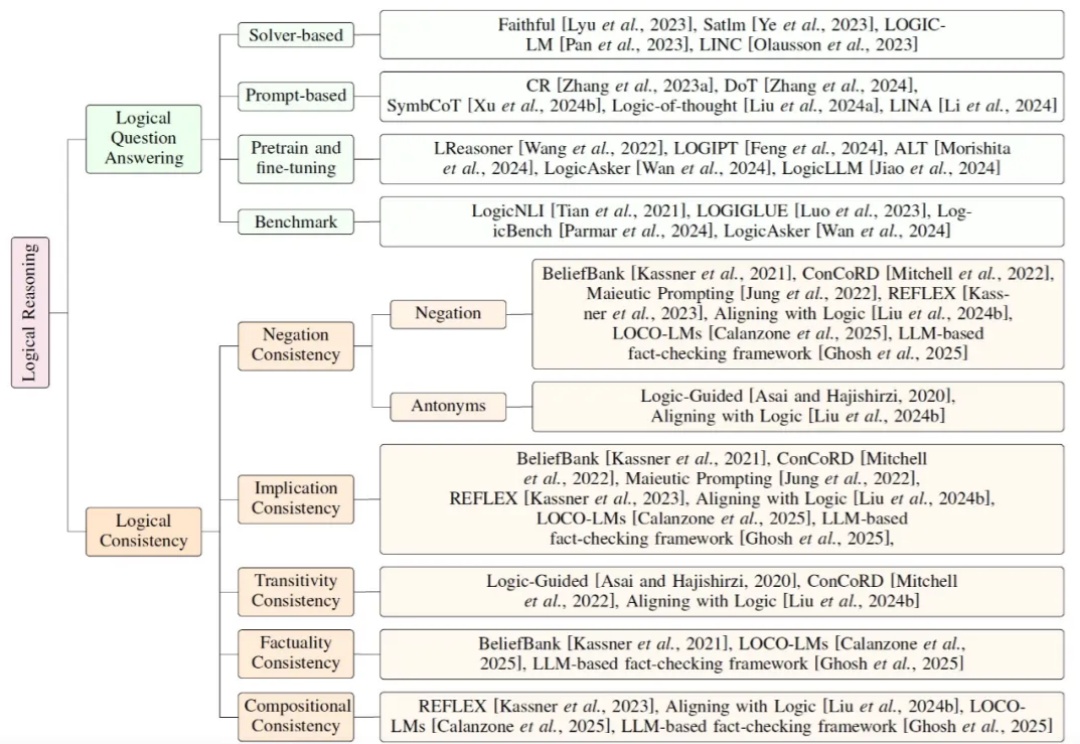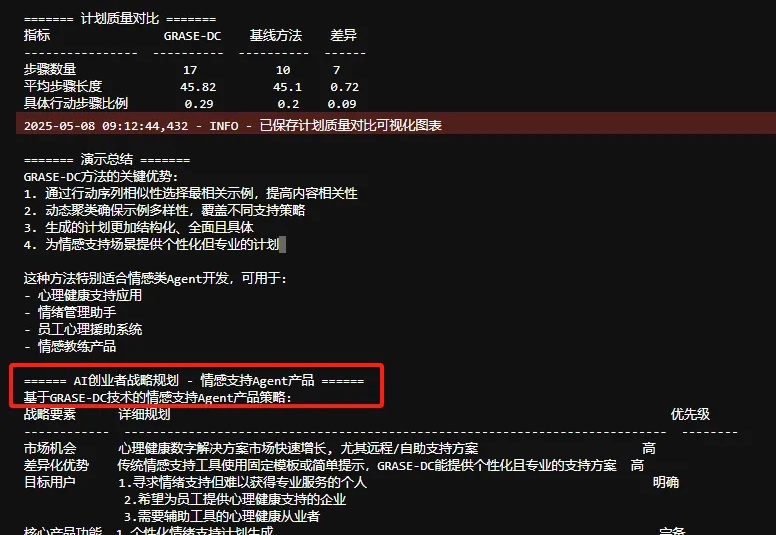
谷歌DeepMind&CMU:过去引导LLM规划的方法是错的? 用GRASE-DC改进。ICLR2025
谷歌DeepMind&CMU:过去引导LLM规划的方法是错的? 用GRASE-DC改进。ICLR2025当您的Agent需要规划多步骤操作以达成目标时,比如游戏策略制定或旅行安排优化等等,传统规划方法往往需要复杂的搜索算法和多轮提示,计算成本高昂且效率不佳。来自Google DeepMind和CMU的研究者提出了一个简单却非常烧脑的问题:我们是否一直在用错误的方式选择示例来引导LLM学习规划?
来自主题: AI技术研报
10853 点击 2025-05-09 11:58