
快手进军AI编程!“模型+工具+平台”一口气放三个大招
快手进军AI编程!“模型+工具+平台”一口气放三个大招AI编程领域竞争正酣。就在DeepSeek、阿里、Google、OpenAI等巨头纷纷展示最新代码生成能力之际,快手也交出了一份重量级答卷——发布AI编程产品矩阵,正式宣布进军AI Coding赛道。
来自主题: AI资讯
12476 点击 2025-10-23 16:48
 搜索
搜索
AI编程领域竞争正酣。就在DeepSeek、阿里、Google、OpenAI等巨头纷纷展示最新代码生成能力之际,快手也交出了一份重量级答卷——发布AI编程产品矩阵,正式宣布进军AI Coding赛道。

从C端的小美,到B端的“袋鼠参谋”、“袋鼠管家”和“智能管家”,美团已经作出了一个“AI助手”矩阵。未来,这些AI助手之间如何配合和协作,形成一个新的AI原生生态,充满了想象、但也充满了挑战。
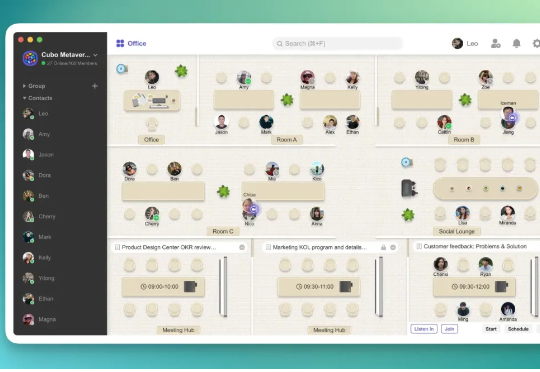
作为一名从移动互联网时代「穿越」而来的连续创业者,他经历过完整的周期起伏。而在 AI 时代,他选择不做具体的品类选手,而是成为一个「赛道服务者」。他创立的矩阵魔方 ( Cubo Group ),在过去一年多里,服务了超过 100 个 AI 产品的全球化营销,其中既有从零崛起的明星项目,也有在 4 个月内实现 ARR 从数百万到 5000 万美金的惊人增长案例。
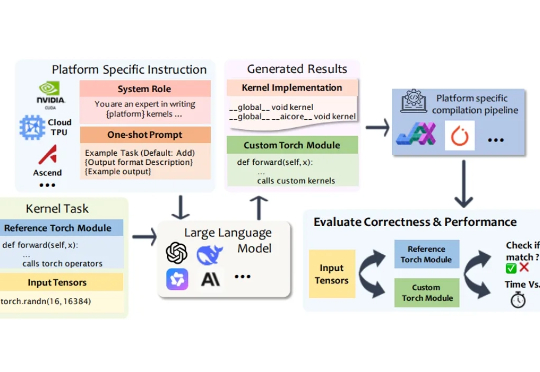
在深度学习模型的推理与训练过程中,绝大部分计算都依赖于底层计算内核(Kernel)来执行。计算内核是运行在硬件加速器(如 GPU、NPU、TPU)上的 “小型高性能程序”,它负责完成矩阵乘法、卷积、归一化等深度学习的核心算子运算。

情感语音交互模型初创公司宇生月伴近日完成新一轮融资,由靖亚资本和小苗朗程领投,菡源资产(上海交大母基金)跟投,心流资本FlowCapital担任长期财务顾问。本轮融资将用于语音模型的持续优化、产品矩阵拓展及国际化商业落地。作为国内首家聚焦“情感语音交互”的模型公司,宇生月伴正重新定义AI时代的语音交互范式。

