
清华"挖"来美国顶尖AI学者
清华"挖"来美国顶尖AI学者香港英文媒体《南华早报》29日援引两名知情人士的话报道称,微软研究院纽约实验室的高级研究员兰姆(Alex Lamb)将于即将到来的秋季学期加入新成立的清华大学人工智能学院(College of AI),担任助理教授。兰姆在一封电子邮件中证实了这一消息。
来自主题: AI资讯
9308 点击 2025-04-30 09:25
 搜索
搜索
香港英文媒体《南华早报》29日援引两名知情人士的话报道称,微软研究院纽约实验室的高级研究员兰姆(Alex Lamb)将于即将到来的秋季学期加入新成立的清华大学人工智能学院(College of AI),担任助理教授。兰姆在一封电子邮件中证实了这一消息。

满血DeepSeek一体机,价格竟然被打到10万元级别了!
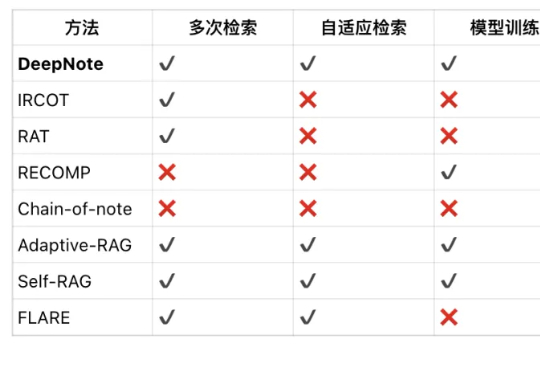
在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。
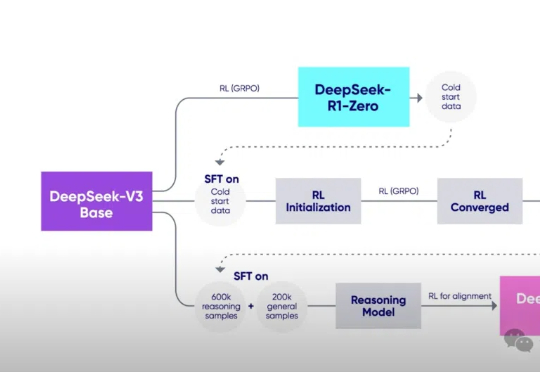
一项来自清华大学和上海交通大学的研究颠覆了对可验证奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高了采样效率,而非真正赋予模型全新推理能力。
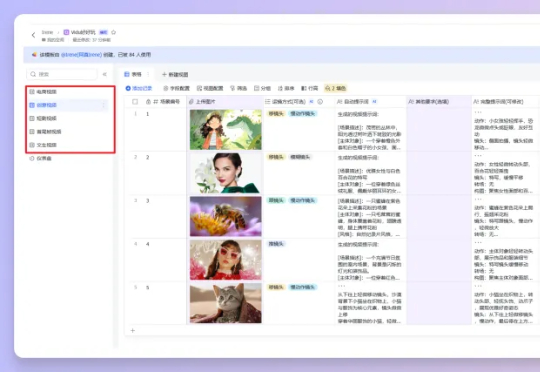
这里介绍一下Vidu,Vidu是由生数科技联合清华大学正式发布的中国首个长时长、高一致性、高动态性视频大模型。Vidu在语义理解、推理速度、动态幅度等方面具备领先优势,并上线了全球首个“多主体参考”功能,突破视频模型一致性生成难题,开启了视觉上下文时代。最近上线了 Vidu Q1 的高质量视频大模型,不仅视频效果质感更高,而且性价比很不错。

ICLR 2025杰出论文揭晓!
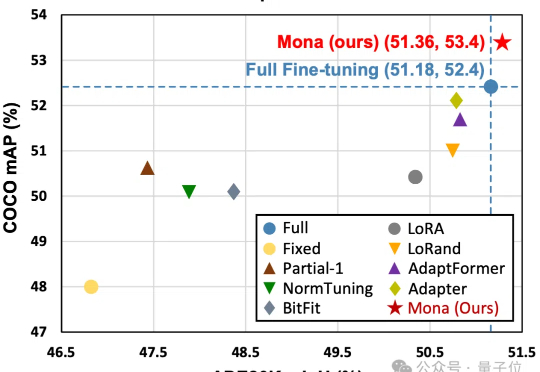
仅调整5%的骨干网络参数,就能超越全参数微调效果?!
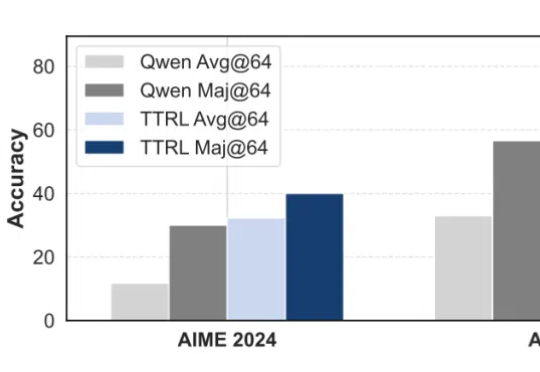
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!
写论文是许多学生面临的共同难题,尤其是在文献的收集与高效利用上。
为什么不能这样