
解密中国首个“音乐版Sora” | 中国AIGC产业峰会
解密中国首个“音乐版Sora” | 中国AIGC产业峰会文生图、文生音频、文生视频、AI搜索引擎……大模型在多模态的进程可谓是愈演愈烈。
来自主题: AI技术研报
12373 点击 2024-05-01 19:50
 搜索
搜索
文生图、文生音频、文生视频、AI搜索引擎……大模型在多模态的进程可谓是愈演愈烈。

近期,大语言模型、文生图模型等大规模 AI 模型迅猛发展。在这种形势下,如何适应瞬息万变的需求,快速适配大模型至各类下游任务,成为了一个重要的挑战。受限于计算资源,传统的全参数微调方法可能会显得力不从心,因此需要探索更高效的微调策略。
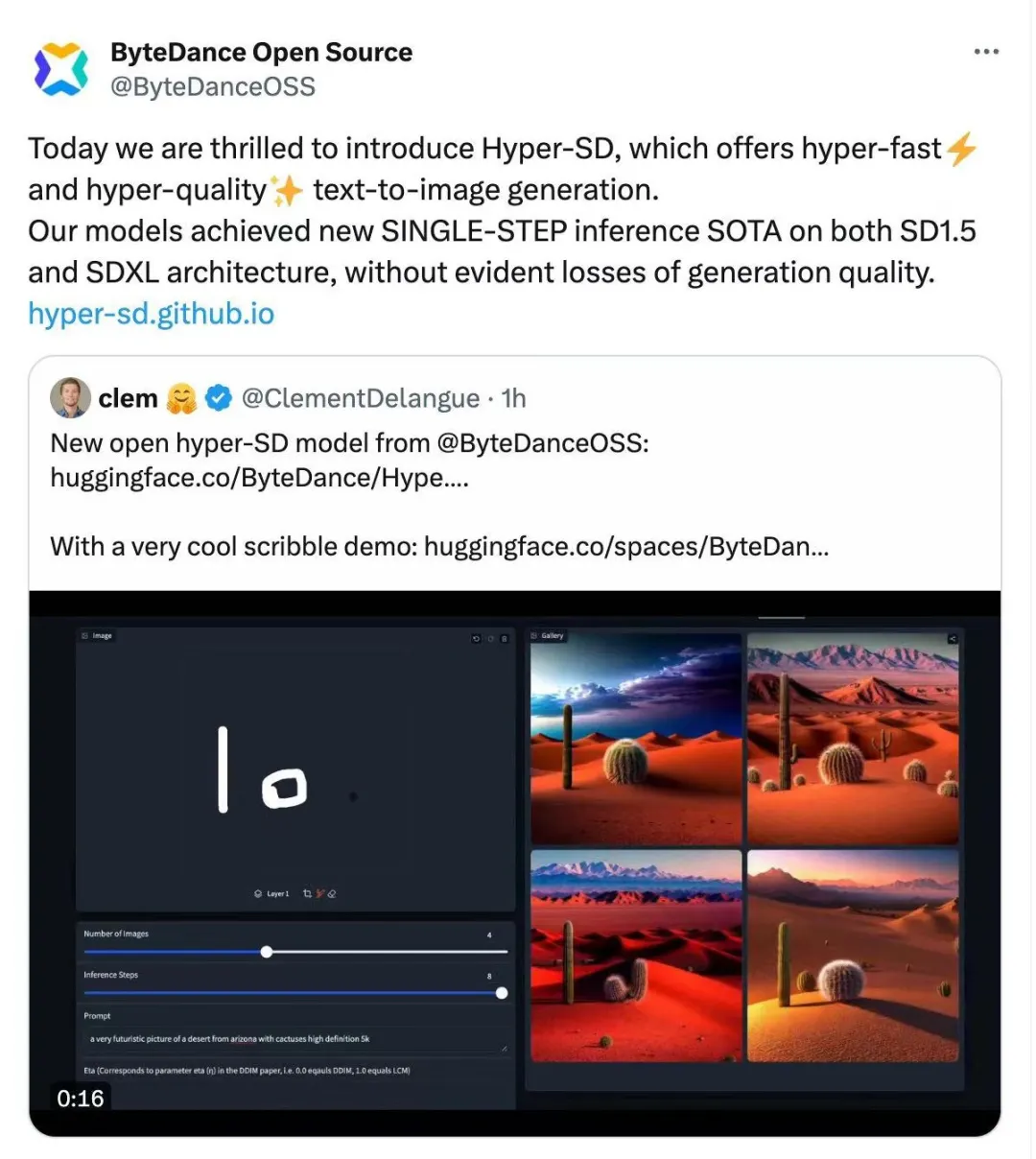
最近,扩散模型(Diffusion Model)在图像生成领域取得了显著的进展,为图像生成和视频生成任务带来了前所未有的发展机遇。尽管取得了令人印象深刻的结果,扩散模型在推理过程中天然存在的多步数迭代去噪特性导致了较高的计算成本。

初见文生图、文生视频的震撼还清晰如同昨日,硬糖君的记忆更停留在AI绘画导致LOFTER用户销号事件——可能是这个冷门社区近年来站得最高的一次。但不到两年时间,AIGC已经随风潜入夜。

2024最wow的AI生图工具出现了! 对“青春纪念手册”下手,你就说这味儿正不正宗:

过去几年里,基于文本来生成图像的扩散模型得到了飞速发展,生成能力有了显著的提升,可以很容易地生成逼真的肖像画,以及各种天马行空的奇幻画作。

去年年底以来,更多人 感受到了 AI 对生活的「入侵」 —— 我们开始在地铁、电梯间和商店看到了 AI 生成的广告图像

在开源社区中把GPT-4+Dall·E 3能⼒整合起来的模型该有多强?

先上代码再发论文,腾讯新开源文生视频工具火了。名为MuseV,主打基于视觉条件并行去噪的无限长度和高保真虚拟人视频生成。

没有谁能一直称王,但加上前缀谁都有称王的机会。AI 文生图,还能玩出什么新花样?在这片群雄割据的红海,头部被 Midjourney、DALL·E、Stable Diffusion 等占据,其余还能让人眼前一亮的产品并不多。然而,仍有黑马杀出:Ideogram,前 Google 工程师创立,硅谷 AI 大神投资,去年 8 月面世,2 月底发布了最新的模型。