Vibe Coding(Claude code、Cursor、Lovable) 把原本8周的开发周期压缩成2天 现在,同样20倍的加速在营销圈上演—— Vibe Marketing: 一个人➕n 个AI Agent和自动化工作流,几小时就能把营销想法落地了,杠杆效应大到离谱。
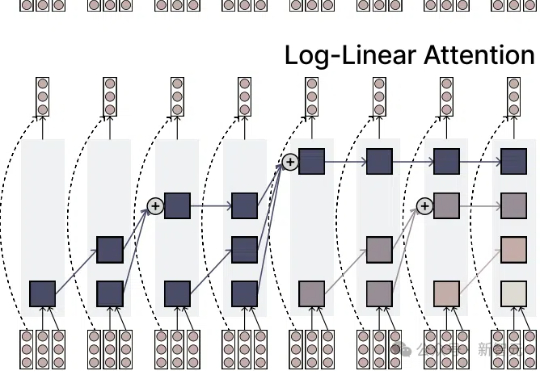
注意力机制的「平方枷锁」,再次被撬开!一招Fenwick树分段,用掩码矩阵,让注意力焕发对数级效率。更厉害的是,它无缝对接线性注意力家族,Mamba-2、DeltaNet 全员提速,跑分全面开花。长序列处理迈入log时代!
该项目在今年1 月进一步扩大,Crusoe 与甲骨文签署了更大规模的租赁协议 ,新增 6 个数据中心,覆盖整个 1.2 吉瓦的场地,The Information 率先报道。该协议使甲骨文能为 OpenAI 提供的算力规模翻了两番,额外增加 30 万块 GPU。最初与 Blue Owl 成立的合资企业并不包含此次扩建计划。

太震撼了,有开发者代码实证后发现,谷歌AlphaEvolve的矩阵乘法突破,被证明为真!Claude辅助下,他成功证明,它果然仅用了48次乘法,就正确完成了4×4矩阵的乘法运算。接下来,可以坐等AlphaEvolve更「奇点」的发现了。
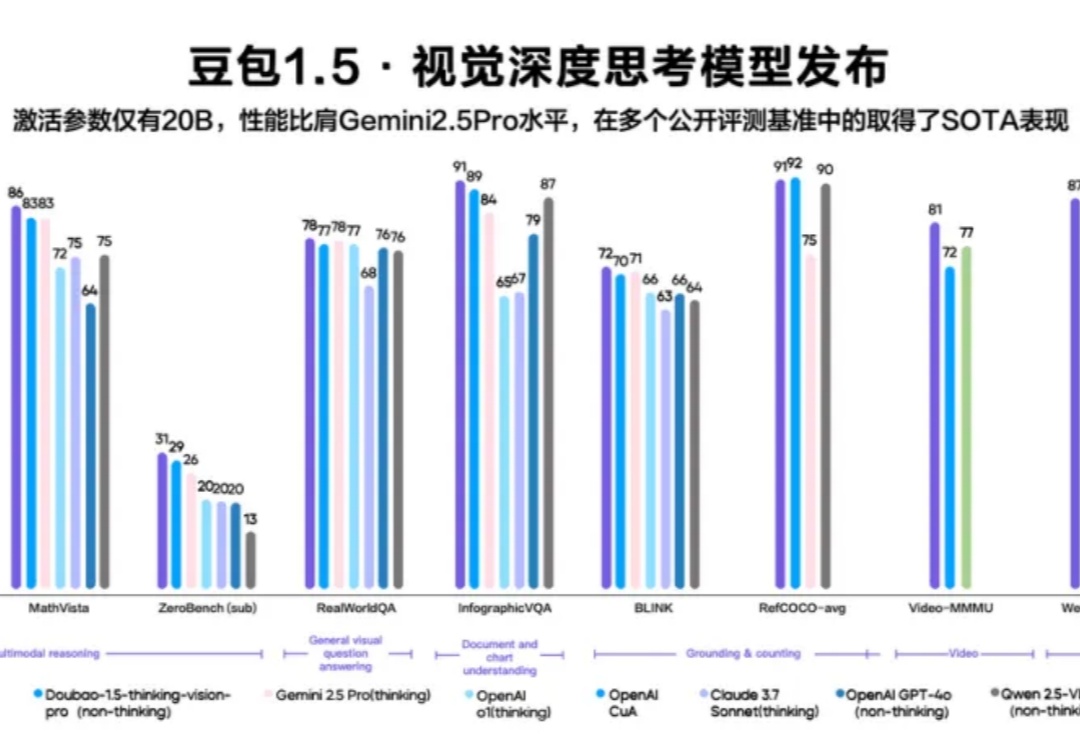
5月13日,在 FORCE LINK AI 创新巡展·上海站,火山引擎发布豆包·视频生成模型 Seedance 1.0 lite、豆包1.5·视觉深度思考模型,升级豆包·音乐模型。同时,Data Agent 正式亮相、Trae 接入豆包深度思考模型并全新升级。火山引擎正在以更强大的模型矩阵、更丰富的智能体工具,帮助企业打通从业务到智能体的应用链路。