
AI狂欢的背后:算力的能耗,我们该担忧吗? | Nature报道
AI狂欢的背后:算力的能耗,我们该担忧吗? | Nature报道ChatGPT等AI模型爆发式增长引发关键问题:这场AI革命需要消耗多少能源?本文探究数据中心在乡村地区的快速扩张,以弗吉尼亚州为例,揭示研究者如何通过供应链分析和直接测量两种方法估算AI能耗。
来自主题: AI资讯
11927 点击 2025-03-13 15:21
ChatGPT等AI模型爆发式增长引发关键问题:这场AI革命需要消耗多少能源?本文探究数据中心在乡村地区的快速扩张,以弗吉尼亚州为例,揭示研究者如何通过供应链分析和直接测量两种方法估算AI能耗。
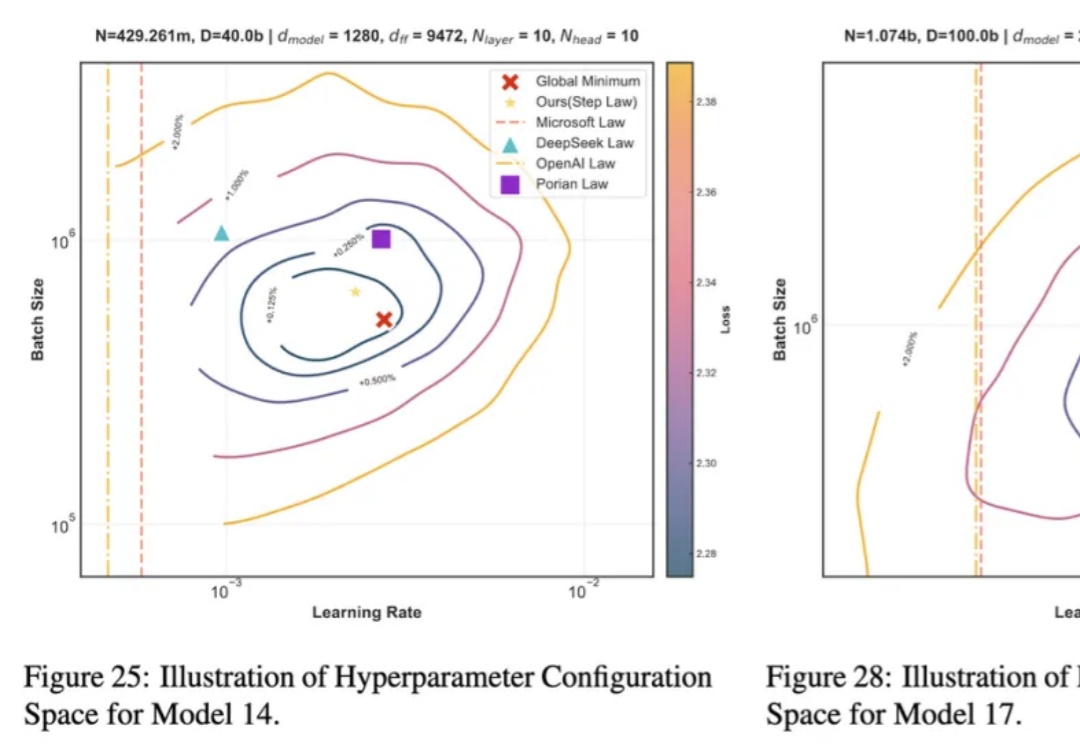
近年来,大语言模型 LLMs 在多种任务上的卓越表现已得到广泛认可。然而,要实现其高效部署,精细的超参数优化至关重要。为了探究最佳超参数的规律,我们开展了大规模的实证研究,通过在不同配置上进行网格搜索,我们揭示了一套通用的最优超参数缩放定律(Optimal Hyperparameter Scaling Law)。

不怕推理模型简单问题过度思考了,能动态调整CoT的新推理范式SCoT来了!

最新研究显示,以超强推理爆红的DeepSeek-R1模型竟藏隐形危险——

近日,记者发现,国内权威医疗大模型评测平台MedBench在官网更新了榜单。多个医疗AI产品及研究团队入榜,其中蚂蚁AI健康管家团队研发的蚂蚁医疗大模型以评测榜单97.5、自测榜单98.2的高分再度夺得双料冠军。

去年的诺贝尔奖梅开二度,两次颁给了AI相关领域,让所有人惊讶于AI4science的潜力。然而近日密西根大学的一项覆盖16万篇文献的大规模研究指出,AI和科学的结合仍存在错位。

近日,北京大学智能学院袁晓如课题组在中国古籍内容的智能探索方面开展跨学科合作探索取得重要进展。研究通过智能自动分类机制,从大量中国古籍中提取可视化图像,建立大规模中国古代可视化集合

如今的前沿推理模型,学会出来的作弊手段可谓五花八门,比如放弃认真写代码,开始费劲心思钻系统漏洞!为此,OpenAI研究者开启了「CoT监控」大法,让它的小伎俩被其他模型戳穿。然而可怕的是,这个方法虽好,却让模型变得更狡猾了……

在32道高等数学测试中,LLM表现出色,平均能得分90.4(按百分制计算)。GPT-4o和Mistral AI更是几乎没错!向量计算、几何分析、积分计算、优化问题等,高等AI模型轻松拿捏。研究发现,再提示(Re-Prompting)对提升准确率至关重要。

o3-mini成功挑战图论中专家级证明,还得到了陶哲轩盛赞。经过实测后,他总结称LLM并非是数学研究万能解法,其价值取决于问题得性质和调教AI的方式。