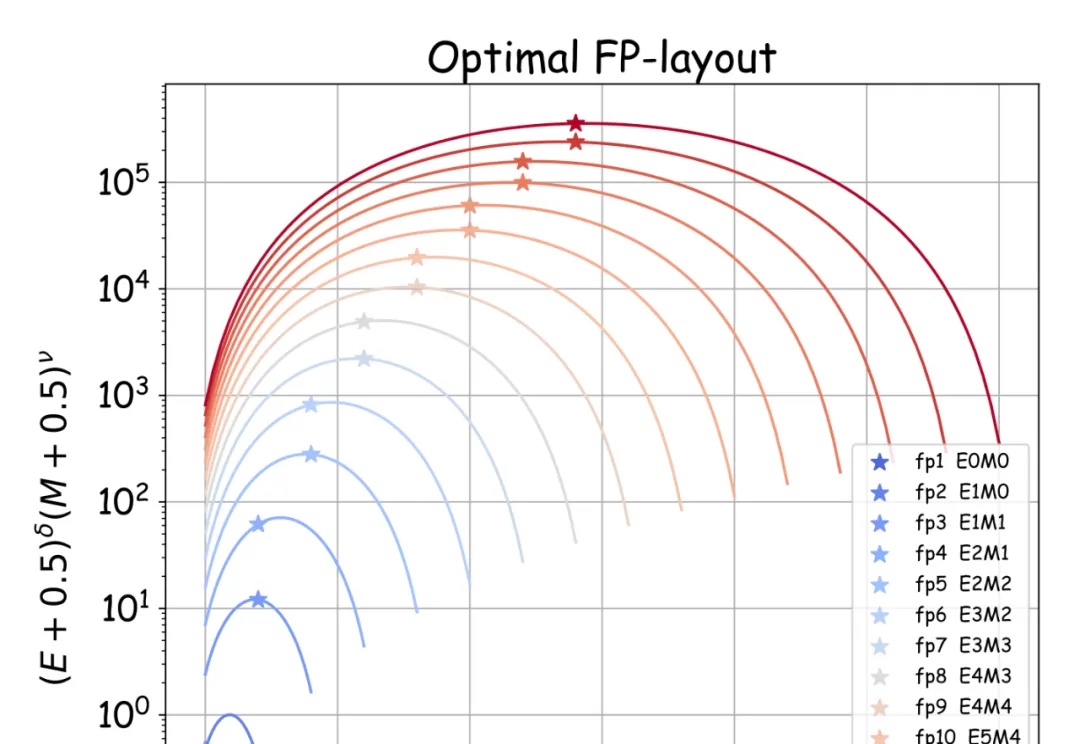
大模型低精度训练和推理是大模型领域中的重要研究方向,旨在通过降低模型精度来减少计算和存储成本,同时保持模型的性能。因为在大模型研发成本降低上的巨大价值而受到行业广泛关注 。

1 月 18 日,北京,聊聊 2025 如何加入技术开发? AI 科技评论消息称,前微软亚洲研究院视觉计算组首席研究员胡瀚,不久前加入腾讯,接替已离职的前腾讯混元大模型技术负责人之一的刘威,负责多模态大模型的研发工作。

提速8倍! 速度更快、效果更好的混元视频模型——FastHunyuan来了! 新模型仅用1分钟就能生成5秒长的视频,比之前提速8倍,步骤也从50步减少到了6步,甚至画面细节也更逼真了。

OpenAI的正式版Sora终于上线了!
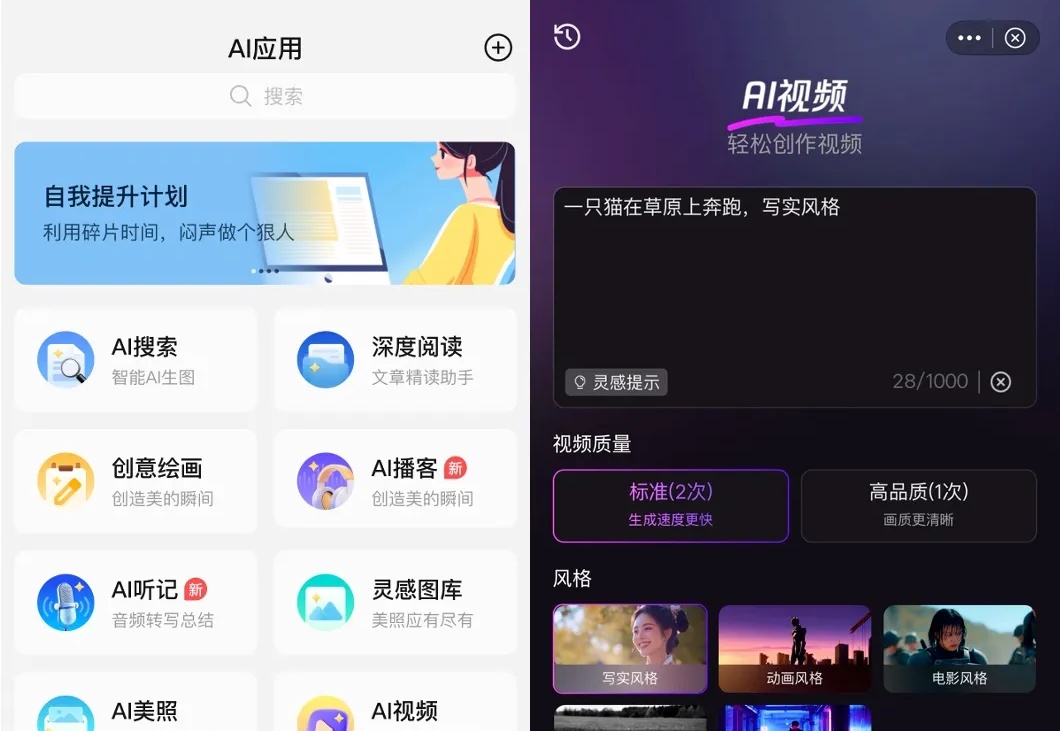
想要体验文生视频的小伙伴又多了一个选择!