
图灵奖得主预言中国成AI工业翘楚!海淀硬核AI先锋盛会,涌现更多未来成果
图灵奖得主预言中国成AI工业翘楚!海淀硬核AI先锋盛会,涌现更多未来成果2025中关村论坛人工智能主题日,高能不断。清华系团队全新Vidu Q1视频生成可控性再创新高,炫目demo惊艳全场。图灵奖得主Joseph Sifakis、清华朱军、百度王海峰等大咖演讲,更是将论坛推向专业的巅峰。
来自主题: AI资讯
10809 点击 2025-03-30 10:38
 搜索
搜索
2025中关村论坛人工智能主题日,高能不断。清华系团队全新Vidu Q1视频生成可控性再创新高,炫目demo惊艳全场。图灵奖得主Joseph Sifakis、清华朱军、百度王海峰等大咖演讲,更是将论坛推向专业的巅峰。

他们都是来自全球的年轻 AI 学术新星。

在AI领域,最强“小强”指向明确:IOI奥赛金牌得主、清华姚班天才、旷视6号员工——范浩强。公司原力灵机,去年12月17日在海淀区注册,刚刚从水下空降般浮出水面,同日宣布近期完成2亿元天使轮融资,投资方包含君联资本、九坤创投、启明创投。
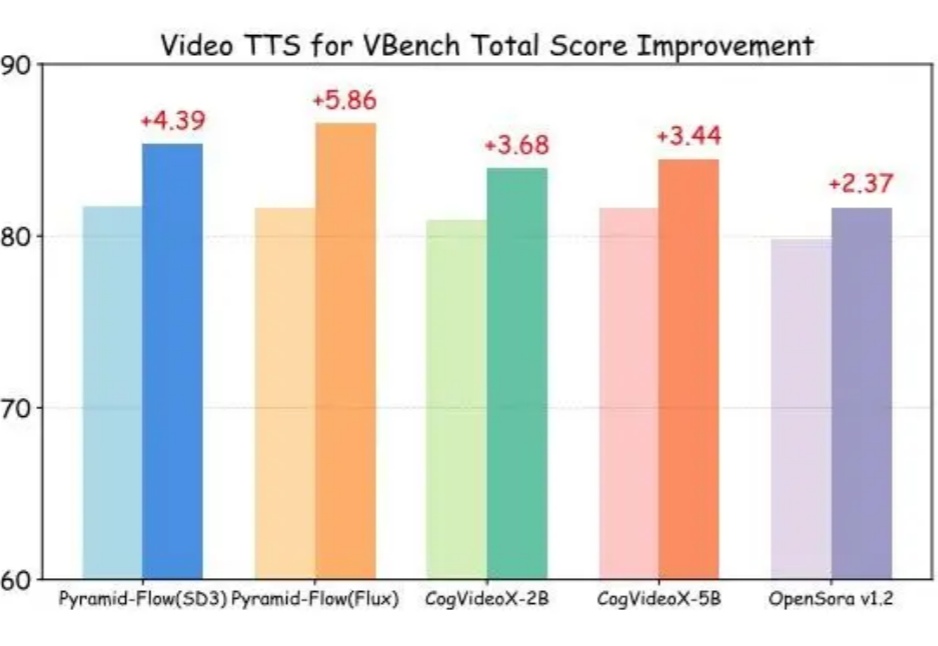
视频作为包含大量时空信息和语义的媒介,对于 AI 理解、模拟现实世界至关重要。视频生成作为生成式 AI 的一个重要方向,其性能目前主要通过增大基础模型的参数量和预训练数据实现提升,更大的模型是更好表现的基础,但同时也意味着更苛刻的计算资源需求。
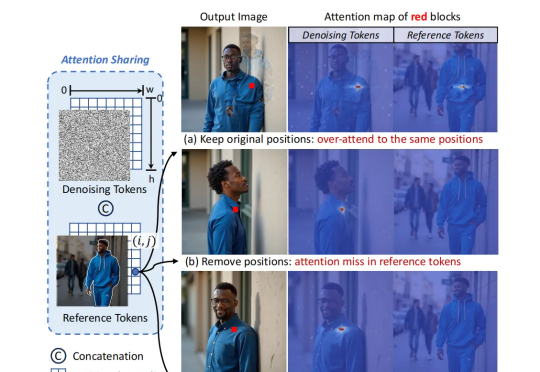
,清华大学、北京航空航天大学团队推出了全新的架构设计 ——Personalize Anything,它能够在无需训练的情况下,完成概念主体的高度细节还原,支持用户对物体进行细粒度的位置操控,并能够扩展至多个应用中,为个性化图像生成引入了一个新范式。
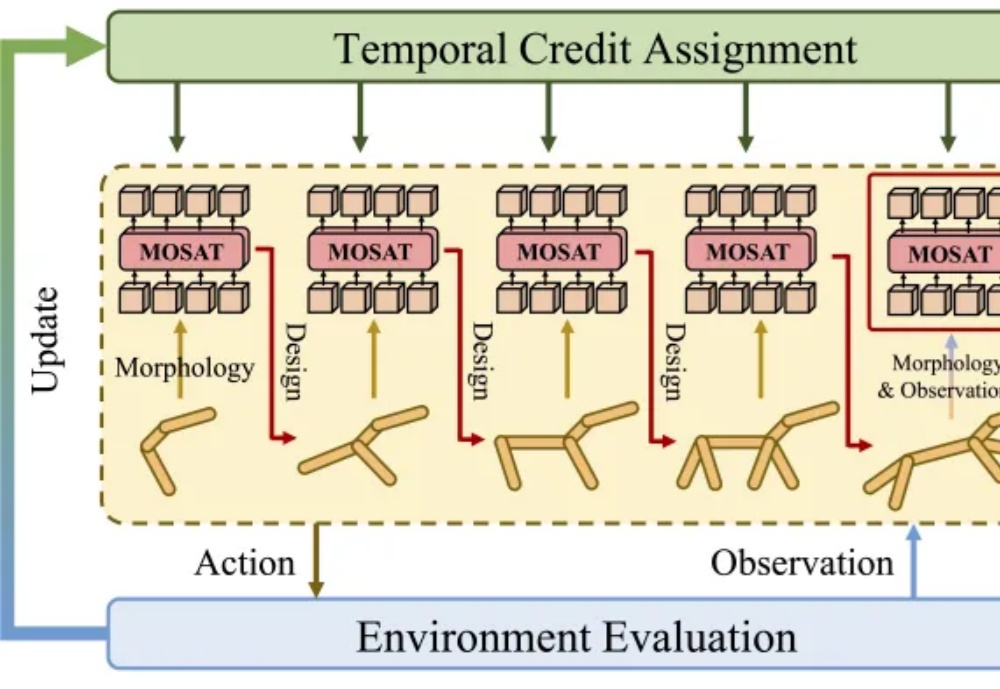
最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由蚂蚁数科与清华大学联合团队提出的全新具身协同框架 BodyGen 成功入选 Spotlight(聚光灯/特别关注)论文。

清华智能产业研究院(AIR)博三在读,去年六月份,出于对语言模型 LLM 的强烈兴趣,加入了字节 as Top Seed Intern,在人工智能的最前沿进行探索。刚好这个话题和我现在做的工作强相关,我分享一下自己的观点和亲身体验。
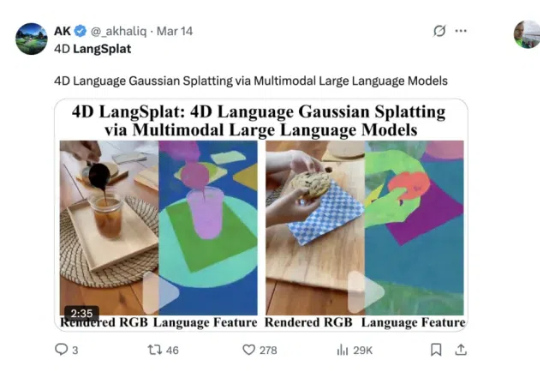
来自清华大学、哈佛大学等机构的研究团队提出了一种创新方法——4D LangSplat。该方法基于动态三维高斯泼溅技术,成功重建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。这一突破为相关领域的研究与应用提供了新的可能性, 该工作目前已经被CVPR2025接收。

任意一张立绘,就可以生成可拆分3D角色!

一个超越DeepSeek GRPO的关键RL算法出现了!这个算法名为DAPO,字节、清华AIR联合实验室SIA Lab出品,现已开源。禹棋赢,01年生,本科毕业于哈工大,直博进入清华AIR,目前博士三年级在读。去年年中,他以研究实习生的身份加入字节首次推出的「Top Seed人才计划」。